Understanding Foreign Data Wrappers in PostgreSQL: A Complete Guide to postgres_fdw
In today’s distributed data landscape, organizations often need to access and integrate data from multiple database systems. PostgreSQL Foreign Data Wrappers (FDWs)provide an elegant solution to this challenge, enabling seamless access to external data sources as if they were native PostgreSQL tables. Among the various FDW extensions available, postgres_fdw stands out as the most commonly used wrapper for connecting PostgreSQL databases to other PostgreSQL instances.
This comprehensive guide explores what Foreign Data Wrappers are, how postgres_fdw works, and why it’s essential for modern data integration strategies.
What Are Foreign Data Wrappers?
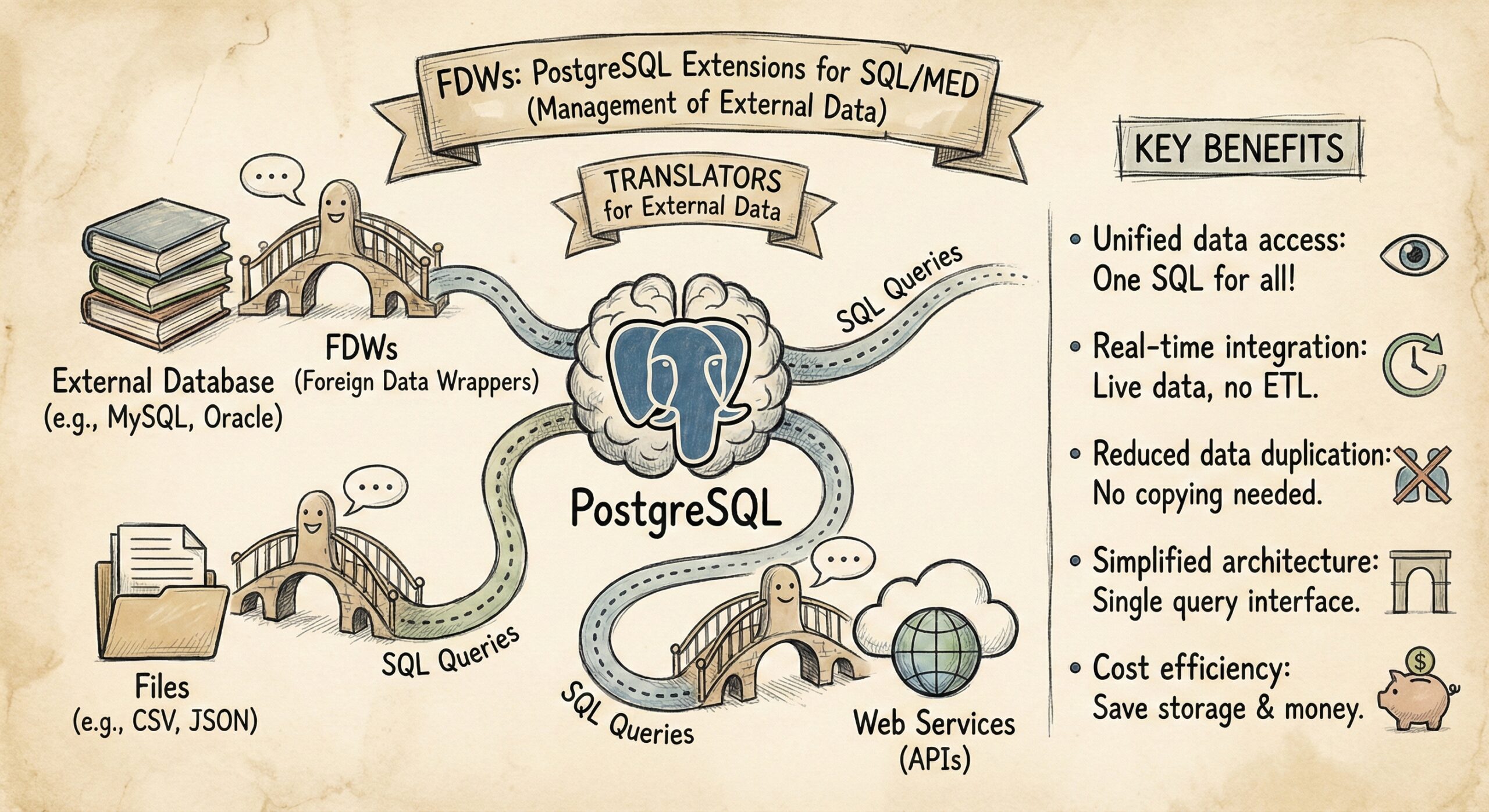
Foreign Data Wrappers are PostgreSQL extensions that implement the SQL/MED (Management of External Data) standard, allowing PostgreSQL to interact with external data sources. Think of FDWs as translators that enable PostgreSQL to communicate with foreign databases, files, or even web services using standard SQL queries.
