Improving Apache Kafka® Performance and Scalability With Parallel Consumer
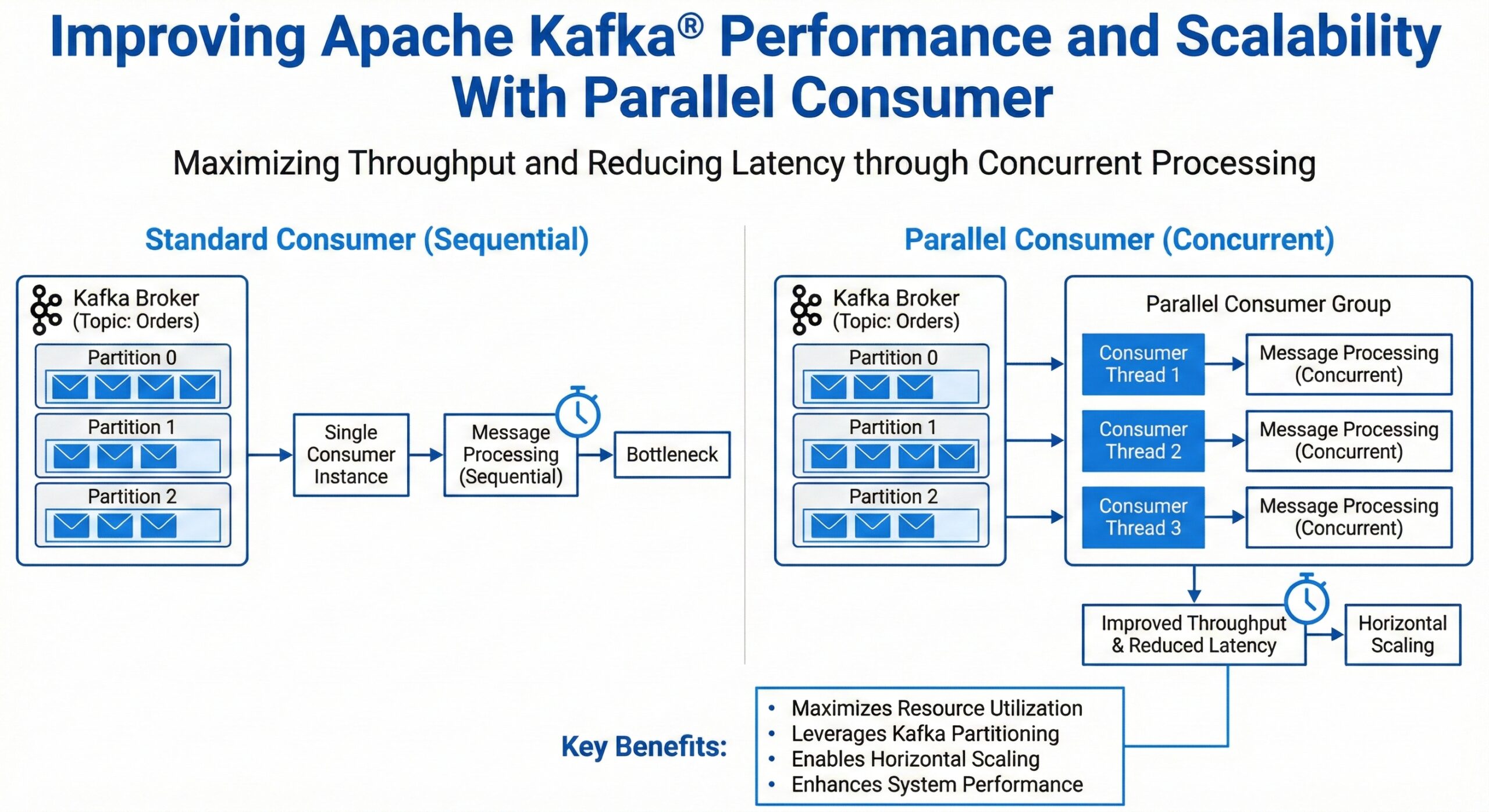
Apache Kafka’s performance and scalability are critical factors for modern data streaming applications. One of the most effective strategies for enhancing throughput and reducing latency is implementing parallel consumption patterns. This approach allows applications to process multiple messages simultaneously, maximizing resource utilization and improving overall system performance.
Understanding Parallel Consumption in Kafka
Parallel consumption involves multiple consumer instances or threads processing messages concurrently from Kafka topics. This pattern leverages Kafka’s partitioning mechanism to distribute workload across multiple processing units, enabling horizontal scaling and improved throughput.
