Optimizing Pagination in PostgreSQL 17: Why OFFSET/LIMIT Fails and What to Use Instead
Pagination with OFFSET/LIMIT in PostgreSQL 17 is a common but often costly pattern, especially in read-heavy applications. While it appears simple to implement, its performance degrades severely as users navigate to deeper pages. This article explains the technical reasons behind this performance trap, validates the core concepts, and provides superior, scalable alternatives for modern applications.
The Hidden Cost of OFFSET/LIMIT
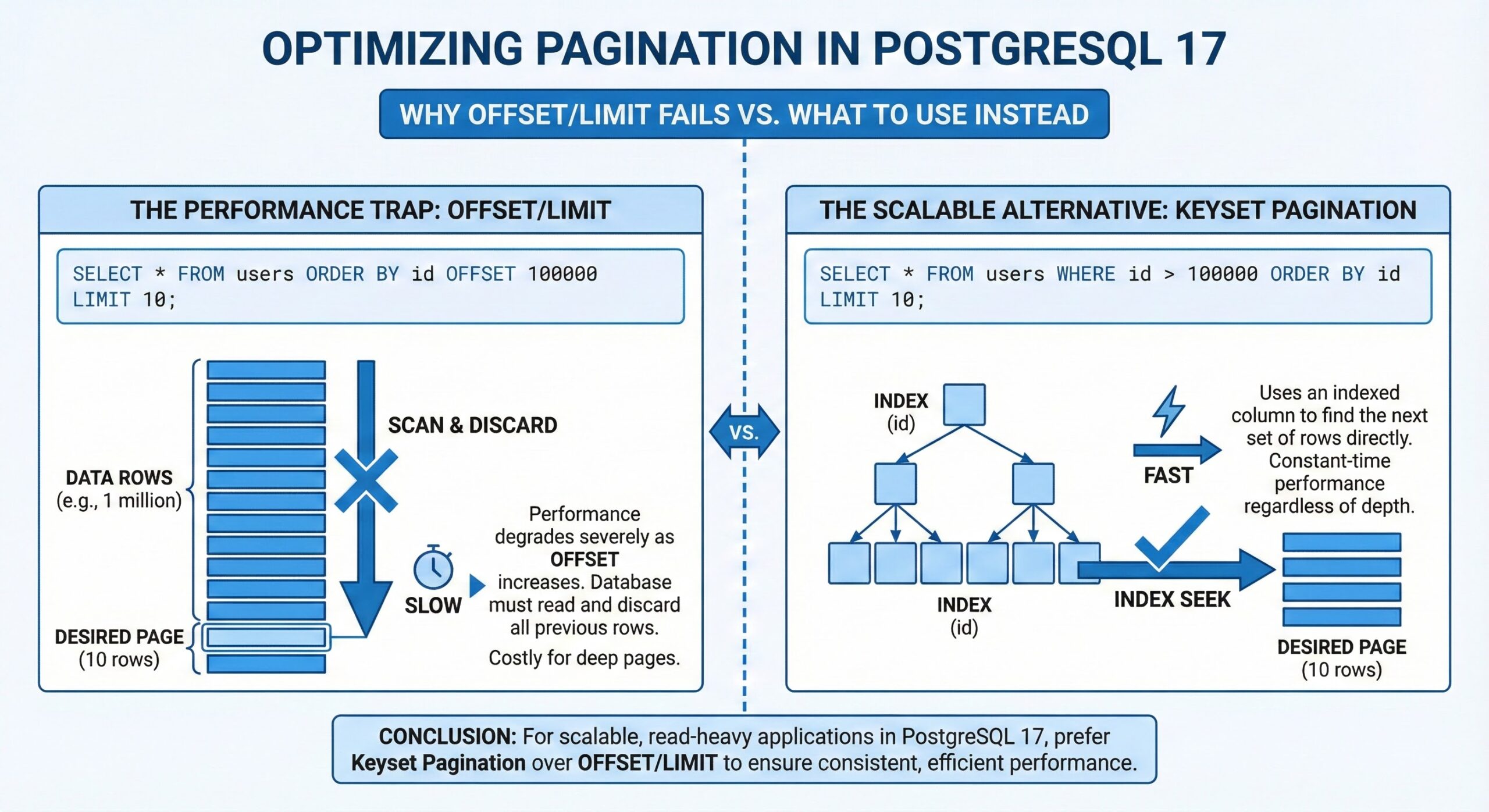
The fundamental issue with LIMIT and OFFSET is a misconception about what they do. LIMIT n correctly caps the number of rows returned to the client. However, OFFSET k does not skip rows at the storage level; it instructs PostgreSQL to read, sort, and then discard the first k rows from the result stream. This means the database engine must still process every single row up to the requested page.
