PostgreSQL Indexing Myths – Just because you’re getting an index scan in PostgreSQL, doesn’t mean you can’t do better!
Understanding Index Scans: The Starting Point, Not the Destination
When you see that your PostgreSQL query is using an index scan, it’s natural to feel a sense of accomplishment. After all, you’ve moved beyond the dreaded sequential scan that examines every row in a table. An index scan represents progress in query optimization—it means PostgreSQL is using an index structure to locate the data you need, rather than scanning the entire table .
However, experienced database professionals know that an index scan is merely the beginning of the optimization journey, not its conclusion. Just because PostgreSQL is using an index doesn’t mean it’s using the index optimally, or that you’ve selected the most appropriate index strategy for your workload.
The Spectrum of Index Operations
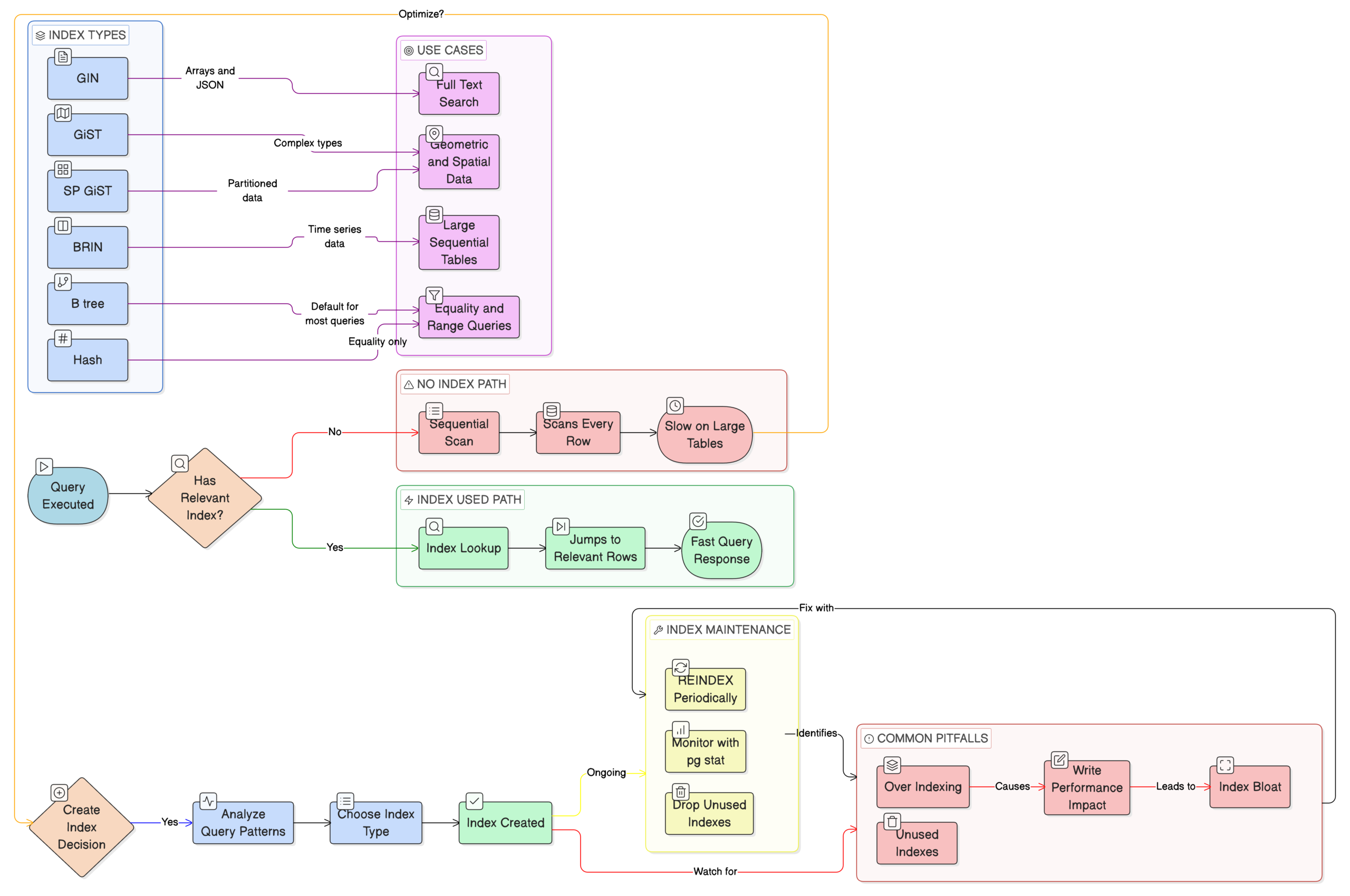
PostgreSQL offers several types of index access methods, each with different performance characteristics:
- Sequential Scan: Reads every row in the table
- Index Scan: Uses an index to find rows, but may still require heap (table) lookups
- Index-Only Scan: Retrieves all needed data directly from the index, avoiding heap lookups entirely
- Bitmap Index Scan: Combines results from multiple indexes using bitmap operations
The presence of an index scan in your query plan indicates that PostgreSQL has identified an index that can help narrow down the search space, but it may still be performing additional work that could be eliminated with better index design.
