How PostgreSQL and MySQL Handle No-Op Updates: A Performance Deep Dive
Introduction
No-op updates in SQL—where an UPDATE statement sets columns to their existing values—are rare in well-designed applications. Yet legacy code, third-party plugins, or complex business logic can trigger these operations. Understanding how PostgreSQL and MySQL handle no-op updates is crucial for database architects and performance engineers, as it impacts disk usage, transaction logs, and overall efficiency.
What Is a No-Op Update?
A no-op update occurs when your SQL UPDATE statement doesn’t change any data.
UPDATE customers SET status = 'active' WHERE id = 7;
If customer #7 already has status = ‘active’, this is a no-op update. But what do PostgreSQL and MySQL actually do behind the scenes?
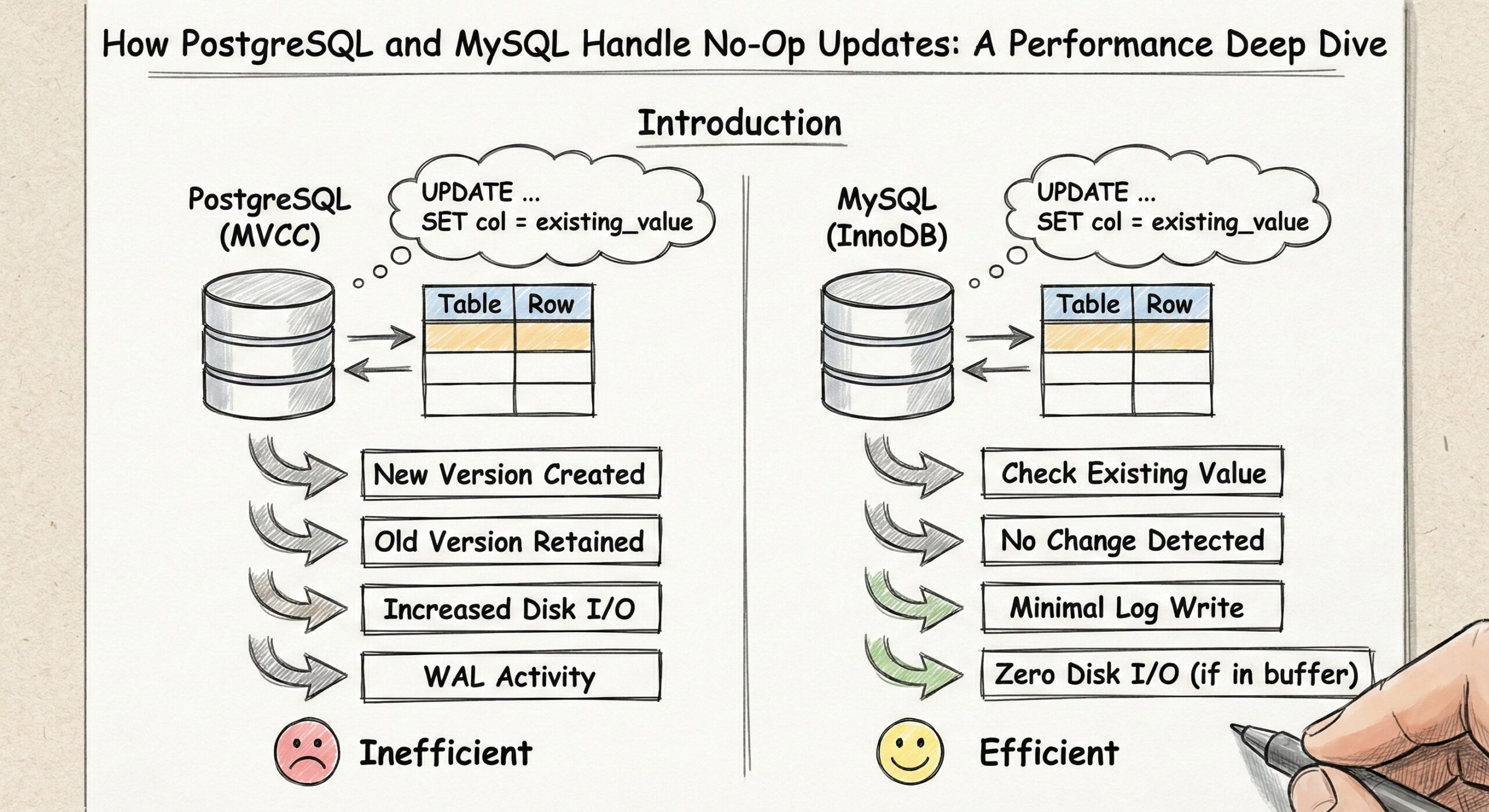
PostgreSQL: MVCC and Row Versions
PostgreSQL uses Multi-Version Concurrency Control (MVCC), which creates a new row version for every UPDATE—including no-op updates. The old row becomes a “dead tuple.”