For a query with ORDER BY, PostgreSQL’s planner must generate a result set in the specified order before it can apply the OFFSET and LIMIT clauses. This leads to a time complexity that is effectively linear in OFFSET + LIMIT. A request for page 10,000 with a page size of 20 (OFFSET 199800 LIMIT 20) forces PostgreSQL to process nearly 200,000 rows, even if an index exists on the ORDER BY column. This linear scan consumes significant CPU, memory, and I/O resources on rows that are ultimately discarded.
Why Deep Pagination with OFFSET is a Performance Anti-Pattern
The cost of OFFSET/LIMIT pagination grows with each subsequent page. Page 2 is more expensive than page 1, page 3 more than page 2, and so on. This makes features like “Go to page 5000” extremely expensive, often resulting in multi-second query times on large tables.
This problem is exacerbated by common anti-patterns:
- Deep page jumps: Directly translating a page number to a large OFFSET value creates worst-case linear scans.
- Real-time total counts: Queries that combine COUNT(*) with OFFSET/LIMIT on every request double the database load, as the count often requires a full or partial scan.
- Complex queries with joins: When OFFSET/LIMIT is applied to queries with multiple joins and non-selective filters, the database performs extensive work on intermediate result rows that will be discarded.
The Scalable Solution: Keyset (Seek) Pagination
The most effective alternative is keyset pagination (also known as seek method or cursor-based pagination). Instead of skipping rows by count, it uses the values from the last row of the previous page as a starting point for the next query.
For example, if the last record on the current page has an id of 150 and a created_at of ‘2025-12-27 10:00:00’, the next page query would be:
SELECT * FROM table_name WHERE (id, created_at) > (150, '2025-12-27 10:00:00') ORDER BY id, created_at LIMIT 20;
This query uses a WHERE clause on an indexed column (or composite index) to jump directly to the relevant data, resulting in near-constant-time performance per page, regardless of the dataset size. A matching composite index on (id, created_at) is crucial for this to be efficient.
OFFSET/LIMIT vs. Keyset Pagination: A Direct Comparison
| Dimension | OFFSET/LIMIT pagination | Keyset (seek) pagination |
|---|---|---|
| Core idea | Skip OFFSET rows, then return LIMIT rows. | Filter rows using last seen key and ORDER BY. |
| Cost growth | Grows roughly linearly with OFFSET. | Nearly constant per page for large datasets. |
| Large page jumps | Supports arbitrary page numbers. | Typically supports only next/previous pages. |
| Stability on writes | Can show duplicates or gaps when rows are inserted/removed. | Produces stable sequences tied to key values. |
| Index requirements | Works better with index on ORDER BY but still scans skipped rows. | Requires appropriate index on key columns to be efficient. |
| Best use cases | Small datasets, admin tools, low offsets. | High-traffic feeds, infinite scroll, large tables. |
Practical Implementation for PostgreSQL 17
Migrating from OFFSET/LIMIT to keyset pagination is straightforward:
- Ensure deterministic ordering: Always use an ORDER BY clause with a unique or composite key (e.g., (created_at, id)) to prevent inconsistent results.
- Create the right index: Build a B-tree index on the column(s) used for the keyset (e.g., CREATE INDEX idx_table_created_id ON table_name (created_at, id);).
- Rewrite the query: Replace OFFSET :offset with a WHERE clause that compares the sort key to the last values from the previous page.
- Handle the cursor in your application: Encode the last row’s key values (e.g., idand created_at) into an opaque cursor token (often base64-encoded) to send to the client. Decode this token on the next request to populate the WHERE clause.
By replacing naive OFFSET/LIMIT with keyset pagination, you can achieve fast, scalable, and consistent performance for your application’s data browsing features, even as your dataset grows into the millions of rows.
Further Reading
- Deep Dive into RocksDB’s LSM-Tree Architecture
- From XL to XS: A Practical Guide to Rightsizing Snowflake
- How PostgreSQL and MySQL Handle No-Op Updates
- Understanding Foreign Data Wrappers in PostgreSQL
- ChistaDATA University