Key Benefits of FDWs
- Unified data access: Query multiple data sources using a single SQL interface
- Real-time integration: Access live data without ETL processes or data replication
- Reduced data duplication: Eliminate the need to copy data between systems
- Simplified architecture: Maintain a single query interface for heterogeneous data sources
- Cost efficiency: Reduce storage costs by avoiding unnecessary data copies
Understanding postgres_fdw
postgres_fdw is the official Foreign Data Wrapper for connecting one PostgreSQL database to another PostgreSQL database. It’s included in the PostgreSQL contrib package and provides robust, efficient access to remote PostgreSQL servers.
How postgres_fdw Works
When you query a foreign table created with postgres_fdw, the following process occurs:
- PostgreSQL receives your SQL query
- The FDW translates the query for the remote server
- The remote PostgreSQL instance executes the query
- Results are returned to your local database
- Data is presented as if it came from a local table
Key Features
- Push-down optimization: Filters, joins, and aggregations are pushed to the remote server when possible, minimizing data transfer
- Transaction support: Foreign tables can participate in local transactions
- Write operations: Supports INSERT, UPDATE, and DELETE operations on remote tables
- Parallel query execution: Can leverage parallel query capabilities for improved performance
- Connection pooling: Reuses connections efficiently to reduce overhead
Setting Up postgres_fdw: Step-by-Step Guide
Step 1: Install the Extension
First, enable the postgres_fdw extension in your local database:
CREATE EXTENSION postgres_fdw;
Step 2: Create a Foreign Server
Define the remote PostgreSQL server you want to connect to:
CREATE SERVER remote_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'remote-host.example.com',
port '5432',
dbname 'remote_database'
);
Step 3: Create User Mapping
Map your local database user to a remote database user with appropriate credentials:
CREATE USER MAPPING FOR local_user
SERVER remote_server
OPTIONS (
user 'remote_user',
password 'secure_password'
);
Security Note: Consider using .pgpass file or connection service files for more secure credential management in production environments.
Step 4: Create Foreign Tables
Define foreign tables that map to tables on the remote server:
-- Manual table definition
CREATE FOREIGN TABLE remote_customers (
customer_id INT,
customer_name VARCHAR(100),
email VARCHAR(100),
created_at TIMESTAMP
)
SERVER remote_server
OPTIONS (schema_name 'public', table_name 'customers');
Alternatively, import the entire schema automatically:
IMPORT FOREIGN SCHEMA public
FROM SERVER remote_server
INTO local_schema;
Step 5: Query Foreign Tables
Now you can query the foreign table just like any local table:
-- Simple SELECT
SELECT customer_name, email
FROM remote_customers
WHERE created_at > '2024-01-01';
-- JOIN with local tables
SELECT
o.order_id,
o.order_date,
rc.customer_name,
rc.email
FROM local_orders o
JOIN remote_customers rc ON o.customer_id = rc.customer_id
WHERE o.status = 'completed';
-- Aggregations
SELECT
COUNT(*) AS total_customers,
DATE_TRUNC('month', created_at) AS month
FROM remote_customers
GROUP BY month
ORDER BY month DESC;
Practical Use Cases for postgres_fdw
1. Data Consolidation and Reporting
Combine data from multiple PostgreSQL databases for comprehensive reporting without moving data:
-- Consolidate sales data from regional databases
SELECT
'North America' AS region,
SUM(amount) AS total_sales
FROM north_america_sales
UNION ALL
SELECT
'Europe' AS region,
SUM(amount) AS total_sales
FROM europe_sales
UNION ALL
SELECT
'Asia' AS region,
SUM(amount) AS total_sales
FROM asia_sales;
2. Database Sharding
Access sharded databases transparently through a single interface:
-- Query across multiple shards
SELECT customer_id, order_count
FROM (
SELECT customer_id, COUNT(*) AS order_count FROM shard_1_orders GROUP BY customer_id
UNION ALL
SELECT customer_id, COUNT(*) AS order_count FROM shard_2_orders GROUP BY customer_id
UNION ALL
SELECT customer_id, COUNT(*) AS order_count FROM shard_3_orders GROUP BY customer_id
) AS all_orders
GROUP BY customer_id;
3. Microservices Data Integration
Enable microservices to access data from other services’ databases when necessary:
-- Order service accessing customer service data
SELECT
o.order_id,
o.total_amount,
c.customer_name,
c.loyalty_tier
FROM orders o
JOIN customer_service.customers c ON o.customer_id = c.customer_id
WHERE c.loyalty_tier = 'premium';
4. Development and Testing Environments
Access production data from development environments without full data replication:
-- Development database accessing production reference data SELECT * FROM production_server.product_catalog WHERE category = 'electronics' LIMIT 100;
Performance Optimization Tips
1. Leverage Query Push-Down
postgres_fdw automatically pushes compatible operations to the remote server. Ensure your queries take advantage of this:
-- Good: Filter pushed to remote server SELECT * FROM remote_table WHERE status = 'active'; -- Less efficient: Filter applied locally SELECT * FROM remote_table WHERE custom_function(status) = 'active';
2. Use Appropriate Indexes
Create indexes on the remote server for columns frequently used in WHERE clauses and JOIN conditions:
-- On remote server CREATE INDEX idx_customers_email ON customers(email); CREATE INDEX idx_orders_customer_id ON orders(customer_id);
3. Configure Fetch Size
Adjust the fetch size for better performance with large result sets:
ALTER SERVER remote_server
OPTIONS (ADD fetch_size '10000');
4. Use Connection Pooling
Configure connection limits to prevent overwhelming the remote server:
ALTER SERVER remote_server
OPTIONS (ADD extensions 'pg_stat_statements');
5. Monitor Query Performance
Use EXPLAIN ANALYZE to understand query execution:
EXPLAIN (ANALYZE, VERBOSE) SELECT * FROM remote_customers WHERE created_at > '2024-01-01';
Security Considerations
Authentication Best Practices
- Use strong passwords: Never hardcode passwords in SQL scripts
- Implement SSL/TLS: Encrypt connections between servers
- Principle of least privilege: Grant only necessary permissions to remote users
- Regular credential rotation: Update passwords periodically
Secure Connection Configuration
CREATE SERVER secure_remote_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'remote-host.example.com',
port '5432',
dbname 'remote_database',
sslmode 'require',
sslcert '/path/to/client-cert.pem',
sslkey '/path/to/client-key.pem',
sslrootcert '/path/to/root-ca.pem'
);
Network Security
- Use firewalls to restrict database access
- Implement VPNs for cross-datacenter connections
- Monitor connection logs for suspicious activity
- Use connection limits to prevent DoS attacks
Common Challenges and Solutions
Challenge 1: Network Latency
Solution: Minimize data transfer by using selective queries and aggregations on the remote server.
Challenge 2: Transaction Coordination
Solution: Be aware that distributed transactions have limitations. Use two-phase commit when necessary, but consider eventual consistency patterns for better performance.
Challenge 3: Schema Changes
Solution: Implement a process to refresh foreign table definitions when remote schemas change:
-- Drop and recreate foreign tables after schema changes
DROP FOREIGN TABLE IF EXISTS remote_customers;
IMPORT FOREIGN SCHEMA public
LIMIT TO (customers)
FROM SERVER remote_server
INTO public;
Challenge 4: Connection Management
Solution: Configure appropriate connection timeouts and implement retry logic in your application layer.
Alternatives to postgres_fdw
While postgres_fdw is excellent for PostgreSQL-to-PostgreSQL connections, other FDWs exist for different data sources:
- oracle_fdw: Connect to Oracle databases
- mysql_fdw: Access MySQL/MariaDB databases
- mongo_fdw: Query MongoDB collections
- file_fdw: Read CSV and text files
- redis_fdw: Access Redis key-value stores
Conclusion
PostgreSQL Foreign Data Wrappers, particularly postgres_fdw, provide a powerful solution for modern data integration challenges. By enabling seamless access to remote PostgreSQL databases through standard SQL queries, postgres_fdw eliminates the need for complex ETL processes and data duplication while maintaining data consistency and security.
Whether you’re building a microservices architecture, implementing database sharding, consolidating reporting data, or simply need to access data across multiple PostgreSQL instances, postgres_fdw offers a robust, efficient, and maintainable approach to distributed data access.
Key Takeaways
- FDWs enable PostgreSQL to query external data sources as if they were local tables
- postgres_fdw provides optimized access to remote PostgreSQL databases
- Query push-down optimization minimizes network overhead
- Proper indexing and configuration are crucial for optimal performance
- Security considerations are paramount when connecting databases across networks
By understanding and implementing Foreign Data Wrappers effectively, you can build more flexible, scalable, and maintainable database architectures that meet the demands of modern distributed systems.
Ready to implement postgres_fdw? Start with a development environment, test thoroughly, and gradually expand to production use cases. The investment in learning FDWs will pay dividends in simplified data architecture and improved operational efficiency.


