Dynamic Assortment Planning for Retailers: Leveraging Databricks to Optimize SKU Performance by Store Cluster
Introduction: The Strategic Imperative of Dynamic Assortment Planning
In today’s hyper-competitive fast-moving consumer goods (FMCG) landscape, one-size-fits-all product assortments are no longer viable. Global retailers face mounting pressure to deliver personalized shopping experiences while maintaining profitability, managing inventory efficiently, and minimizing waste. Static, centrally mandated SKU lineups often result in overstocking slow-moving items, understocking high-demand products, and ultimately, lost sales due to poor on-shelf availability.
Dynamic assortment planning emerges as a strategic solution—enabling retailers to tailor product offerings at the store or cluster level based on localized demand signals, demographic profiles, store capacity, and real-time sales performance. This shift from static to dynamic planning not only enhances customer satisfaction but also directly impacts key financial metrics such as sell-through rates, inventory turnover, and gross margin return on investment (GMROI).
For executives in sales and trade marketing, the ability to align product availability with consumer preferences at a granular level is no longer a luxury—it’s a necessity. However, achieving this requires overcoming significant data and operational challenges: integrating disparate data sources, ensuring data quality and timeliness, building predictive models at scale, and operationalizing insights across thousands of stores.
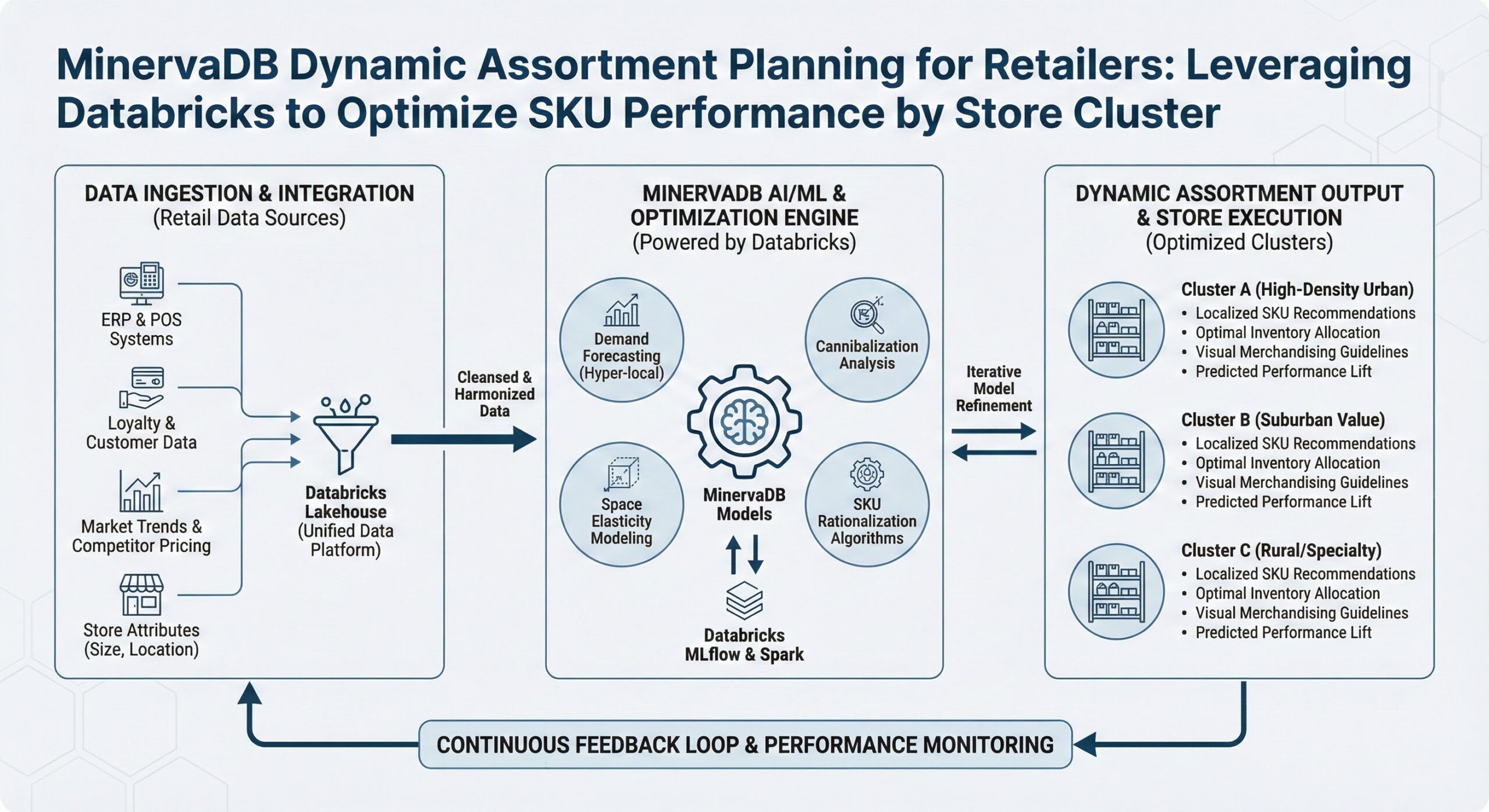
Enter Databricks—a unified data analytics platform that empowers global FMCG organizations to implement intelligent, scalable, and governed dynamic assortment strategies. By combining Delta Live Tables for robust data engineering, MLflow for end-to-end machine learning lifecycle management, and Unity Catalog for enterprise-grade data governance, Databricks provides the technical foundation needed to transform assortment planning from an art into a science.
This article explores how forward-thinking retailers are leveraging the Databricks Lakehouse Platform to build data-driven, localized assortment optimization systems that lift on-shelf availability, reduce excess inventory and returns, and drive revenue growth.
The Limitations of Traditional Assortment Planning
