# Example: Vector similarity search implementation
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# Vector embedding storage and retrieval
def find_similar_vectors(query_vector, vector_database, top_k=10):
similarities = cosine_similarity([query_vector], vector_database)
top_indices = np.argsort(similarities[0])[-top_k:][::-1]
return [(idx, similarities[0][idx]) for idx in top_indices]
Edge Computing and Distributed Data Processing
Edge Database Architectures
The proliferation of IoT devices and edge computing is driving new database deployment patterns:
- Lightweight database engines: Optimized for resource-constrained environments
- Data synchronization: Efficient replication between edge and central systems
- Offline capabilities: Maintaining functionality during network disruptions
- Local processing: Reducing latency through edge-based analytics
5G and Ultra-Low Latency Requirements
- Real-time applications: Gaming, autonomous vehicles, and industrial automation
- Network-aware databases: Optimizing for 5G network characteristics
- Mobile edge computing: Databases deployed at cellular network edges
- Tactile internet: Sub-millisecond response time requirements
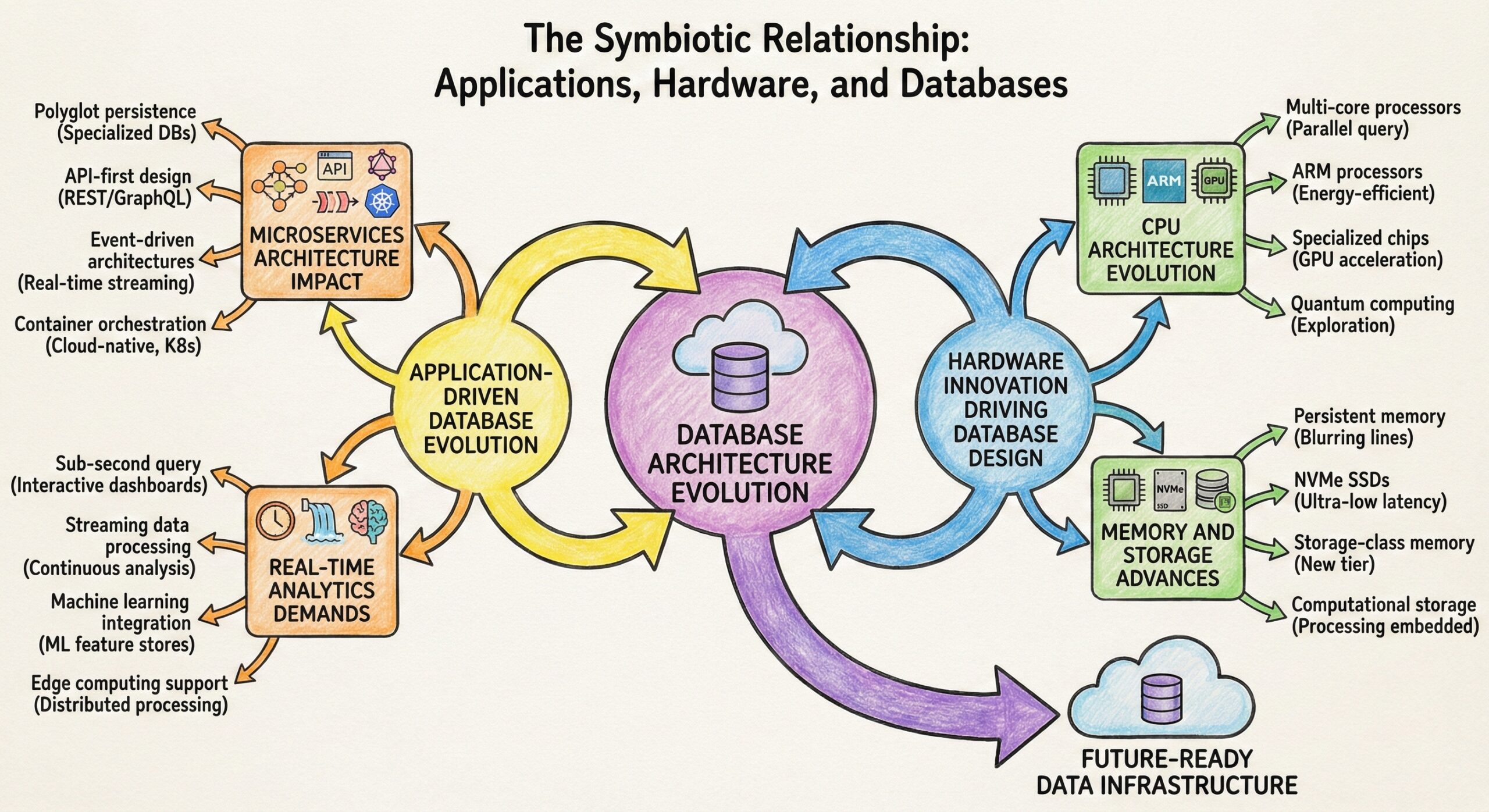
Hardware Trends Influencing Database Design
Next-Generation Storage Technologies
Persistent Memory Integration
Intel Optane and similar technologies are creating new storage tiers:
# Example: Configuring persistent memory for database optimization
# Mount persistent memory as filesystem
mount -t ext4 -o dax /dev/pmem0 /mnt/pmem
# Configure database to use persistent memory
echo "shared_buffers = 32GB" >> postgresql.conf
echo "wal_buffers = 1GB" >> postgresql.conf
echo "checkpoint_completion_target = 0.9" >> postgresql.conf
Computational Storage Devices
Storage devices with embedded processing capabilities:
- In-storage computing: Reducing data movement through storage-level processing
- Smart SSDs: Executing database operations directly on storage devices
- Near-data computing: Processing data closer to where it’s stored
- Bandwidth optimization: Reducing network and memory bus traffic
Advanced CPU Architectures
Heterogeneous Computing Platforms
- CPU-GPU integration: Unified memory architectures for analytical workloads
- FPGA acceleration: Customizable hardware for specific database operations
- ARM-based servers: Energy-efficient alternatives to x86 architectures
- Neuromorphic processors: Brain-inspired computing for AI workloads
Memory Architecture Evolution
- High Bandwidth Memory (HBM): Increased memory throughput for analytical databases
- Non-Uniform Memory Access (NUMA): Optimizing database performance on multi-socket systems
- Memory pooling: Disaggregated memory architectures for cloud environments
- Persistent memory: Bridging the gap between volatile and non-volatile storage
Software and Operating System Innovations
Container and Orchestration Technologies
Kubernetes-Native Databases
The container orchestration revolution is transforming database deployment:
# Example: Kubernetes StatefulSet for database deployment
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: distributed-database
spec:
serviceName: "db-service"
replicas: 3
selector:
matchLabels:
app: distributed-db
template:
metadata:
labels:
app: distributed-db
spec:
containers:
- name: database
image: minervadb/optimized-db:latest
resources:
requests:
memory: "8Gi"
cpu: "2"
limits:
memory: "16Gi"
cpu: "4"
Service Mesh Integration
- Traffic management: Intelligent routing and load balancing for database connections
- Security policies: Mutual TLS and fine-grained access control
- Observability: Comprehensive monitoring and tracing of database interactions
- Resilience patterns: Circuit breakers and retry mechanisms for database reliability
Advanced Operating System Features
eBPF and Kernel Programmability
Extended Berkeley Packet Filter (eBPF) is enabling new database optimization techniques:
- Custom scheduling: Application-specific CPU scheduling for database workloads
- Network optimization: Kernel-level network stack customization
- Security monitoring: Real-time security policy enforcement
- Performance profiling: Low-overhead performance monitoring and analysis
User-Space Networking
- DPDK integration: High-performance packet processing for distributed databases
- RDMA support: Remote Direct Memory Access for low-latency clustering
- SR-IOV virtualization: Hardware-level network virtualization for cloud databases
- SmartNICs: Offloading network processing to specialized hardware
Database Technologies of the Future
Quantum-Inspired Computing
Quantum Database Algorithms
While true quantum databases are still experimental, quantum-inspired algorithms are showing promise:
- Quantum annealing: Optimization problems in query planning and resource allocation
- Quantum machine learning: Enhanced pattern recognition in large datasets
- Quantum cryptography: Ultra-secure database encryption and key distribution
- Quantum simulation: Modeling complex database behaviors and optimizations
Neuromorphic Database Processing
Brain-Inspired Computing
Neuromorphic processors are opening new possibilities for database processing:
- Spiking neural networks: Event-driven processing for streaming data
- Adaptive learning: Databases that continuously optimize based on usage patterns
- Pattern recognition: Advanced anomaly detection and data classification
- Energy efficiency: Ultra-low power consumption for edge database deployments
DNA Storage Integration
Biological Data Storage
DNA storage technology is emerging as a solution for long-term data archival:
- Massive density: Storing exabytes of data in microscopic volumes
- Longevity: Data preservation for thousands of years
- Error correction: Advanced encoding techniques for data integrity
- Retrieval mechanisms: Developing efficient random access methods
Industry-Specific Database Evolution
Healthcare and Life Sciences
Genomic Data Processing
- Sequence alignment: Specialized databases for DNA/RNA sequence analysis
