Introduction: The Strategic Shift from Oracle to PostgreSQL
The “Why”: Drivers of Modernization
The enterprise database landscape is undergoing a seismic shift. For decades, Oracle Database has been a cornerstone of corporate data infrastructure, renowned for its power and reliability. However, a powerful current is pulling organizations towards open-source alternatives, with PostgreSQL emerging as the leading contender. Based on our experience at MinervaDB, a significant majority of enterprises are actively exploring alternatives to proprietary database systems, and PostgreSQL has consistently been one of the fastest-growing database platforms in recent years.
This migration trend is not merely a tactical decision but a strategic imperative driven by a confluence of powerful factors:
- Significant Cost Reduction: The most immediate and compelling driver is the elimination of prohibitive licensing and support fees associated with Oracle. Oracle’s per-core pricing for its Enterprise Edition can be substantial, with additional costs for essential features. Annual support fees typically add another significant percentage of the license cost. In contrast, PostgreSQL is open-source and free to use, allowing organizations to reallocate budget from licensing to innovation, infrastructure, and talent.
- Freedom from Vendor Lock-In: Oracle’s proprietary nature creates a deep-seated dependency, often referred to as “vendor lock-in.” This can limit an organization’s architectural choices and negotiating power. Migrating to PostgreSQL, with its open-source license, grants the freedom to deploy on any infrastructure—on-premises, any public cloud, or in hybrid environments—without punitive licensing constraints.
- Enhanced Flexibility and Customizability: PostgreSQL boasts a vibrant and innovative ecosystem of extensions. This allows developers to add powerful functionalities directly to the database, often for free. Notable examples include PostGIS for advanced geospatial data, TimescaleDB for time-series workloads, and a vast array of Foreign Data Wrappers (FDWs) for data federation. This extensibility stands in stark contrast to Oracle, where similar features are often expensive, proprietary add-ons.
- Alignment with Modern Architectures: PostgreSQL is inherently well-suited for modern, cloud-native development paradigms. It is container-friendly, integrates seamlessly with Kubernetes operators, and fits naturally into microservices and DevOps workflows. Its rapid, community-driven innovation cycle ensures it stays at the forefront of technological advancements, making it a future-proof choice for digital transformation initiatives.
Setting Expectations: A Complex but Rewarding Journey
While the benefits are clear, it is crucial for decision-makers—Database Administrators (DBAs), software developers, and solution architects—to understand that migrating from Oracle to PostgreSQL is far more than a simple “lift and shift” operation. It is a complex modernization project that touches nearly every layer of the technology stack. The journey involves meticulous planning, deep technical conversion, strategic data transfer, significant application rework, and rigorous post-migration optimization.
Migrating from Oracle to PostgreSQL is not just about copying data; it involves transforming schemas, rewriting procedural code, and ensuring performance. It is a challenging and time-consuming process due to heterogeneous structure and data types. — MinervaDB
The Core Challenges: Deconstructing Migration Complexity
The path from Oracle to PostgreSQL is paved with technical nuances and strategic hurdles. A successful migration hinges on a deep understanding of these challenges, which extend far beyond a surface-level data transfer. This section dissects the primary obstacles across four critical domains: technical incompatibilities, data migration logistics, application rework, and the often-overlooked financial realities.
Technical Incompatibilities: Beyond the Surface
The most profound challenges arise from the fundamental differences in how Oracle and PostgreSQL are designed and operate. These are not mere syntax variations but deep-seated architectural and functional disparities that require careful analysis and conversion.
SQL Dialects & Procedural Logic
While both databases use SQL, their procedural language extensions—Oracle’s PL/SQL and PostgreSQL’s PL/pgSQL—are distinct dialects with significant differences that form the crux of the conversion effort.
- PL/SQL vs. PL/pgSQL: Although PL/pgSQL was designed to be similar to PL/SQL, critical differences exist. Both are block-structured, imperative languages with similar control statements (IF, LOOP), but the implementation details vary. For instance, exception handling in PL/pgSQL uses a single EXCEPTION WHEN OTHERS block for general errors, whereas PL/SQL has a more granular system with named exceptions like NO_DATA_FOUND. Perhaps the most significant difference is Oracle’s concept of “packages”—collections of related procedures, functions, and variables—which has no direct equivalent in PostgreSQL. This functionality must be emulated, often by grouping functions within a specific schema and using session variables to mimic package state.