Historically, assortment decisions have been made using historical sales data aggregated at regional or national levels, often with minimal consideration for local market nuances. These decisions are typically updated quarterly or seasonally, relying on manual analysis and spreadsheet-based modeling. While this approach may suffice for stable markets with homogeneous consumer bases, it fails in environments characterized by:
- Demographic diversity: Urban stores serve different populations than suburban or rural locations, influencing preferences for product size, flavor, brand, and price point.
- Store format variation: Supercenters, convenience stores, and discount outlets have vastly different space constraints and customer traffic patterns.
- Cultural and regional preferences: In global FMCG operations, local tastes—such as spice levels in food, fragrance profiles in personal care, or packaging size—can vary dramatically even within the same country.
- Supply chain volatility: Disruptions can delay replenishment, exacerbating stockouts when demand spikes unexpectedly.
The consequences of suboptimal assortment planning are tangible:
- Lost sales due to out-of-stocks (OOS): Studies indicate that up to 8% of grocery purchases are abandoned when items are unavailable, costing retailers billions annually .
- Excess inventory and markdowns: Overestimating demand leads to surplus stock, which must be discounted or written off, eroding margins.
- Increased return rates: For suppliers operating under vendor-managed inventory (VMI) or compliance agreements, unsold goods are often returned, increasing reverse logistics costs.
- Poor space utilization: Shelf space occupied by low-turnover SKUs represents missed opportunities for more profitable products.
These challenges underscore the need for a more agile, data-informed approach—one that dynamically adjusts assortments based on real-time and predictive insights.
The Data Foundation: Integrating POS, Space, and Demographics
Effective dynamic assortment planning rests on three core data pillars:
- Point-of-Sale (POS) Data – Transaction-level records capturing what sold, when, where, and in what quantity.
- Store Space and Merchandising Data – Information about shelf dimensions, facings, planogram compliance, and display locations.
- Local Demographic and Geographic Data – Census data, income levels, population density, household composition, and lifestyle indicators tied to store catchment areas.
Integrating these datasets enables retailers to answer critical questions:
- Which SKUs perform best in high-income urban neighborhoods versus family-oriented suburbs?
