Mastering PostgreSQL Replication: A Complete Guide for Database Professionals
PostgreSQL replication stands as one of the most critical components in building robust, scalable database architectures. For database architects and DBAs managing enterprise-level PostgreSQL deployments, understanding the intricacies of replication is essential for ensuring high availability, disaster recovery, and optimal performance distribution.
Understanding PostgreSQL Replication Fundamentals
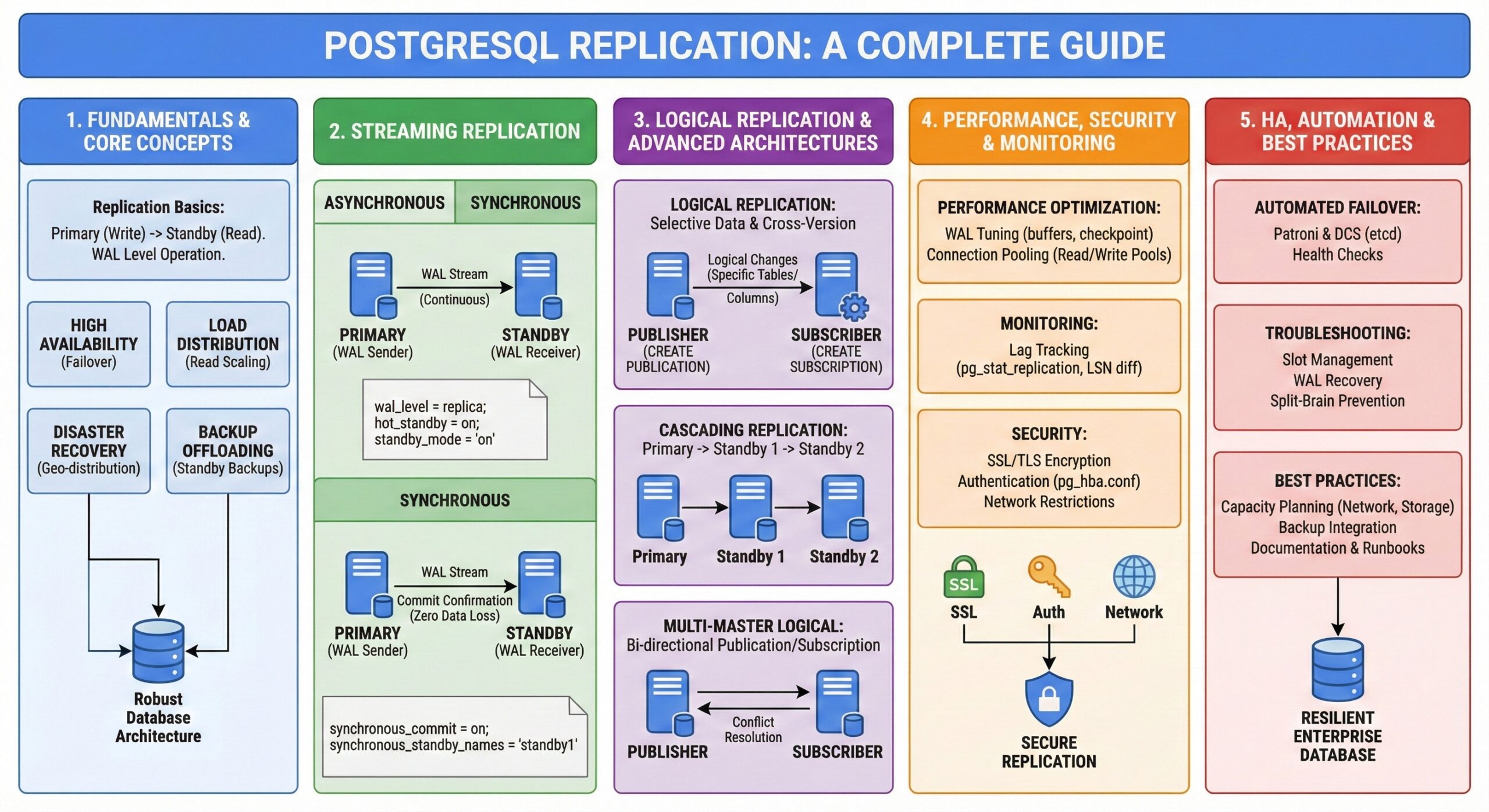
PostgreSQL replication creates and maintains identical copies of your database across multiple servers, providing redundancy and enabling load distribution. This process involves a primary server that accepts write operations and one or more standby servers that receive and apply changes from the primary.