- Function and Syntax Gaps: Many of Oracle’s proprietary functions and SQL syntax constructs require manual workarounds or translation. A migration team must be proficient in these conversions:
- DECODE(): Oracle’s compact conditional function must be rewritten using the standard SQL CASE statement. A subtle but critical difference is how they handle NULL values. DECODE(x, NULL, ‘is_null’, ‘not_null’) will return ‘is_null’ if x is NULL, whereas CASE x WHEN NULL THEN ‘is_null’ ELSE ‘not_null’ END will return ‘not_null’ because NULL is not equal to NULL in standard SQL.
- NVL(arg1, arg2): This function, which returns the second argument if the first is null, is directly replaced by the ANSI SQL standard function COALESCE(arg1, arg2, …), which is supported by both databases.
- SYSDATE: Oracle’s function for the current server time is replaced by PostgreSQL’s NOW() or CURRENT_TIMESTAMP.
- ROWNUM: This pseudocolumn, which assigns a number to rows as they are retrieved (before sorting), is one of the trickiest features to migrate. The modern and more reliable equivalent in PostgreSQL is the ROW_NUMBER() OVER (ORDER BY …) window function, which provides deterministic numbering after sorting.
- CONNECT BY: Oracle’s syntax for hierarchical queries must be converted to Recursive Common Table Expressions (CTEs) using WITH RECURSIVE in PostgreSQL.
- MERGE: The powerful MERGE statement (for “UPSERT” logic) is replaced by PostgreSQL’s INSERT … ON CONFLICT (target) DO UPDATE SET … syntax, which achieves the same outcome.
- FROM DUAL: Oracle requires a FROM clause for all SELECT statements, leading to the use of the dummy table DUAL (e.g., SELECT sysdate FROM dual). In PostgreSQL, the FROM clause is optional for such queries, so SELECT now() is sufficient and the FROM DUAL clause should be removed.
Data Type Mapping: The Devil in the Details
Incorrect data type mapping is a common source of subtle bugs, data corruption, and performance degradation. While many types have direct equivalents, several key Oracle types require careful consideration.
- NUMBER: This is arguably the most problematic type. Oracle’s single, highly versatile NUMBER type can store everything from small integers to high-precision fixed-point and floating-point values. In PostgreSQL, this maps to several distinct types. A NUMBER(5,0) in Oracle should become an INTEGER or SMALLINT in PostgreSQL, while a NUMBER(12,0) might require a BIGINT. A NUMBER(10,2) maps to NUMERIC(10,2) or DECIMAL(10,2). A plain NUMBER with no precision or scale should be mapped to NUMERIC. Choosing the wrong type (e.g., using NUMERIC for everything) can lead to significant performance overhead compared to using native CPU types like INTEGER. A thorough analysis of the source schema’s precision and scale definitions is mandatory.
- VARCHAR2 vs. VARCHAR/TEXT: A key difference is Oracle’s ability to define length semantics as either bytes (VARCHAR2(20 BYTE)) or characters (VARCHAR2(20 CHAR)). PostgreSQL simplifies this by always measuring length in characters for its VARCHAR(n) and TEXT types. This distinction is crucial when dealing with multi-byte character sets, as a direct mapping without considering the semantics can lead to data truncation errors.
- DATE: In Oracle, the DATE data type stores both date and time components. In PostgreSQL, DATE stores only the date. Therefore, Oracle’s DATE type must almost always be mapped to PostgreSQL’s TIMESTAMP or TIMESTAMPTZ (timestamp with time zone) to avoid silent loss of time information.
- User-Defined Types (UDT) & XMLTYPE: Migrating complex types presents a significant challenge. Oracle UDTs can contain member functions (methods), a feature PostgreSQL UDTs lack. This logic must be extracted and reimplemented as separate PostgreSQL functions. Similarly, Oracle’s XMLTYPE may need to be converted to PostgreSQL’s standard XML type or, increasingly, to the more flexible and performant JSONB type if the data structure allows.