- How does store size correlate with optimal category depth?
- Are there untapped demand opportunities for premium or value-tier products in specific clusters?
- Can we predict demand shifts before they occur?
However, integrating these sources is non-trivial. POS data arrives in high volume from thousands of registers; space data may reside in planogram systems or CAD tools; demographic data is often sourced from third parties and requires geospatial linking. Data quality issues—such as missing values, inconsistent formatting, or latency—further complicate analysis.
Delta Live Tables: Building Reliable, Scalable Data Pipelines
Databricks Delta Live Tables (DLT) addresses these integration challenges by providing a declarative framework for building automated, fault-tolerant data pipelines. With DLT, data engineers and analysts define transformations using simple SQL or Python syntax, and the platform handles orchestration, dependency management, data quality enforcement, and incremental processing automatically.
In the context of dynamic assortment planning, DLT can be used to construct a unified, curated dataset—often referred to as a “gold table”—that combines:
- Daily aggregated sales by SKU, store, and day
- Rolling velocity metrics (e.g., units sold per facing per week)
- Shelf capacity and planogram adherence metrics
- Enriched demographic attributes (e.g., median household income, education level, ethnic composition)
- Weather, seasonality, and promotional flags
DLT pipelines can include data quality expectations—for example, ensuring that total facings are positive, sales quantities are non-negative, or demographic data is available for all stores. When violations occur, DLT can quarantine bad records or trigger alerts, ensuring downstream models consume clean, reliable data.
Moreover, because DLT runs on the Lakehouse architecture, all data is stored in open formats (Delta Lake on cloud storage), enabling seamless access by multiple teams—from supply chain analysts to marketing strategists—without data silos.
Machine Learning for Assortment Optimization: The Role of MLflow
With a trusted, integrated dataset in place, the next step is to apply machine learning to predict demand, identify optimal SKUs, and simulate the impact of assortment changes.
Predictive Demand Modeling
Machine learning models can forecast SKU-level demand at the store level by learning from historical sales patterns, seasonality, promotions, weather, and demographic factors. For example, a gradient boosting model (e.g., XGBoost) or a deep learning architecture (e.g., Temporal Fusion Transformer) can be trained to predict weekly unit sales for each SKU in each store.
These models go beyond simple time-series forecasting by incorporating causal factors. For instance:
- A surge in plant-based milk sales in a neighborhood with a growing vegan population
- Increased demand for large-pack beverages in stores near stadiums on game days
- Higher sales of premium skincare in high-income ZIP codes
Assortment Recommendation Engine
Using predicted demand, retailers can build an optimization engine that recommends the best set of SKUs for each store or cluster, subject to constraints such as:
- Total shelf space available
- Minimum/maximum number of facings per SKU
- Category management rules (e.g., must carry at least one value, mainstream, and premium option)
- Supplier agreements or promotional commitments
This can be framed as a constrained optimization problem—maximizing expected sales or gross margin while respecting space and business rules. Techniques such as integer programming or heuristic search algorithms can be employed to generate optimal or near-optimal solutions.
Store Clustering for Scalable Execution
Managing assortments at the individual store level is ideal but often impractical due to operational complexity. Instead, retailers group stores into clusters based on shared characteristics such as:
- Demographic profile (income, age, ethnicity)
- Store size and format
- Sales volume and category mix
- Geographic region
Clustering reduces the number of unique assortments while preserving localization benefits. Algorithms like K-means, hierarchical clustering, or Gaussian mixture models can be used to form statistically coherent clusters.
Once clusters are defined, the ML model can recommend a tailored assortment for each cluster, which is then deployed across all stores within it.
MLflow: Managing the Machine Learning Lifecycle
Implementing and maintaining these models at scale requires robust MLOps practices. MLflow, an open-source platform integrated natively into Databricks, provides end-to-end capabilities for:
- Experiment Tracking: Log parameters, metrics, and artifacts (e.g., feature sets, model binaries) for every training run, enabling comparison across model versions .
