How Databricks Performance Bottlenecks Are Silently Burning Through Your Data Strategy and Engineering Budget
And why MinervaDB’s proactive Databricks optimization approach is your financial lifeline
The Hidden Cost Crisis That’s Crippling Data Teams
In the rapidly evolving landscape of data engineering, a silent crisis is unfolding in organizations worldwide. While executives celebrate their digital transformation initiatives and data-driven strategies, a devastating reality lurks beneath the surface: 72.5% of project managers fail to consistently meet agreed project schedules, and over half (58.7%) exceed their allocated budgets.
But here’s the shocking truth that most organizations don’t realize until it’s too late: the majority of data engineers are spending more than half their time handling data issues rather than building value-driven solutions. This isn’t just a productivity problem—it’s a financial hemorrhage that’s quietly draining your data strategy budget while delivering diminishing returns on your technology investments.
The Databricks Performance Bottleneck Epidemic
Databricks has revolutionized how organizations process and analyze massive datasets, but with great power comes great responsibility—and unfortunately, great potential for catastrophic performance issues. The most common bottlenecks plaguing Databricks environments include:
Memory Pressure and Out-of-Memory Errors
The most frequent culprit behind failed jobs and frustrated data teams is memory pressure leading to Out-of-Memory (OOM) errors. When executors can’t handle the data load, jobs fail, requiring expensive reruns and emergency troubleshooting sessions that pull your best engineers away from strategic initiatives.
SQL Query Performance Killers
After analyzing hundreds of slow queries in production environments, experts have discovered that most performance issues stem from the same handful of preventable mistakes. These include:
- Inefficient partition pruning strategies
- Suboptimal join operations
- Poor data distribution patterns
- Inadequate caching strategies
- Unoptimized cluster configurations
Data Skew and Distribution Problems
Perhaps the most insidious performance killer is data skew, where uneven data distribution causes some tasks to process significantly more data than others, creating bottlenecks that slow down entire workflows. This issue often goes undetected until it’s causing massive delays and cost overruns.
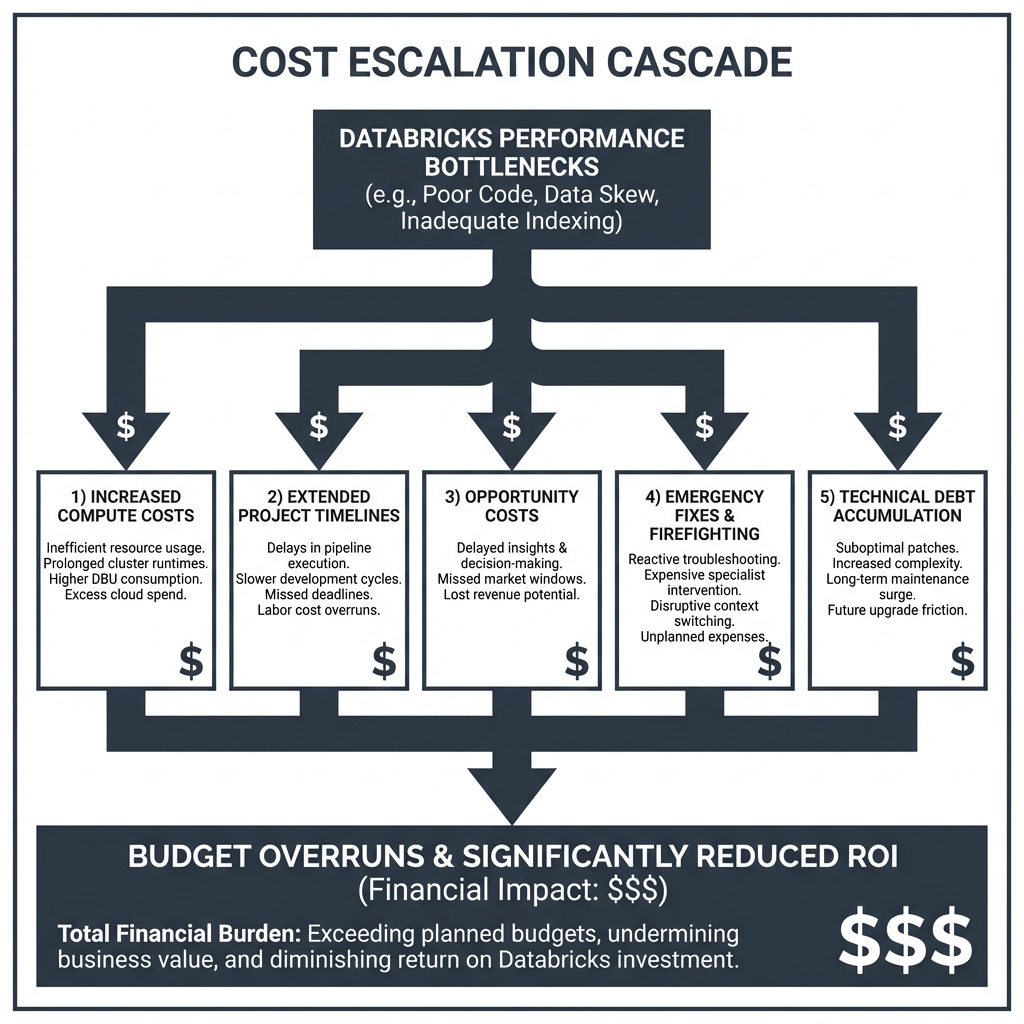
The True Financial Impact: Beyond Compute Costs