Architectural Differences: From RAC to Replication
The high-availability (HA) and scalability models of the two databases are fundamentally different, and failing to account for this can lead to post-migration performance bottlenecks and availability issues.
- High Availability: Oracle’s premier HA solution is Real Application Clusters (RAC), an active-active, shared-disk architecture where multiple instances on different servers access the same database simultaneously. This provides both high availability and scalability for read/write workloads. PostgreSQL’s native HA model is typically based on streaming replication, which is an active-passive (or hot standby) architecture. A primary server handles all write operations, which are then replicated to one or more standby servers that can handle read-only queries and are ready for a fast failover.
- Migration Pitfall: A common and dangerous mistake is to migrate a multi-application workload from a single Oracle RAC cluster to a single, large PostgreSQL instance. In RAC, the cluster load-balances the different applications across its nodes. In PostgreSQL, stacking multiple heavy, unrelated applications onto one instance creates contention for shared resources like CPU and memory (specifically, shared_buffers). As the number of active, concurrent transactions from all applications exceeds the CPU core count, performance degrades rapidly. The recommended approach is often to re-architect, migrating each major application to its own dedicated PostgreSQL instance to maintain resource isolation, mirroring the logical separation that RAC provided.
Data Migration: The Heart of the Operation
Moving terabytes of business-critical data from one system to another is a high-stakes operation where downtime and data integrity are paramount concerns.
The Downtime Dilemma
The choice of migration strategy is dictated almost entirely by the business’s tolerance for application downtime.
- Big Bang Migration: This traditional approach involves stopping the application, performing a full export of the Oracle database, importing the data into PostgreSQL, and then restarting the application against the new database. While simple and straightforward, this method is only viable for small databases or non-critical systems where an extended downtime window (hours or even days) is acceptable.
- Phased / CDC-Based Migration: For most enterprise systems that require 24/7 availability, a “big bang” is not an option. The modern solution is a phased migration that leverages Change Data Capture (CDC) to achieve near-zero downtime. This approach is more complex but dramatically reduces business disruption.
Change Data Capture (CDC): The Key to Near-Zero Downtime
CDC is the technology that enables live, minimally disruptive migrations. It is a process that identifies and captures data changes (INSERTs, UPDATEs, DELETEs) as they happen on the source database and delivers them in real-time to the target system.
- How it Works: Most robust CDC tools for Oracle work by reading the database’s transaction logs (known as Redo Logs). This method has a very low performance overhead on the source system compared to older, trigger-based approaches.
- Typical Workflow: The process involves two main stages:
- Initial Bulk Load: A full snapshot of the source database is taken and loaded into the target PostgreSQL database. While this is happening, the CDC process is already running, capturing all new transactions that occur on the Oracle source.
- Continuous Synchronization: After the initial load is complete, the CDC tool applies the stream of captured changes to the PostgreSQL target, bringing it into sync with the source. This replication continues, keeping the two databases aligned. This allows the team to perform extensive testing on the PostgreSQL target while the live application continues to run on Oracle. The final cutover is then a quick, controlled process.
Ensuring Data Integrity and Validation
A migration is only successful if the data in the new database is a perfect, consistent replica of the source. It is vital to have a robust validation strategy. This is not an optional step. Techniques include running automated scripts to compare row counts for all tables, performing checksums on key data columns, and, most importantly, conducting thorough application-level functional testing to ensure that business processes execute correctly and produce the expected results with the migrated data.
Application Rework: The Hidden Iceberg
While DBAs focus on the database, developers face the daunting task of refactoring application code to work with the new backend. This effort is often the largest and most underestimated component of a migration project.
Code-Level Refactoring
Changes are required at multiple levels of the application stack. For example, in a typical Java application:
- Database Drivers: The application’s connection configuration must be updated to use the PostgreSQL JDBC driver instead of the Oracle JDBC driver.
- SQL Query Modification: All embedded SQL queries must be reviewed and modified to conform to PostgreSQL’s SQL dialect. This includes translating Oracle-specific functions (like DECODE) and syntax (like outer join `(+)` syntax in older code) as detailed previously.
- Exception Handling: Application code that catches and handles specific Oracle exceptions (e.g., by checking for ORA-xxxxx error codes) must be rewritten. The code should be adapted to catch either generic, cross-database SQL exceptions or, where necessary, PostgreSQL-specific exception codes.