Why Index Scans Aren’t Always Optimal
The Hidden Cost of Heap Lookups
The primary limitation of a standard index scan is that it typically requires heap lookups. When PostgreSQL uses an index to find qualifying rows, it first retrieves the tuple identifiers (TIDs) from the index, then uses these TIDs to fetch the actual row data from the table (heap). This two-step process introduces additional I/O overhead.
Consider a query like:
SELECT name, email, phone FROM customers WHERE status = 'active';
If you have an index on status alone, PostgreSQL will use an index scan to find all active customers, but then must perform a heap lookup for each matching row to retrieve the name, email, and phone columns. If thousands of customers are active, this results in thousands of random I/O operations to fetch the row data.
Index-Only Scans: Eliminating the Heap Lookup Penalty
PostgreSQL 9.2 introduced index-only scans, which can dramatically improve performance by eliminating heap lookups entirely. For an index-only scan to be possible, the index must contain all the columns referenced in the query (either in the SELECT list or WHERE clause), and the table must be sufficiently vacuumed so that the visibility map is accurate.
To convert our previous example to use an index-only scan, we could create a covering index:
CREATE INDEX idx_customers_active_contact ON customers (status) INCLUDE (name, email, phone);
Or, if these are frequently accessed together:
CREATE INDEX idx_customers_active_covering ON customers (status, name, email, phone);
Now PostgreSQL can satisfy the entire query from the index alone, transforming our index scan into an index-only scan and eliminating the costly heap lookups.
Advanced Indexing Strategies for Better Performance
Partial Indexes: Indexing Only What You Need
Many queries filter on specific subsets of data. Instead of indexing entire columns, partial indexes allow you to index only the rows that matter for particular queries.
For example, if most of your queries focus on active customers, creating a partial index can be much more efficient:
CREATE INDEX idx_customers_active_only ON customers (email) WHERE status = 'active';
This index is smaller, faster to maintain, and more likely to stay in memory. It also improves write performance since only inserts/updates of active customers need to update this index.
Expression Indexes: Indexing Computed Values
Sometimes your queries filter on expressions rather than raw column values. Expression indexes allow you to index the result of a function or expression.
-- For case-insensitive searches
CREATE INDEX idx_customers_email_lower ON customers (LOWER(email));
-- For date truncation
CREATE INDEX idx_orders_month ON orders (date_trunc('month', order_date));
With the first index, a query like SELECT * FROM customers WHERE LOWER(email) = ‘user@example.com’ can use an index scan instead of a sequential scan with function evaluation on every row.
Multicolumn Indexes: Order Matters
When creating indexes on multiple columns, the order of columns significantly impacts performance. The general rule is to place the most selective column first, but this isn’t always optimal.
Consider a query:
SELECT * FROM orders WHERE customer_id = 123 AND status = 'shipped' AND order_date > '2024-01-01';
A naive approach might create: CREATE INDEX idx_orders_naive ON orders (customer_id, status, order_date);
However, if you have customers with orders in multiple statuses, but most queries are for recent shipped orders, you might benefit more from: CREATE INDEX idx_orders_optimized ON orders (customer_id, order_date, status);
This allows PostgreSQL to quickly narrow down to a customer’s recent orders, then filter by status among a much smaller set of rows.
Index Bloat and Maintenance
Identifying Index Bloat
Over time, indexes can become bloated due to UPDATE and DELETE operations, leading to inefficient use of space and poorer performance. You can check for index bloat using queries like:
SELECT
schemaname,
tablename,
indexname,
pg_size_pretty(pg_relation_size(schemaname || '.' || indexname)) as index_size,
bloat_ratio
FROM (
SELECT
schemaname,
tablename,
indexname,
(100 * (current_index_bytes - ideal_index_bytes) / current_index_bytes) as bloat_ratio
FROM (
-- Bloat calculation logic
) bloat
WHERE current_index_bytes > 10000000 -- Only consider indexes > 10MB
) bloat_summary
WHERE bloat_ratio > 30 -- More than 30% bloat
ORDER BY bloat_ratio DESC;
Rebuilding and Reorganizing Indexes
For severely bloated indexes, rebuilding can restore performance:
-- Rebuild index (holds exclusive lock) REINDEX INDEX idx_name; -- Concurrent rebuild (available in PostgreSQL 9.2+) REINDEX INDEX CONCURRENTLY idx_name;
The concurrent option allows the index to remain available for reads during the rebuild, though it takes longer and uses more resources.