- Model Registry: Centralize model lifecycle management with stages (e.g., Staging, Production), versioning, and annotations (e.g., “approved for cluster A”).
- Model Serving: Deploy models as REST APIs for real-time inference (e.g., dynamic demand prediction) or batch scoring (e.g., weekly assortment recommendations).
- Reproducibility: Capture the full context of each experiment—including code, environment, and data version—ensuring auditability and compliance.
For example, a data science team can use MLflow to:
- Train multiple demand forecasting models (ARIMA, Prophet, XGBoost) and compare their accuracy using RMSE and MAPE metrics.
- Register the best-performing model and promote it to production.
- Monitor model performance over time and trigger retraining when drift is detected.
- Serve the model to generate weekly assortment recommendations for each store cluster.
This level of automation and governance is critical for maintaining model reliability in a production environment.
Ensuring Trust and Compliance with Unity Catalog
As retailers collect and analyze increasingly sensitive data—including demographic information and purchasing behavior—data governance becomes paramount. Regulatory requirements such as GDPR, CCPA, and industry-specific standards demand strict access controls, audit trails, and data lineage.
Unity Catalog, Databricks’ unified governance solution, provides a centralized interface for managing data access, security, and compliance across the entire Lakehouse.
Key capabilities include:
- Fine-Grained Access Control: Define row- and column-level security policies (e.g., “marketing team can view aggregated sales but not individual transactions”).
- Data Lineage and Impact Analysis: Trace how raw POS data flows through DLT pipelines into ML training datasets and ultimately influences assortment decisions.
- Audit Logging: Track who accessed what data and when, supporting compliance reporting.
- PII Detection and Masking: Automatically identify personally identifiable information and apply masking or redaction.
For the VP of Sales or Trade Marketing, Unity Catalog ensures that data-driven decisions are made on trustworthy, compliant data. It also facilitates cross-functional collaboration—enabling merchandising, supply chain, and finance teams to access the same governed datasets without duplicating efforts or risking data breaches.
Operationalizing Insights: From Model to Merchandising Action
Building accurate models is only half the battle. The real value lies in operationalizing insights—turning model outputs into actionable merchandising plans.
Integration with Merchandising Systems
Assortment recommendations generated by the ML system must be integrated with downstream systems such as:
- Planogram software (e.g., JDA Space Planning, NielsenIQ)
- Inventory and replenishment systems
- Supplier collaboration portals
This integration can be achieved via APIs or batch file exports. For example, the Databricks pipeline can output a CSV or Parquet file containing the recommended SKUs, facings, and locations for each store cluster, which is then ingested into the planogram tool.
Closed-Loop Learning and Continuous Improvement
To ensure sustained performance, the system should incorporate feedback loops:
- Actual vs. Predicted Sales: After new assortments are deployed, compare actual sales against forecasts to measure lift.
- On-Shelf Availability (OSA) Metrics: Monitor OSA rates before and after changes to assess improvement.
- Return Rate Analysis: Track whether optimized assortments reduce unsold inventory and returns.
These metrics can be fed back into the ML model as new training data, enabling continuous learning and refinement.
Change Management and Stakeholder Adoption
Even the most sophisticated system will fail without buy-in from store operations, category managers, and suppliers. Key success factors include:
- Transparent model logic: Provide explainability (e.g., SHAP values) to show why certain SKUs were added or removed.
- Pilot programs: Test the system in a subset of stores to demonstrate ROI before full rollout.
- Training and support: Equip field teams with tools and knowledge to implement new assortments correctly.
Business Impact: Measurable Outcomes for Sales and Trade Marketing
When implemented effectively, dynamic assortment planning powered by Databricks delivers tangible business results:
1. Improved On-Shelf Availability
By aligning inventory more closely with localized demand, retailers can reduce stockouts. For example, a global beverage company using Databricks reported a 15% improvement in OSA for key SKUs within six months of deployment .