Frameworks and ORMs
Using an Object-Relational Mapping (ORM) framework like Hibernate or JPA can significantly ease the migration. In many cases, the transition can be as simple as changing the “dialect” configuration from Oracle to PostgreSQL in the application’s settings. The ORM handles the generation of dialect-specific SQL for standard CRUD operations. However, this is not a silver bullet. Any application that uses native SQL queries, calls stored procedures directly, or relies on Oracle-specific database features will bypass the ORM’s abstraction layer and require manual code review and refactoring.
The “Hidden” Costs: A Realistic TCO Analysis
A migration decision based solely on eliminating Oracle license fees presents an incomplete and dangerously optimistic picture. A realistic Total Cost of Ownership (TCO) analysis must account for the substantial one-time and ongoing costs of the migration project itself. Our analysis of enterprise migrations reveals that these “hidden” costs often dwarf the initial software savings.
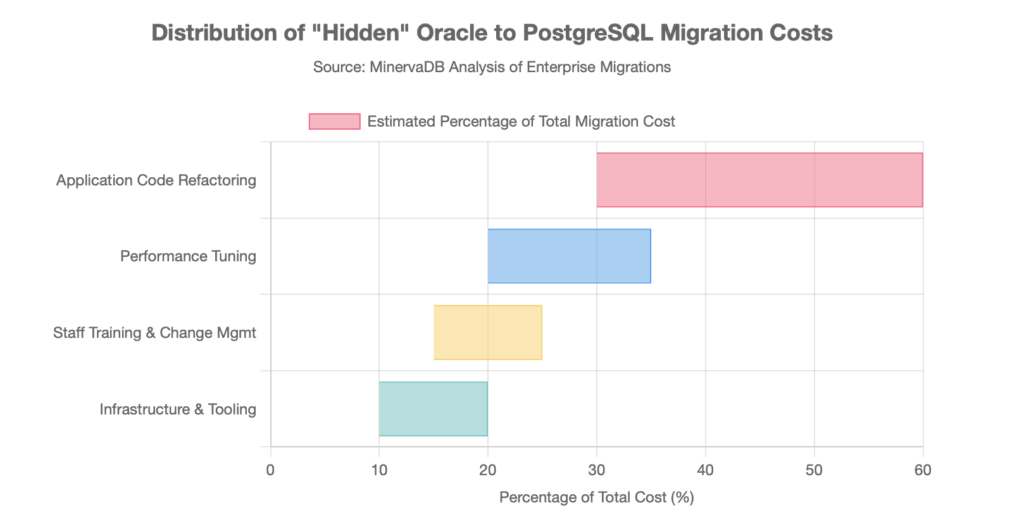
- Application Code Refactoring (30-60% of total cost): This is typically the largest single expense. The manual effort required to translate PL/SQL to PL/pgSQL is significant. Our estimates suggest an effort of 40-80 hours per 1,000 lines of PL/SQL code. For a system with hundreds of thousands of lines of PL/SQL, this can translate into a substantial cost for code refactoring alone, often representing nearly half the total migration budget.
- Performance Optimization & Tuning (20-35% of cost): Oracle provides many sophisticated, auto-tuning features that DBAs may take for granted. PostgreSQL, while highly tunable, requires more manual intervention. Post-migration, a significant amount of time must be dedicated to tuning PostgreSQL’s configuration parameters (like shared_buffers and work_mem), redesigning indexing strategies, and optimizing queries whose execution plans differ from their Oracle counterparts.
- Staff Training & Change Management (15-25% of cost): Your team’s existing expertise is in Oracle. Migrating requires a significant investment in training. An experienced Oracle DBA may need 3-6 months to become proficient in PostgreSQL administration, covering new backup/recovery procedures, monitoring tools, and performance tuning methodologies. Training costs and temporary consultant fees are often necessary to bridge the skills gap during the transition.
A Strategic Blueprint for a Successful Migration
Addressing the multifaceted challenges of an Oracle-to-PostgreSQL migration requires a disciplined, phased approach. A haphazard effort will inevitably lead to budget overruns, missed deadlines, and production failures. This blueprint outlines a four-phase strategy—Assessment, Execution, Testing, and Cutover—designed to impose order on the complexity and mitigate risk at every stage.