- Variant calling: Real-time genetic variation identification
- Population genomics: Large-scale genetic association studies
- Precision medicine: Personalized treatment recommendation systems
Medical Imaging Databases
- DICOM optimization: Efficient storage and retrieval of medical images
- AI-powered diagnosis: Integration with machine learning models
- 3D visualization: Support for volumetric medical data
- Compliance frameworks: HIPAA and international privacy regulations
Financial Services
Real-Time Risk Management
- Streaming analytics: Continuous risk assessment and monitoring
- Regulatory reporting: Automated compliance data generation
- Fraud detection: Machine learning-powered anomaly identification
- High-frequency trading: Ultra-low latency market data processing
Blockchain Integration
- Distributed ledger: Immutable transaction recording
- Smart contracts: Automated financial instrument execution
- Cross-chain interoperability: Multi-blockchain data synchronization
- Regulatory compliance: Audit trails and transparency requirements
Telecommunications
5G Network Analytics
- Network slicing: Dynamic resource allocation based on service requirements
- Predictive maintenance: AI-powered network equipment monitoring
- Customer experience: Real-time service quality optimization
- Edge computing: Distributed processing for ultra-low latency applications
MinervaDB’s Vision for Future Database Infrastructure
Adaptive Database Architectures
At MinervaDB, we envision database systems that automatically adapt to changing requirements:
Self-Optimizing Systems
- Workload analysis: Continuous monitoring and optimization of database performance
- Resource allocation: Dynamic scaling based on real-time demand
- Schema evolution: Automatic adaptation to changing data structures
- Query optimization: AI-powered query plan selection and execution
Intelligent Data Management
- Automated tiering: Moving data between storage tiers based on access patterns
- Predictive caching: Pre-loading frequently accessed data
- Compression optimization: Selecting optimal compression algorithms for different data types
- Lifecycle management: Automated data archival and deletion policies
Unified Data Platform Strategy
Convergence of OLTP and OLAP
The future belongs to unified platforms that seamlessly handle both transactional and analytical workloads:
-- Example: Unified query across transactional and analytical data
WITH real_time_metrics AS (
SELECT customer_id, SUM(transaction_amount) as daily_spend
FROM transactions
WHERE transaction_date = CURRENT_DATE
GROUP BY customer_id
),
historical_analysis AS (
SELECT customer_id, AVG(monthly_spend) as avg_monthly_spend
FROM customer_analytics
WHERE analysis_month >= CURRENT_DATE - INTERVAL '12 months'
GROUP BY customer_id
)
SELECT r.customer_id, r.daily_spend, h.avg_monthly_spend,
CASE WHEN r.daily_spend > h.avg_monthly_spend * 0.1
THEN 'High Spender' ELSE 'Normal' END as spending_category
FROM real_time_metrics r