Query Plan Analysis: Seeing Beyond the Index Scan
Reading EXPLAIN Output Effectively
When analyzing query plans, look beyond the mere presence of an index scan. Key metrics to examine include:
- Rows removed by filter: Indicates how selective your index is
- Heap fetches: Shows the number of heap lookups performed
- Actual loops: For nested loop joins, indicates how many times the index scan was executed
- Buffers: Shows I/O activity (shared hit, read, etc.)
EXPLAIN (ANALYZE, BUFFERS) SELECT name, email FROM customers WHERE status = 'active';
Using pg_stat_user_indexes for Real-World Insights
PostgreSQL’s statistics views provide valuable information about index usage:
SELECT
schemaname,
tablename,
indexname,
idx_scan as index_scans,
idx_tup_read as tuples_read,
idx_tup_fetch as tuples_fetched
FROM pg_stat_user_indexes
ORDER BY idx_scan ASC; -- Find unused indexes
Indexes with zero or very low scan counts might be candidates for removal, reducing maintenance overhead.
Advanced Optimization Techniques
Index-Only Scan Optimization
To maximize index-only scan opportunities:
- VACUUM frequently: The visibility map must be up-to-date
- Consider fillfactor: For tables with frequent updates, a lower fillfactor (e.g., 80) leaves space for updates without row movement
- Use INCLUDE clause: Add frequently accessed columns to indexes without affecting the index’s sorting
-- Add frequently accessed columns without changing sort order CREATE INDEX idx_transactions_user_covering ON transactions (user_id) INCLUDE (amount, transaction_date, description);
Multi-Index Strategies and Bitmap Scans
For queries with multiple filter conditions, PostgreSQL can combine multiple indexes using bitmap operations:
-- Individual indexes CREATE INDEX idx_orders_customer ON orders (customer_id); CREATE INDEX idx_orders_status ON orders (status); CREATE INDEX idx_orders_date ON orders (order_date);
For a query filtering on all three columns, PostgreSQL might use a bitmap index scan that combines the results from all three indexes, which can be more efficient than a single multicolumn index, especially when the individual filters are highly selective.
Partitioning and Indexing
For very large tables, partitioning can dramatically improve query performance. Each partition can have its own indexes, and queries that can be limited to specific partitions avoid scanning irrelevant data entirely.
-- Partitioned table
CREATE TABLE sales (
sale_id BIGSERIAL,
sale_date DATE NOT NULL,
amount DECIMAL(10,2),
region VARCHAR(50)
) PARTITION BY RANGE (sale_date);
-- Create partition
CREATE TABLE sales_2024 PARTITION OF sales
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
-- Index on partition
CREATE INDEX idx_sales_2024_region ON sales_2024 (region);
Monitoring and Continuous Improvement
Setting Up Index Performance Monitoring
Create regular monitoring queries to identify optimization opportunities:
-- Long-running queries with index scans
SELECT
query,
calls,
mean_time,
rows
FROM pg_stat_statements
WHERE query LIKE '%INDEX SCAN%'
ORDER BY mean_time DESC
LIMIT 10;
The Index Optimization Cycle
Effective index management follows a continuous cycle:
- Monitor: Track query performance and index usage
- Analyze: Identify slow queries and inefficient index usage
- Optimize: Create, modify, or remove indexes
- Test: Validate improvements in a staging environment
- Deploy: Implement changes with appropriate change management
- Repeat: Continuously monitor and improve
Conclusion: Beyond the Index Scan
An index scan in PostgreSQL is a positive sign that your query optimization efforts are moving in the right direction. However, it should be viewed as a starting point rather than a destination. True query optimization involves understanding the nuances of different index access methods, recognizing the hidden costs of heap lookups, and applying advanced indexing strategies tailored to your specific workload.
By focusing on index-only scans, partial indexes, expression indexes, and proper index maintenance, you can transform merely “indexed” queries into truly optimized operations that deliver maximum performance with minimal resource consumption. Remember that index optimization is an ongoing process—not a one-time task—and requires continuous monitoring and refinement to keep your PostgreSQL databases running at peak efficiency.
The next time you see an index scan in your query plan, don’t celebrate too soon. Ask yourself: Can I do better? The answer is almost always yes.
Further Reading