The replication mechanism operates at the Write-Ahead Log (WAL) level, ensuring data consistency and enabling point-in-time recovery capabilities. This approach provides several advantages:
- High Availability: Automatic failover capabilities minimize downtime
- Load Distribution: Read queries can be distributed across multiple replicas
- Disaster Recovery: Geographic distribution of data ensures business continuity
- Backup Offloading: Backup operations can run on standby servers without impacting primary performance
Streaming Replication: The Foundation of PostgreSQL High Availability
Asynchronous Streaming Replication
Asynchronous streaming replication represents the most commonly implemented replication method in PostgreSQL environments. In this configuration, the primary server doesn’t wait for standby confirmation before committing transactions, providing optimal write performance while maintaining reasonable data protection.
Configuration Example:
-- Primary server postgresql.conf wal_level = replica max_wal_senders = 5 wal_keep_size = 1GB archive_mode = on archive_command = 'cp %p /var/lib/postgresql/archive/%f' -- Standby server postgresql.conf hot_standby = on max_standby_streaming_delay = 30s
Recovery Configuration:
# standby.signal file on replica standby_mode = 'on' primary_conninfo = 'host=primary-db.company.com port=5432 user=replicator' restore_command = 'cp /var/lib/postgresql/archive/%f %p'
This setup enables a standby server to continuously receive WAL records from the primary, typically with minimal lag under normal network conditions.
Synchronous Streaming Replication
For applications requiring zero data loss tolerance, synchronous replication ensures that transactions are committed only after at least one standby server confirms receipt of the WAL data.
Implementation Example:
-- Primary server configuration synchronous_standby_names = 'standby1,standby2' synchronous_commit = on -- Connection string for standby primary_conninfo = 'host=primary-db.company.com port=5432 user=replicator application_name=standby1'
Consider a financial trading application where transaction integrity is paramount. Synchronous replication ensures that every trade execution is safely replicated before confirmation, preventing data loss even during primary server failures.
Logical Replication: Flexible Data Distribution
Logical replication operates at the logical level, replicating specific tables or databases rather than the entire cluster. This approach enables selective data replication, cross-version replication, and complex data distribution scenarios.
Publication and Subscription Model
-- On the publisher (source database) CREATE PUBLICATION sales_data FOR TABLE orders, customers, products; -- On the subscriber (target database) CREATE SUBSCRIPTION sales_replica CONNECTION 'host=publisher.company.com dbname=sales user=replicator' PUBLICATION sales_data;
Use Case Example:
A multinational e-commerce platform uses logical replication to distribute regional customer data to local data centers. European customer data replicates to EU servers, while North American data stays within US boundaries, ensuring compliance with data sovereignty regulations.
Selective Table Replication
-- Replicate only specific columns CREATE PUBLICATION customer_basics FOR TABLE customers (customer_id, name, email); -- Replicate with row filtering (PostgreSQL 15+) CREATE PUBLICATION active_orders FOR TABLE orders WHERE status = 'active';
Advanced Replication Architectures
Cascading Replication
Cascading replication enables standby servers to act as sources for additional replicas, reducing load on the primary server and enabling complex geographic distributions.
# Primary server
primary-db (Region: US-East)
↓
# First-level standby
standby-us-west (Region: US-West)
↓
# Second-level standby
standby-eu (Region: Europe)
Configuration for cascading standby:
-- On the intermediate standby max_wal_senders = 3 wal_level = replica hot_standby = on
Multi-Master Logical Replication
For applications requiring write capabilities across multiple nodes, logical replication can create bi-directional or multi-directional replication topologies.