Phase 1: Assessment and Planning – Measure Twice, Cut Once
This foundational phase is the most critical for the project’s success. Its goal is to create a complete and realistic picture of the migration’s scope, complexity, and cost before committing significant resources.
- Comprehensive Audit: The first step is a deep analysis of the source Oracle environment. Automated tools are invaluable here. Running a tool like ora2pg with its reporting flag can generate a detailed migration assessment report. This report inventories all database objects (tables, views, packages, procedures), highlights the use of Oracle-specific features, and provides an initial man-day estimate for the conversion effort. This audit must also map all application dependencies and external system integrations.
- Strategy Selection: Based on the audit’s findings—specifically database size, data change rate, and business downtime tolerance—the migration strategy must be formally chosen. For a small development database, a simple “Big Bang” export/import might suffice. For a large, 24/7 production OLTP system, a CDC-based, near-zero downtime approach is non-negotiable.
- Tool Selection: The right tools are essential for efficiency and reliability. A well-architected migration toolkit often includes:
- Assessment & Schema Conversion: Open-source tools like Ora2Pg are the industry standard for analyzing the Oracle schema and generating the initial PostgreSQL DDL. Cloud-specific tools like the AWS Schema Conversion Tool (SCT) serve a similar purpose for migrations into the AWS ecosystem.
- Data Migration & CDC: For continuous replication, solutions range from cloud-native services like AWS Database Migration Service (DMS) to robust, enterprise-grade commercial tools and modern real-time ETL platforms.
- Compatibility Layers: To reduce the code refactoring burden, consider using the orafceextension for PostgreSQL. This popular extension emulates a subset of Oracle’s most common built-in functions and packages (e.g., DBMS_OUTPUT, next_day, last_day), allowing some PL/SQL code to run with minimal changes.
- Proof of Concept (PoC): Before going all-in, conduct a small-scale PoC. Migrate a single, representative application module or a subset of the database. This exercise serves to validate the chosen tools and methodology, uncover unforeseen complexities, and refine effort estimates, providing invaluable real-world data for the full project plan.
Phase 2: Execution – Schema, Code, and Data
With a solid plan in place, the technical execution begins. This phase involves the parallel workstreams of converting the database structure and migrating the data itself.
- Schema and Code Conversion:
- Use the chosen tool (e.g., ora2pg) to perform an automated conversion of the Oracle DDL, generating the initial set of .sql scripts for creating tables, views, sequences, and indexes in PostgreSQL.
- Manually review and refactor the generated scripts. This is a critical step. The automated output is a starting point, not a final product. DBAs must meticulously check data type mappings (especially for NUMBER and DATE), verify constraints, and analyze the proposed indexing strategy.
- Begin the intensive process of converting PL/SQL packages, procedures, and functions into PL/pgSQL, applying the translation principles for syntax, exception handling, and package emulation. If planned, install the orafce extension in the target PostgreSQL database at this stage.
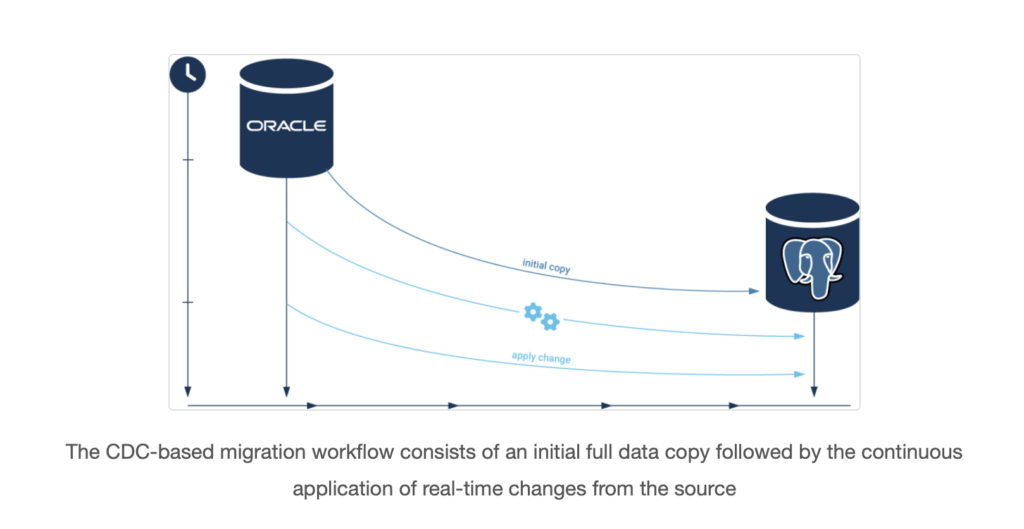
- Data Migration Execution: This follows the CDC workflow defined in the planning phase.