The real cost of Databricks performance bottlenecks extends far beyond your monthly cloud bill. Here’s how these technical issues create a cascading financial crisis:
1. Exponential Compute Cost Inflation
When your Databricks jobs are inefficient, you’re not just paying for longer runtimes—you’re paying exponentially more for the same results. Recent case studies reveal that organizations can achieve 90% reduction in Databricks cloud costs through proper optimization, with workflows accelerating from 2 hours to just 10 minutes.
2. Engineering Labor Cost Explosion
With data engineers spending the majority of their time firefighting performance issues instead of building strategic solutions, your labor costs skyrocket while innovation stagnates. The opportunity cost is staggering: every hour spent troubleshooting is an hour not spent on revenue-generating data products.
3. Project Timeline Derailment
Performance bottlenecks don’t just slow down individual queries—they derail entire project timelines. When critical data pipelines fail or run slowly, downstream analytics, reporting, and machine learning initiatives suffer cascading delays that compound budget overruns across multiple departments.
4. Emergency Response and Technical Debt Accumulation
The reactive approach to performance issues creates a vicious cycle: emergency fixes lead to technical debt, which creates more performance problems, requiring more emergency fixes. This cycle consumes an ever-increasing portion of your engineering budget while delivering diminishing returns.
Real-World Success Stories: The ROI of Proactive Optimization
The financial impact of proper Databricks optimization isn’t theoretical—it’s measurable and dramatic:
Global Enterprise Case Study: A multinational corporation achieved a 90% reduction in Databricks cloud costs while reducing critical workflow times from nearly 2 hours to just 10 minutes. The optimization also improved platform stability and provided greater cost transparency for engineering teams.
Financial Services Success: A financial services analytics platform reduced Databricks spend by 35% through targeted cluster optimization and workload tuning, while simultaneously improving query performance and SLA reliability.
SaaS Platform Transformation: A Customer 360 analytics platform improved Databricks analytics throughput by 28% while stabilizing costs through comprehensive workload and job optimization.
These aren’t isolated success stories—they represent a fundamental shift from reactive firefighting to proactive optimization that transforms database operations into strategic assets for measurable ROI and efficiency gains.
