Milvus scaling
In today’s AI-driven landscape, vector databases play a vital role in powering applications that require similarity search across massive datasets. As embedding models grow more sophisticated and datasets expand exponentially, engineers face mounting challenges in efficiently searching through billions of vectors. To address this, Milvus—an open-source vector database—has emerged as a leading solution for scaling vector search operations. In the following sections, we’ll explore how Milvus successfully achieves this at scale.
The Challenge of Scale in Vector Search
Before we examine Milvus’s architecture, we must first recognise the fundamental challenge: vector search demands significant computational resources. As you work with high-dimensional embeddings—often 768, 1024, or even more dimensions—the complexity of calculating distances between vectors increases exponentially with dataset size.
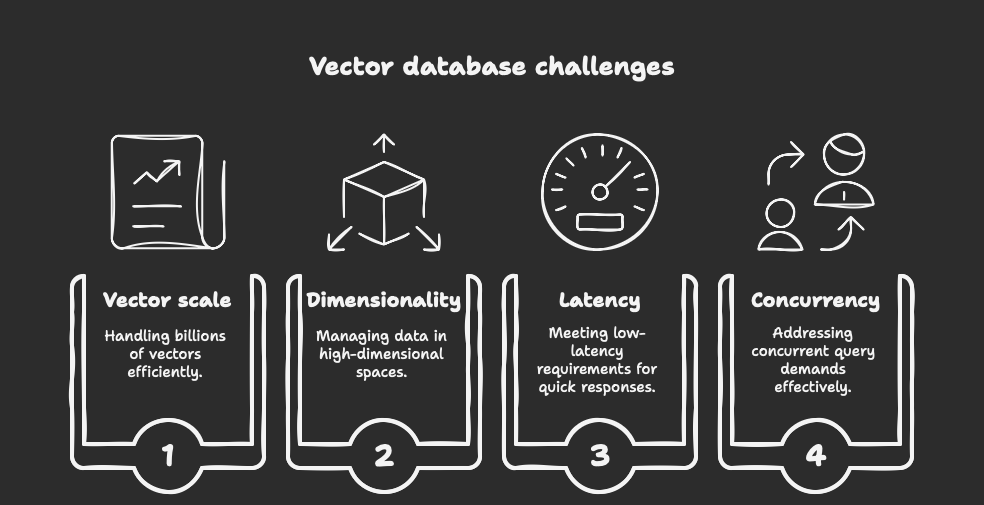
Traditional methods quickly fall short when you need to handle:
-
Billions of vectors
-
High-dimensional spaces
-
Low-latency requirements
-
Concurrent query demands
Milvus’s Distributed Architecture
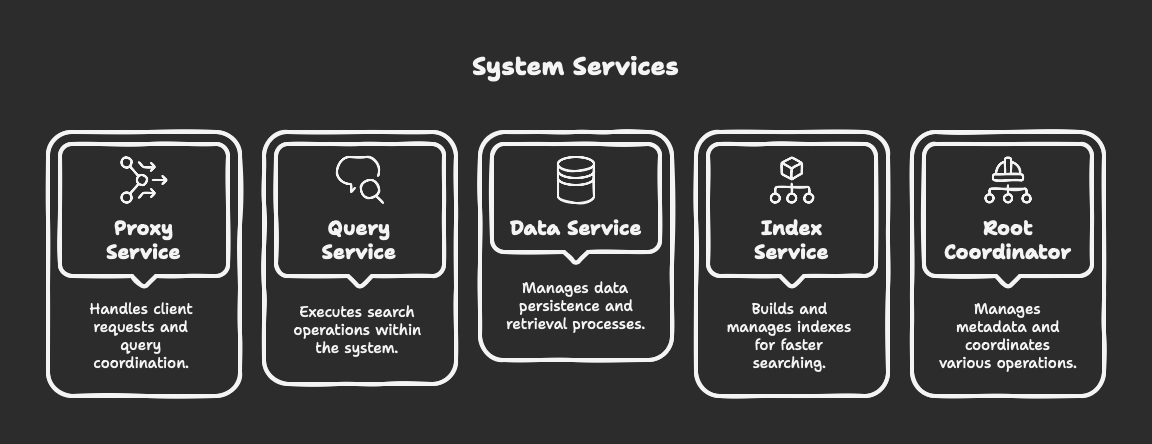
Milvus 2.0+ employs a cloud-native, microservices architecture that separates storage from computation, allowing each component to scale independently:
-
Proxy Service: Handles client requests and query coordination
-
Query Service: Executes search operations
-
Data Service: Manages data persistence and retrieval
-
Index Service: Builds and manages indexes
-
Root Coordinator: Manages metadata and coordinates operations
This separation enables horizontal scaling where resources can be allocated precisely where needed.