-
- Step 1: Initial Load. The CDC replication tool should be configured and started to capture changes from the Oracle source. Then, the full data load is initiated. This can be done using the CDC tool’s own full-load capability or with a specialized tool to generate highly efficient bulk-load scripts.
- Step 2: Continuous Synchronization. While the initial load is in progress (which could take hours or days for very large databases), the CDC process captures all new transactions in a queue. Once the initial load is complete, the replication tool begins applying this backlog of changes to the target, eventually reaching a state of near-real-time synchronization with the source database.
Phase 3: Testing and Validation – Ensuring a Seamless Transition
Once the target database is synchronised and the application has been pointed to it in a non-production environment, a rigorous testing phase must begin. Skipping or rushing this phase is a direct path to production failure.
- Functional Testing: The application and QA teams must execute a complete regression test suite against the migrated PostgreSQL database. The goal is to verify that every business function, from user login to complex report generation, works exactly as it did on Oracle.
- Performance Testing: It is not enough for the application to be functional; it must also be performant. Run realistic load tests against the new system, measuring the response times of critical business transactions. Compare these results against performance benchmarks taken from the source Oracle system. Any significant performance regressions must be identified, analyzed using PostgreSQL’s tools (like EXPLAIN), and remediated before go-live.
- Data Validation: Concurrently, run automated data validation scripts. This includes comparing row counts, running aggregate queries (SUM, AVG) on key numeric columns, and potentially using checksums to ensure bit-for-bit data integrity between the source and target databases.
Phase 4: Cutover and Go-Live
The cutover is the climax of the migration project—the moment the new PostgreSQL database becomes the system of record. This process must be carefully planned and rehearsed.
- Planning the Cutover Window: Although a CDC-based migration minimizes downtime, a brief maintenance window is still required for the final switch. This should be scheduled during a period of low business activity.
- Final Sync and Switchover: The procedure is as follows:
- Stop all application traffic that performs write operations to the source Oracle database.
- Wait for the CDC process to apply the final few transactions, ensuring the replication lag is zero and both databases are perfectly in sync.
- Reconfigure the application’s connection strings or DNS entries to point to the new PostgreSQL database.
- Resume application traffic. The application is now live on PostgreSQL.