Key Benefits of Parallel Consumption
- Increased Throughput: Multiple consumers can process messages simultaneously
- Reduced Latency: Faster message processing through concurrent execution
- Better Resource Utilization: Optimal use of CPU and memory resources
- Horizontal Scalability: Easy scaling by adding more consumer instances
- Fault Tolerance: Improved resilience through distributed processing
Implementation Strategies
Consumer Group Scaling
The most straightforward approach to parallel consumption is scaling consumer groups:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "parallel-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("max.poll.records", 500);
props.put("fetch.min.bytes", 1024);
// Create multiple consumer instances
ExecutorService executor = Executors.newFixedThreadPool(4);
for (int i = 0; i < 4; i++) {
executor.submit(() -> {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("high-throughput-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
processMessage(record);
}
consumer.commitSync();
}
});
}
Multi-threaded Message Processing
Implement thread-safe message processing within a single consumer:
public class ParallelKafkaConsumer {
private final ExecutorService processingPool;
private final KafkaConsumer<String, String> consumer;
public ParallelKafkaConsumer(int threadPoolSize) {
this.processingPool = Executors.newFixedThreadPool(threadPoolSize);
this.consumer = new KafkaConsumer<>(getConsumerProps());
}
public void consume() {
consumer.subscribe(Arrays.asList("target-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
List<CompletableFuture<Void>> futures = new ArrayList<>();
for (ConsumerRecord<String, String> record : records) {
CompletableFuture<Void> future = CompletableFuture.runAsync(
() -> processMessage(record), processingPool
);
futures.add(future);
}
// Wait for all messages to be processed
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
consumer.commitSync();
}
}
}
Optimization Techniques
Partition Strategy Optimization
Design your partitioning strategy to maximize parallel processing:
// Custom partitioner for balanced distribution
public class BalancedPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
int numPartitions = cluster.partitionCountForTopic(topic);
return Math.abs(key.hashCode()) % numPartitions;
}
}
Consumer Configuration Tuning
Optimize consumer settings for parallel processing:
Properties optimizedProps = new Properties();
optimizedProps.put("bootstrap.servers", "localhost:9092");
optimizedProps.put("group.id", "optimized-parallel-group");
optimizedProps.put("max.poll.records", 1000); // Increase batch size
optimizedProps.put("fetch.min.bytes", 50000); // Larger fetch batches
optimizedProps.put("fetch.max.wait.ms", 500); // Balanced latency
optimizedProps.put("session.timeout.ms", 30000); // Longer session timeout
optimizedProps.put("heartbeat.interval.ms", 10000); // Reduced heartbeat frequency
optimizedProps.put("enable.auto.commit", false); // Manual commit control
Asynchronous Processing Pattern
Implement non-blocking message processing:
public class AsyncParallelConsumer {
private final CompletableFuture<Void>[] processingSlots;
private final AtomicInteger slotIndex = new AtomicInteger(0);
public AsyncParallelConsumer(int parallelism) {
this.processingSlots = new CompletableFuture[parallelism];
Arrays.fill(processingSlots, CompletableFuture.completedFuture(null));
}
public void processAsync(ConsumerRecord<String, String> record) {
int slot = slotIndex.getAndIncrement() % processingSlots.length;
processingSlots[slot] = processingSlots[slot].thenRunAsync(() -> {
try {
processMessage(record);
} catch (Exception e) {
handleProcessingError(record, e);
}
});
}
public void waitForCompletion() {
CompletableFuture.allOf(processingSlots).join();
}
}
Performance Monitoring and Metrics
Key Performance Indicators
Monitor these critical metrics for parallel consumption:
- Consumer Lag: Time delay between message production and consumption
- Throughput: Messages processed per second
- Processing Time: Average time to process individual messages
- Error Rate: Percentage of failed message processing attempts
- Resource Utilization: CPU and memory usage across consumer instances
Monitoring Implementation
public class ConsumerMetrics {
private final MeterRegistry meterRegistry;
private final Timer processingTimer;
private final Counter errorCounter;
public ConsumerMetrics(MeterRegistry registry) {
this.meterRegistry = registry;
this.processingTimer = Timer.builder("kafka.consumer.processing.time")
.register(registry);
this.errorCounter = Counter.builder("kafka.consumer.errors")
.register(registry);
}
public void recordProcessingTime(Duration duration) {
processingTimer.record(duration);
}
public void recordError() {
errorCounter.increment();
}
}
Best Practices for Production Deployment
Resource Planning
- CPU Allocation: Ensure sufficient CPU cores for parallel processing threads
- Memory Management: Configure JVM heap size based on message volume and processing complexity
- Network Bandwidth: Account for increased network traffic from parallel consumers
- Storage I/O: Consider disk performance for offset commits and local processing
Error Handling and Resilience
public class ResilientParallelConsumer {
private final RetryTemplate retryTemplate;
private final DeadLetterQueue dlq;
public void processWithRetry(ConsumerRecord<String, String> record) {
retryTemplate.execute(context -> {
try {
processMessage(record);
return null;
} catch (Exception e) {
if (context.getRetryCount() >= 3) {
dlq.send(record, e);
throw new ExhaustedException("Max retries exceeded", e);
}
throw e;
}
});
}
}
Scaling Considerations
- Partition Count: Ensure partition count matches or exceeds consumer instance count
- Consumer Group Management: Monitor consumer group rebalancing frequency
- Backpressure Handling: Implement mechanisms to handle processing bottlenecks
- Graceful Shutdown: Ensure clean consumer shutdown during deployments
Conclusion
Implementing parallel consumption patterns in Apache Kafka significantly improves performance and scalability for high-throughput applications. By leveraging multiple consumer instances, optimizing configuration settings, and implementing proper monitoring, organizations can achieve substantial improvements in message processing capabilities.
The key to success lies in balancing parallelism with resource constraints, implementing robust error handling, and continuously monitoring performance metrics. With proper implementation, parallel consumption can transform Kafka-based applications into highly efficient, scalable data processing systems capable of handling enterprise-level workloads.
Remember to test thoroughly in staging environments that mirror production conditions, and gradually increase parallelism while monitoring system behavior to find the optimal configuration for your specific use case.
Further Reading:
- Introduction to the VACUUM Command: Essential PostgreSQL Database Maintenance
- What is a Vector Database? A Complete Guide to Modern Data Storage
- Unlocking Growth in CPG: How Data Analytics Transforms Consumer Packaged Goods Decision-Making
- The Complete Guide to MongoDB Replica Sets: Understanding Database Replication Architecture
- Mastering MongoDB Sorting: Arrays, Embedded Documents & Collation
- Kafka Configuration Tuning