Example Workflow:
- You insert a row.
- You issue a no-op UPDATE.
- PostgreSQL increments the “dead tuple” count, bloating your storage.
Why It Matters:
Frequent no-op updates can trigger table bloat, requiring regular VACUUM maintenance and impacting query performance.
Pro Tip
Monitor pg_stat_get_live_tuples and pg_stat_get_dead_tuples to track table bloat.
MySQL InnoDB: Smart Change Detection
In contrast, MySQL InnoDB checks whether the data will actually change:
- If the new values match the old, no new row versions are created.
- No entries are added to the undo log, reducing disk I/O and storage use.
UPDATE customers SET status = 'active' WHERE id = 7; -- No change detected, no data modified, no undo log entry created.
Why It Matters:
MySQL’s smart update detection means less disk churn and no unnecessary storage bloat.
Performance Implications
| Feature | PostgreSQL | MySQL InnoDB |
|---|---|---|
| Row Version/Dead Tuple | Created for every update | Only if data actually changes |
| Undo Log Entries | Yes | No for no-op |
| Transaction Log Growth | Higher risk for bloat | More efficient |
| Table Bloat | Possible | Avoided |
| Concurrency | MVCC overhead | Minimal with no-op |
Best Practices for Avoiding No-Op Updates
- Avoid unnecessary updates in application code—use WHERE clauses strategically.
- Run VACUUM regularly on PostgreSQL tables to reduce dead tuple bloat.
- Monitor update patterns to prevent storage and performance bottlenecks.
Conclusion
Seemingly harmless no-op updates can have serious consequences—especially in PostgreSQL. For database architects and DevOps teams, understanding how each system handles these operations helps optimize resources, maintain high performance, and plan maintenance schedules more effectively.
MinervaDB offers expert consulting, support, and managed services to help you prevent table bloat and ensure optimal database performance for PostgreSQL, MySQL, and more.
Let us know if you’d like a deep dive on VACUUM strategies or profiling undo log growth in enterprise workloads!
For more technical insights, follow MinervaDB on LinkedIn, Twitter, and our official blog.
Further Reading:
- Troubleshooting MariaDB Performance
- MariaDB 2025 High Availability Best Practices
- Advanced Database Performance Tuning for MariaDB
- Next-Gen Data Management
- Understanding Database Locking
Expert Database Consulting Services for Modern Enterprise Infrastructure
Our services include MinervaDB Consultative Support to help businesses maximize their database potential.
MinervaDB Inc. delivers comprehensive full-stack database infrastructure engineeringsolutions, specializing in performance optimization, scalability architecture, and enterprise-grade operations management across diverse database ecosystems. Our consultative approach ensures optimal database performance, reliability, and security for mission-critical applications.
Core Database Technologies and Expertise
Relational Database Systems
- PostgreSQL: Advanced query optimization, partitioning strategies, and high-availability clustering
- MySQL: Performance tuning, replication architecture, and InnoDB optimization
- MariaDB: Enterprise deployment, columnstore analytics, and multi-master configurations
NoSQL and Distributed Systems
- MongoDB: Sharding optimization, replica set management, and aggregation pipeline tuning
- Cassandra: Ring topology design, consistency level optimization, and multi-datacenter deployment
- Redis: Memory optimization, clustering strategies, and persistence configuration
- Valkey: High-performance caching, data structure optimization, and failover management
Analytics and Data Warehouse Platforms
- ClickHouse: Real-time analytics optimization, materialized views, and distributed table design
- Trino: Federated query optimization, connector configuration, and resource management
- Milvus: Vector database optimization, index tuning, and similarity search performance
Cloud Database Infrastructure and DBaaS Solutions
Amazon Web Services (AWS)
- Amazon RDS: Multi-AZ deployment, read replica optimization, and automated backup strategies
- Amazon Aurora: Serverless configuration, global database setup, and performance insights
- Amazon Redshift: Data warehouse optimization, distribution key design, and query performance tuning
Microsoft Azure
- Azure SQL Database: Elastic pool management, intelligent performance optimization, and geo-replication
- Azure Synapse Analytics: Data pipeline optimization and distributed query processing
Google Cloud Platform (GCP)
- Google BigQuery: Query optimization, partitioning strategies, and cost management
- Cloud SQL: High availability configuration and performance monitoring
Oracle Cloud Infrastructure
- MySQL HeatWave: In-memory analytics optimization and hybrid workload management
Multi-Cloud and Hybrid Solutions
- Snowflake: Data sharing architecture, virtual warehouse optimization, and cost-effective scaling
- Databricks: Lakehouse architecture, Delta Lake optimization, and MLOps integration