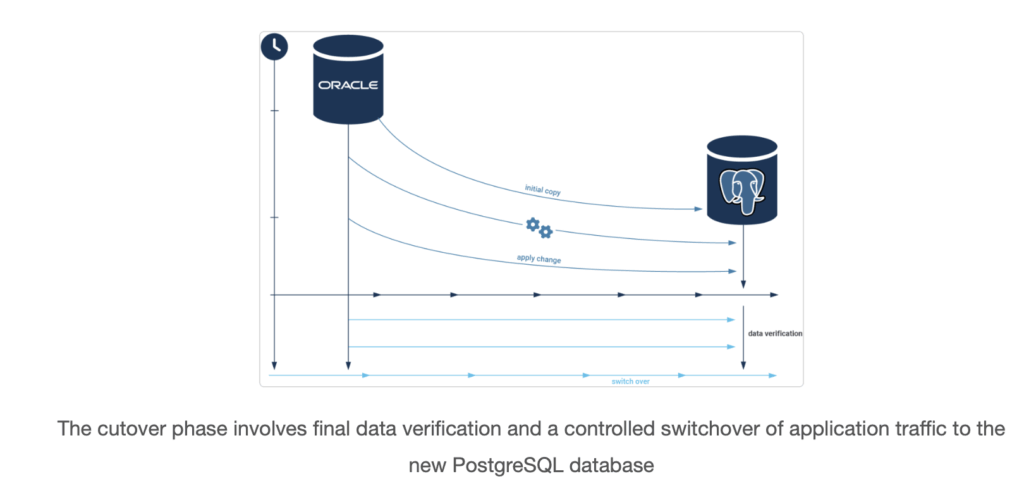
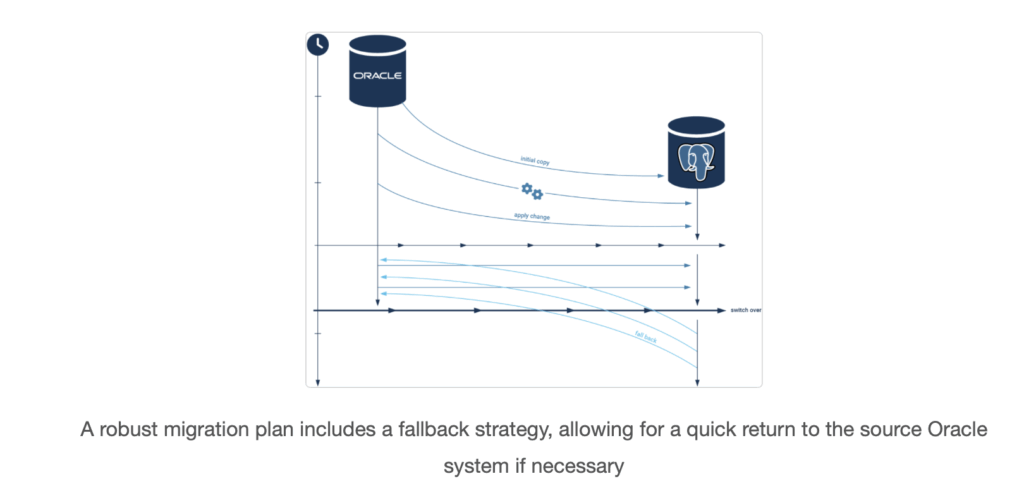
- Rollback Plan: Hope for the best, but plan for the worst. A critical component of the cutover strategy is a well-defined rollback plan. Do not decommission the Oracle database immediately. Keep it running and, if possible, configure a reverse replication stream (from PostgreSQL back to Oracle) for a predefined period (e.g., 24-48 hours). This provides a rapid fallback path in case a critical, unforeseen issue arises on the new system.
Post-Migration: Optimizing for Peak Performance and Reliability
Going live is not the end of the migration journey; it is the beginning of a new operational reality. The skills, tools, and tuning methodologies that worked for Oracle do not directly translate to PostgreSQL. Proactive optimization and the establishment of new operational best practices are essential to realize the full benefits of the new platform and ensure its long-term health and performance.
Performance Tuning in the New World
PostgreSQL is a highly performant database, but it requires deliberate tuning. Unlike Oracle, which has many automated tuning advisors, PostgreSQL relies more on the administrator’s understanding of its architecture and workload.
- Mastering the Query Planner: The single most important tool for a PostgreSQL performance tuner is the EXPLAIN command. While Oracle has a similar command, PostgreSQL’s EXPLAIN (ANALYZE, BUFFERS) is exceptionally powerful. It doesn’t just show the *estimated* plan; it actually *executes* the query and returns the actual execution time, row counts, and buffer usage for each node in the plan tree. This provides precise, actionable data for identifying bottlenecks, such as an inefficient join method or a full table scan where an index scan was expected.
- Key Memory Parameters: Two memory settings have an outsized impact on performance:
- shared_buffers: This parameter defines the amount of memory PostgreSQL dedicates to its primary data cache. It is the PostgreSQL equivalent of Oracle’s buffer cache. A common starting point is to set it to 25% of the system’s total RAM. Setting it too low forces more reads from the OS cache or disk, while setting it too high can negatively impact overall system performance.