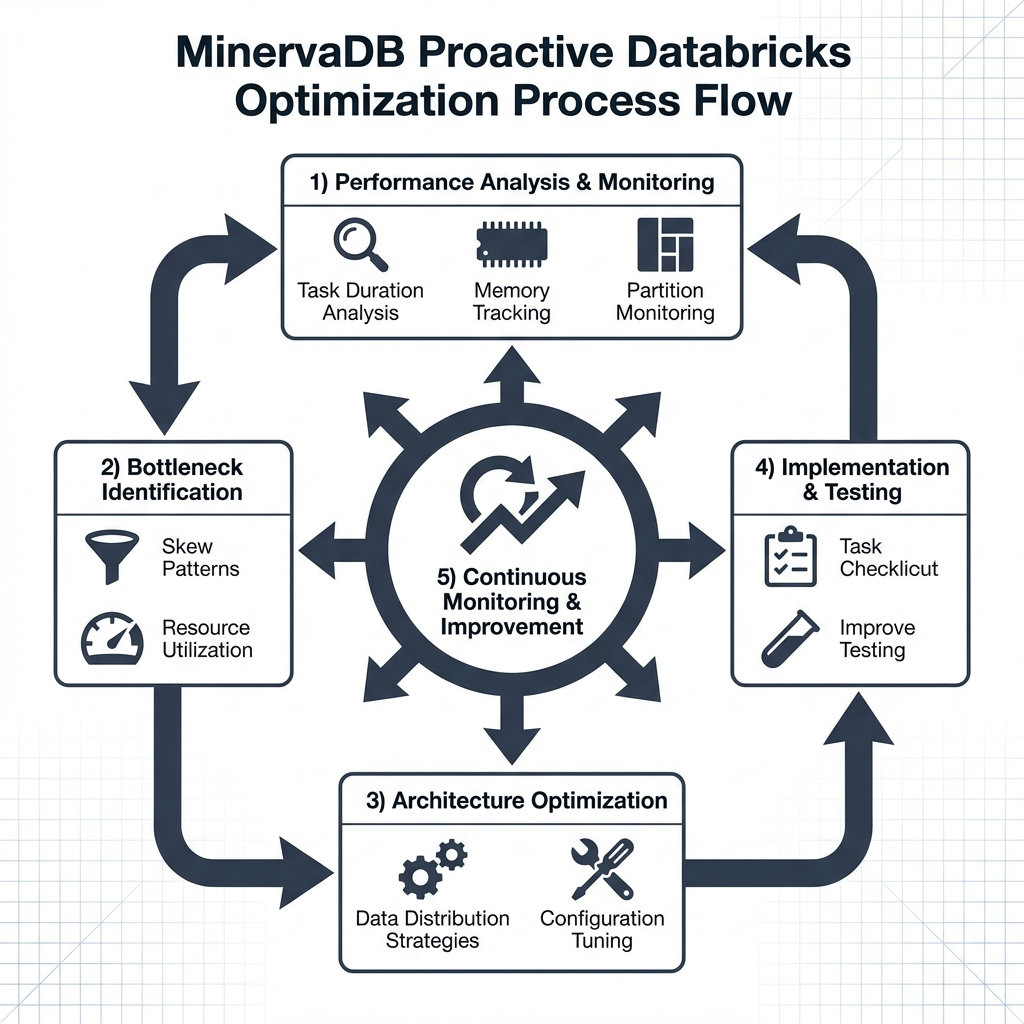
MinervaDB’s Proactive Optimization Methodology: Your Strategic Advantage
While most organizations struggle with reactive approaches to performance issues, MinervaDB has developed a comprehensive, proactive methodology that prevents bottlenecks before they impact your budget and timeline.
Expert Data Engineering Solutions
MinervaDB Engineering Services stands as a premier provider of comprehensive data engineering solutions, delivering expert consulting and end-to-end solutions from initial architecture design to ongoing optimization and support.
Specialized Databricks Services Portfolio
Performance Analysis & Bottleneck Identification
MinervaDB’s approach begins with comprehensive performance analysis, identifying bottlenecks and skew patterns before they become budget-busting problems. This includes:
- Task duration analysis to monitor execution times within stages
- Memory usage tracking to watch for spill indicators
- Partition size monitoring to ensure balanced data distribution
- Resource utilization tracking to optimize executor efficiency
Architecture Optimization
Rather than applying band-aid fixes, MinervaDB designs efficient data distribution strategies that address root causes. Their systematic approach includes:
| Strategy | Implementation | Expected Outcome |
|---|---|---|
| Pre-processing | Apply repartitioning before expensive operations | Reduced shuffle overhead |
| Key Distribution Analysis | Identify and salt highly skewed keys | Balanced partition sizes |
| Adaptive Configuration | Enable AQE for automatic optimization | Runtime performance improvements |
| Resource Tuning | Configure fewer cores per executor for memory-intensive workloads | Better memory allocation per task |
Monitoring Implementation & Continuous Optimization
MinervaDB sets up comprehensive observability systems that provide real-time visibility into your Databricks performance, enabling rapid incident response and continuous optimization. Organizations following this approach achieve 30% faster decision cycles for critical data operations.