JOIN historical_analysis h ON r.customer_id = h.customer_id;
Cloud-Native Excellence
Multi-Cloud Optimization
- Vendor neutrality: Avoiding lock-in through standardized interfaces
- Cost optimization: Leveraging competitive pricing across cloud providers
- Geographic distribution: Meeting data sovereignty and latency requirements
- Disaster recovery: Cross-cloud backup and failover capabilities
Preparing for the Database Future
Strategic Technology Adoption
Evaluation Framework
Organizations should establish systematic approaches for evaluating emerging database technologies:
- Business alignment: Ensuring technology choices support strategic objectives
- Risk assessment: Evaluating maturity, vendor stability, and migration complexity
- Performance validation: Comprehensive testing with realistic workloads
- Cost-benefit analysis: Total cost of ownership including operational overhead
- Skills assessment: Team capabilities and training requirements
Building Future-Ready Teams
Skill Development Priorities
- Cloud-native technologies: Kubernetes, containerization, and microservices
- AI and machine learning: Understanding ML integration with database systems
- Security expertise: Advanced threat detection and data protection
- Performance optimization: Modern profiling and tuning techniques
- Automation skills: Infrastructure as code and DevOps practices
Conclusion: Embracing the Database Evolution
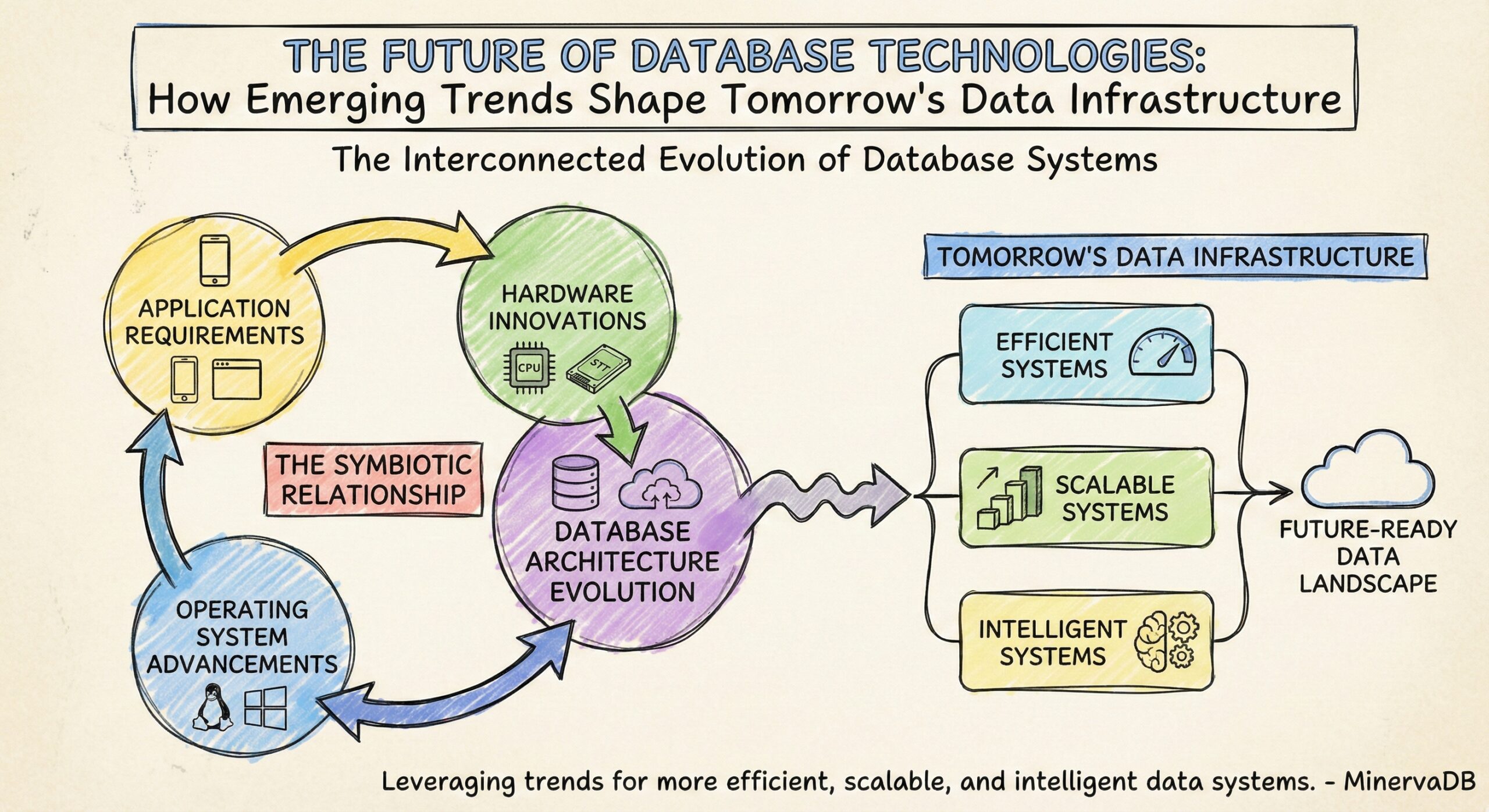
The future of database technology is being shaped by the convergence of multiple technological trends: cloud computing, artificial intelligence, edge computing, and advanced hardware architectures. Organizations that understand these interconnected relationships and proactively adapt their database strategies will gain significant competitive advantages.
At MinervaDB, we’re committed to helping organizations navigate this complex landscape. Our expertise spans traditional database optimization, cloud-native architectures, and emerging technologies, ensuring that our clients’ database infrastructures are not just optimized for today’s requirements but prepared for tomorrow’s opportunities.
The databases of the future will be more intelligent, more adaptive, and more integrated with the broader technology ecosystem than ever before. By staying ahead of these trends and building flexible, scalable database architectures, organizations can ensure their data infrastructure becomes a strategic asset that drives innovation and competitive advantage.
As we continue to monitor and analyze these emerging technologies, MinervaDB remains your trusted partner in building database infrastructures that are optimal, scalable, highly available, reliable, and secure—ready for whatever the future may bring.
Stay tuned for our ongoing coverage of emerging database technologies and their impact on enterprise data infrastructure. Contact MinervaDB to learn how we can help your organization prepare for the database technologies of tomorrow.