- work_mem: This parameter specifies the amount of memory available for internal operations within a query, such as sorting (for ORDER BY, DISTINCT) and hashing (for hash joins, hash aggregation). The default value is typically low (e.g., 4MB). If a query’s sorting or hashing needs exceed work_mem, it spills the data to temporary disk files, causing a massive performance drop. Increasing work_mem (often at the session level for specific queries) can dramatically speed up complex analytical queries and reports.
- Indexing Strategies: While Oracle DBAs are familiar with B-Tree indexes, PostgreSQL offers a richer variety of index types tailored to specific workloads. To achieve optimal performance, it’s important to use the right index for the job. Beyond the standard B-Tree, DBAs should learn about:
- GIN (Generalized Inverted Index): Ideal for indexing composite values where elements can appear multiple times, such as the words in a text document (for full-text search) or the elements of an array or JSONB document.
- GiST (Generalized Search Tree): A framework for building indexes for complex data types, most famously used for geospatial data with the PostGIS extension to accelerate spatial queries.
- BRIN (Block Range Index): A lightweight index designed for very large tables where the data has a natural correlation with its physical storage order (e.g., timestamp-ordered data). It stores the min/max value for large blocks of pages, offering huge space savings over a B-Tree at the cost of some precision.
- Statistics: The PostgreSQL query planner is only as smart as the data it has. It relies on statistical metadata about the distribution of data in tables to make cost estimates and choose the best execution plan. It is crucial to ensure that the ANALYZE command (or the VACUUM ANALYZEprocess) runs regularly to keep these statistics up-to-date, especially after large data loads or changes.
Establishing Robust Operations
Day-to-day management of a PostgreSQL database requires a new set of tools and procedures for monitoring, backup, and maintenance.
- Monitoring and Alerting: You cannot manage what you cannot see. A comprehensive monitoring solution is essential.
- Key Metrics: Critical metrics to monitor include CPU and memory utilization, disk space, replication lag (for HA setups), number of active connections, cache hit ratio, and transaction throughput.
- Tools: PostgreSQL provides a rich set of internal statistics views, with pg_stat_statementsbeing particularly invaluable. It tracks execution statistics for all queries, allowing you to easily identify the most time-consuming and frequently executed statements. For a graphical interface, pgAdmin offers built-in monitoring dashboards. For more advanced, enterprise-wide monitoring, tools like Percona Monitoring and Management (PMM) provide a comprehensive suite for observing metrics, logs, and query analytics.
- Backup and High Availability: A production database requires a bulletproof backup and recovery strategy.
- Backup Strategy: The standard approach combines logical and physical backups. Logical backups, created with pg_dump or pg_dumpall, are great for migrating data or backing up individual databases but are slow to restore for large systems. Physical backups, created with tools like pg_basebackup combined with continuous Write-Ahead Log (WAL) archiving, are the cornerstone of disaster recovery. They allow for Point-in-Time Recovery (PITR). Tools like pgBackRest or WAL-G are highly recommended as they automate and manage this entire process efficiently.
- High Availability: The streaming replication setup configured for the migration must be continuously monitored. Ensure that failover mechanisms are tested regularly to confirm that the standby server can be promoted to primary quickly and reliably in an emergency.
- Maintenance and Upgrades:
- Vacuuming: DBAs must understand the critical role of PostgreSQL’s VACUUM process. It serves two purposes: reclaiming storage space occupied by dead rows (from UPDATEs and DELETEs) and preventing transaction ID wraparound failure, a catastrophic event where the database shuts down to prevent data corruption. While autovacuum handles this in the background, it requires monitoring and occasional tuning.
- Upgrades: PostgreSQL has a rapid annual release cycle. Planning for major version upgrades is part of the operational lifecycle. The standard tool for performing a fast, in-place major version upgrade with minimal downtime is pg_upgrade. This is far preferable to the slow dump-and-restore method required for older versions.
Further Reading
- Cassandra Consistency Level Guide: Mastering Data Consistency in Distributed Systems
- Mastering MySQL EXPLAIN Format: Optimizing Query Performance in MySQL 8.0.32
- MySQL “Got an Error Reading Communication Packet”: Complete Troubleshooting Guide
- Understanding Cloud-Native Databases: A Complete Guide for Modern Applications
- PostgreSQL VACUUM Guide: Complete Best Practices for Database Maintenance
- PostgreSQL MVCC