-- Node A publishes to Node B CREATE PUBLICATION node_a_pub FOR ALL TABLES; -- Node B publishes to Node A CREATE PUBLICATION node_b_pub FOR ALL TABLES; -- Conflict resolution through timestamps ALTER TABLE orders ADD COLUMN last_modified TIMESTAMP DEFAULT NOW();
Performance Optimization and Monitoring
WAL Configuration Tuning
-- Optimize WAL settings for replication performance wal_buffers = 64MB checkpoint_segments = 32 checkpoint_completion_target = 0.9 wal_writer_delay = 200ms
Monitoring Replication Lag
-- Monitor replication lag on primary
SELECT
client_addr,
application_name,
state,
pg_wal_lsn_diff(pg_current_wal_lsn(), flush_lsn) AS lag_bytes,
extract(epoch from (now() - backend_start)) AS connection_duration
FROM pg_stat_replication;
-- Monitor lag on standby
SELECT
pg_last_wal_receive_lsn(),
pg_last_wal_replay_lsn(),
pg_wal_lsn_diff(pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn()) AS replay_lag_bytes;
Connection Pooling for Replicas
# Example connection pooling configuration
import psycopg2.pool
# Separate pools for read and write operations
write_pool = psycopg2.pool.ThreadedConnectionPool(
1, 20,
host="primary-db.company.com",
database="production"
)
read_pool = psycopg2.pool.ThreadedConnectionPool(
1, 50,
host="replica-db.company.com",
database="production"
)
Security Considerations
SSL/TLS Configuration
-- Enable SSL for replication connections ssl = on ssl_cert_file = '/etc/postgresql/server.crt' ssl_key_file = '/etc/postgresql/server.key' ssl_ca_file = '/etc/postgresql/ca.crt'
Authentication and Authorization
# pg_hba.conf configuration hostssl replication replicator 10.0.0.0/8 cert hostssl replication replicator 192.168.1.0/24 md5
Network Security
-- Restrict replication connections listen_addresses = 'localhost,10.0.1.100' max_connections = 200
Automated Failover and High Availability
Patroni Configuration Example
# patroni.yml
scope: postgres-cluster
namespace: /db/
name: node1
restapi:
listen: 0.0.0.0:8008
connect_address: 10.0.1.100:8008
etcd:
hosts: 10.0.1.10:2379,10.0.1.11:2379,10.0.1.12:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 30
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
parameters:
max_connections: 200
shared_preload_libraries: pg_stat_statements
Health Check Scripts
#!/bin/bash
# PostgreSQL health check script
PGUSER="monitor"
PGDATABASE="postgres"
# Check if PostgreSQL is accepting connections
if ! pg_isready -h localhost -p 5432; then
echo "PostgreSQL is not accepting connections"
exit 1
fi
# Check replication lag
LAG=$(psql -t -c "SELECT EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp()))")
if (( $(echo "$LAG > 60" | bc -l) )); then
echo "Replication lag is too high: ${LAG}s"
exit 1
fi
echo "PostgreSQL health check passed"
exit 0
Troubleshooting Common Replication Issues
Replication Slot Management
-- Monitor replication slots
SELECT slot_name, plugin, slot_type, database, active, restart_lsn
FROM pg_replication_slots;
-- Clean up inactive slots
SELECT pg_drop_replication_slot('inactive_slot_name');
WAL Archive Recovery
-- Check WAL archive status SELECT archived_count, last_archived_wal, last_archived_time FROM pg_stat_archiver; -- Manual WAL file restoration restore_command = 'cp /backup/wal_archive/%f %p'
Split-Brain Prevention
# Fencing script example
#!/bin/bash
PRIMARY_IP="10.0.1.100"
STANDBY_IP="10.0.1.101"
# Check if both nodes think they're primary
if pg_controldata | grep "Database cluster state" | grep "in production"; then
# Implement fencing logic
echo "Potential split-brain detected"
# Stop PostgreSQL on this node
systemctl stop postgresql
fi
Best Practices for Production Deployments
Capacity Planning
- Network Bandwidth: Ensure sufficient bandwidth between primary and standby servers
- Storage Performance: Use SSDs for WAL files and high-IOPS storage for data directories
- Memory Allocation: Configure shared_buffers and effective_cache_size appropriately
Backup Strategy Integration
# Continuous archiving with compression archive_command = 'gzip < %p > /backup/wal_archive/%f.gz' # Point-in-time recovery preparation pg_basebackup -h primary-db.company.com -D /backup/base -Ft -z -P
Documentation and Runbooks
Maintain comprehensive documentation covering:
- Replication topology diagrams
- Failover procedures
- Recovery time objectives (RTO) and recovery point objectives (RPO)
- Emergency contact procedures
- Performance baseline metrics
Conclusion
PostgreSQL replication provides the foundation for building resilient, scalable database architectures. Whether implementing streaming replication for high availability or logical replication for complex data distribution scenarios, success depends on careful planning, proper configuration, and ongoing monitoring.
The key to effective PostgreSQL replication lies in understanding your specific requirements: data consistency needs, acceptable latency levels, geographic distribution requirements, and disaster recovery objectives. By combining these technical capabilities with robust monitoring, automated failover mechanisms, and comprehensive backup strategies, database professionals can build PostgreSQL systems that meet the most demanding enterprise requirements.
Regular testing of failover procedures, monitoring of replication performance, and staying current with PostgreSQL updates ensure that your replication infrastructure continues to provide reliable service as your organization grows and evolves.
Further Reading:
- Comprehensive Guide to MySQL to Amazon Redshift Data Replication Using Tungsten Replicator
- Useful CQLSH Commands for Everyday Use
- Transparent Data Encryption (TDE): The Ultimate Guide
- Troubleshooting Fragmented MongoDB Platforms: Expert Guide by MinervaDB Inc.
- Using Apache Kafka to Replicate Data from PostgreSQL to Microsoft SQL Server
- Understanding PostgreSQL Replication