Indexing Strategies for Massive Datasets
At the heart of Milvus’s performance is its sophisticated indexing technology:
Approximate Nearest Neighbor (ANN) Indexes
Milvus supports multiple index types optimized for different scenarios:
-
HNSW (Hierarchical Navigable Small World): Offers excellent recall and query performance for medium-sized datasets
-
IVF_FLAT: Divides the vector space into clusters for faster search
-
IVF_SQ8/PQ: Adds quantization to reduce memory usage
-
ANNOY: Provides good performance with lower memory requirements
For billion-scale datasets, Milvus typically leverages IVF-based indexes with quantization techniques that dramatically reduce memory footprint while maintaining search quality.
Dynamic Indexing
Milvus employs a dynamic indexing strategy where:
-
New data is initially stored in growing segments
-
Background processes continuously build optimized indexes
-
Queries search both indexed and unindexed data, merging results
This approach allows for continuous ingestion while maintaining query performance.
Sharding and Partitioning
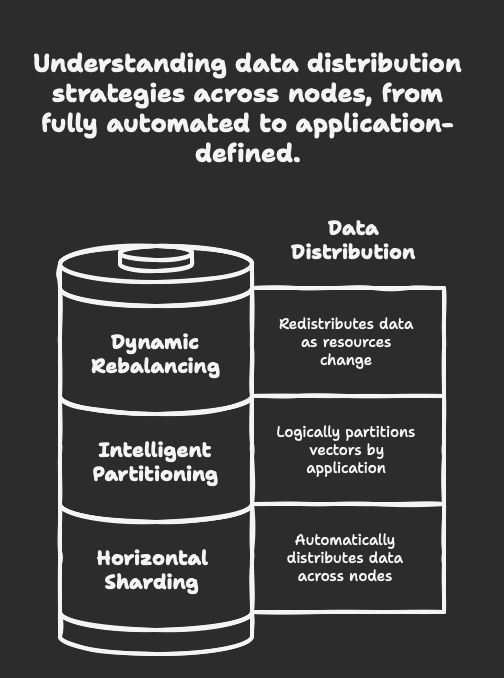
When dealing with billions of vectors, no single machine can handle the load. Milvus implements:
-
Horizontal Sharding: Data is automatically distributed across multiple nodes
-
Intelligent Partitioning: Vectors can be logically partitioned by application-specific criteria
-
Dynamic Rebalancing: Data is redistributed as cluster resources change
The query coordinator intelligently dispatches search requests to relevant shards, aggregates results, and returns the global top-k matches.
Memory Management and Tiered Storage
Milvus implements a sophisticated memory management system to ensure efficient performance at scale.
-
To start, it keeps hot data and indexes in RAM for rapid access through in-memory processing.
-
Meanwhile, it offloads cold data to disk, reducing memory pressure without sacrificing availability.
-
Additionally, Milvus integrates with object storage, such as S3-compatible systems, to archive historical data efficiently.
This tiered approach allows Milvus to handle datasets much larger than available RAM while maintaining performance for frequently accessed data.
Query Optimization Techniques
Beyond architectural considerations, Milvus employs several query optimization techniques:
-
Vector Quantization: Reduces memory footprint by compressing vectors
-
Query Routing: Directs queries only to relevant partitions
-
Parallel Processing: Distributes query workload across available CPU cores
-
GPU Acceleration: Offloads computation to GPUs for faster distance calculations
-
Result Caching: Stores frequent query results for immediate retrieval
Real-world Performance
In production environments, Milvus has demonstrated impressive capabilities:
-
Throughput: Processing thousands of queries per second
-
Latency: Sub-100ms response times even at billion-scale
-
Scalability: Linear performance scaling with additional nodes
-
Resource Efficiency: Optimized resource utilization through dynamic scaling
Deployment Considerations for Billion-Scale Deployments
When deploying Milvus for extremely large datasets, you should consider several critical factors:
-
Hardware Selection: Balance between memory, CPU, storage, and network bandwidth
-
Cluster Sizing: Start with a baseline and scale horizontally as needed
-
Index Configuration: Choose indexes based on your specific recall/performance requirements
-
Monitoring: Implement comprehensive monitoring of query latency, resource utilization, and index build times
Conclusion
Milvus handles billions of embeddings effectively because of its distributed architecture, sophisticated indexing strategies, and advanced optimization techniques work together seamlessly. As vector search becomes increasingly central to AI applications, Milvus continues to offer a scalable foundation that evolves alongside your growing data.
Whether you’re starting out or scaling up, Milvus supports recommendation systems, semantic search engines, and multimodal AI applications with ease. It delivers the necessary infrastructure to manage millions—then billions—of vectors without compromising on performance.
For organizations seeking to scale vector search efficiently, Milvus goes beyond being a simple database. It serves as a comprehensive platform built specifically to meet the complex demands of high-dimensional similarity search at massive scale.