The MinervaDB Advantage: Proactive vs. Reactive
Traditional approaches to Databricks optimization are reactive—waiting for problems to occur before addressing them. MinervaDB’s methodology is fundamentally different:
Reactive Approach (Traditional):
- Wait for performance issues to manifest
- Emergency troubleshooting sessions
- Band-aid fixes that create technical debt
- Unpredictable costs and timelines
- Engineering resources constantly firefighting
MinervaDB Proactive Approach:
- Continuous monitoring and early detection
- Systematic optimization before issues impact users
- Root cause resolution that prevents future problems
- Predictable costs and improved performance
- Engineering resources focused on strategic initiatives
Implementation Framework: Your Path to Optimization Success
Phase 1: Comprehensive Assessment (Weeks 1-2)
- Complete performance audit of existing Databricks environment
- Identification of current bottlenecks and cost inefficiencies
- Baseline establishment for measuring improvement ROI
- Risk assessment and prioritization of optimization opportunities
Phase 2: Strategic Optimization (Weeks 3-6)
- Implementation of core performance improvements
- Architecture optimization for efficient data distribution
- Configuration tuning for optimal resource utilization
- Establishment of monitoring and alerting systems
Phase 3: Continuous Improvement (Ongoing)
- Real-time performance monitoring and optimization
- Proactive identification and resolution of emerging issues
- Regular performance reviews and strategy adjustments
- Knowledge transfer and team capability building
The ROI Calculator: Making the Business Case
Based on documented case studies and MinervaDB’s track record, organizations can expect:
Immediate Cost Savings:
- 35-90% reduction in Databricks compute costs
- 50-80% reduction in engineering time spent on performance issues
- 28-30% improvement in overall data processing throughput
Long-term Strategic Benefits:
- Predictable and optimized data infrastructure costs
- Engineering teams focused on value-creation rather than firefighting
- Faster time-to-market for data-driven initiatives
- Improved reliability and SLA compliance
Risk Mitigation:
- Elimination of emergency performance crises
- Reduced technical debt accumulation
- Improved system stability and predictability
The Cost of Inaction: Why Waiting Is the Most Expensive Option
Every day you delay implementing proactive Databricks optimization, your organization continues to:
- Overpay for inefficient compute resources
- Waste valuable engineering talent on preventable problems
- Risk project delays and budget overruns
- Accumulate technical debt that becomes increasingly expensive to resolve
- Miss opportunities for competitive advantage through faster, more reliable data insights
The hidden cost crisis in data engineering isn’t going away—if anything, it’s accelerating as organizations scale their data operations and cloud providers continue adjusting pricing models.
Transform Your Data Strategy: The MinervaDB Solution
MinervaDB’s comprehensive approach to Databricks optimization isn’t just about fixing performance problems—it’s about transforming your entire data strategy from a cost center into a competitive advantage. By implementing proactive optimization strategies, you’re not just saving money; you’re investing in a foundation that enables faster innovation, more reliable insights, and sustainable growth.
The question isn’t whether you can afford to optimize your Databricks environment—it’s whether you can afford not to. With documented case studies showing 90% cost reductions and dramatic performance improvements, the ROI of proactive optimization is clear and compelling.
Ready to stop the budget hemorrhage and transform your Databricks performance?
Contact MinervaDB today to schedule your comprehensive Databricks performance assessment. Don’t let another day of inefficient operations drain your data strategy budget. Your future self—and your CFO—will thank you.
MinervaDB delivers 24/7 consultative support with proactive troubleshooting, performance optimization, and specialized services to ensure peak efficiency for your data infrastructure. Transform your database operations into strategic assets with measurable ROI and efficiency gains.