2. Reduced Excess Inventory and Returns
Optimized assortments minimize overstocking of slow-moving items. One FMCG retailer reduced returns to suppliers by 22% by eliminating SKUs with consistently low turnover in specific regions .
3. Increased Sales and Margin
Carrying the right products in the right stores drives incremental sales. A case study from a multinational grocery chain showed a 5.8% increase in category sales after implementing cluster-based assortment optimization .
4. Enhanced Supplier Collaboration
Data-driven recommendations provide objective justification for SKU inclusion or removal, improving transparency and trust with suppliers. Shared analytics dashboards can align trade marketing investments with actual performance.
5. Faster Time-to-Market for New Products
Machine learning models can simulate the potential performance of new SKUs in different clusters before launch, enabling targeted rollouts and reducing the risk of nationwide failures.
Real-World Example: Global Beverage Company
Consider a global beverage manufacturer selling carbonated soft drinks, juices, and bottled water across 10,000 retail outlets. Historically, the company used a regional assortment model with limited variation.
Using Databricks, they implemented the following:
- Data Integration: Ingested daily POS data, store space metrics, and U.S. Census demographics into Delta Lake via DLT pipelines.
- Store Clustering: Applied K-means clustering on demographic and sales variables to form 12 distinct store clusters.
- Demand Forecasting: Trained XGBoost models in MLflow to predict weekly unit sales for 200 SKUs across clusters.
- Assortment Optimization: Built a Python-based optimizer to recommend SKUs and facings per cluster, maximizing predicted sales under space constraints.
- Governance: Used Unity Catalog to manage access to sensitive demographic data and ensure compliance.
Results after one year:
- 18% reduction in out-of-stocks for top 50 SKUs
- 14% decrease in inventory carrying costs
- 7.2% increase in category revenue
- 30% faster decision cycle for assortment reviews
Implementation Roadmap
Organizations looking to adopt dynamic assortment planning on Databricks can follow a phased approach:
Phase 1: Data Foundation (Weeks 1–8)
- Identify and ingest core data sources (POS, space, demographics)
- Build DLT pipelines to create curated, gold-standard datasets
- Implement data quality checks and monitoring
Phase 2: Analytics and Clustering (Weeks 9–12)
- Perform exploratory data analysis (EDA) to understand demand patterns
- Develop store clustering model and validate cluster coherence
- Define key performance indicators (KPIs) for success
Phase 3: Machine Learning Development (Weeks 13–20)
- Train and validate demand forecasting models using MLflow
- Develop assortment optimization logic
- Conduct A/B testing on pilot clusters
Phase 4: Integration and Deployment (Weeks 21–24)
- Integrate recommendations with planogram and replenishment systems
- Deploy models into production using MLflow Model Serving
- Establish monitoring for model performance and data drift
Phase 5: Scale and Optimize (Ongoing)
- Expand to additional categories and geographies
- Incorporate new data sources (e.g., weather, social trends)
- Refine models based on feedback and performance
Challenges and Mitigations
While the benefits are compelling, implementation challenges exist:
- Data Silos: Legacy systems may resist integration. Mitigation: Use Databricks’ connectors for ERP, POS, and CRM systems.
- Change Resistance: Merchandisers may distrust algorithmic recommendations. Mitigation: Co-develop models with domain experts and provide explainability.
- Model Complexity: Overfitting or poor generalization can occur. Mitigation: Use cross-validation, regularization, and holdout testing.
- Latency Requirements: Some retailers need near-real-time updates. Mitigation: Use streaming DLT pipelines and low-latency model serving.
Conclusion: The Future of Retail Assortment is Dynamic, Data-Driven, and Unified
Dynamic assortment planning represents a paradigm shift in how FMCG retailers approach product availability and customer satisfaction. By moving beyond static, one-size-fits-all strategies, organizations can unlock significant value through improved on-shelf availability, reduced waste, and higher sales.
Databricks provides the ideal platform for this transformation—unifying data engineering (Delta Live Tables), machine learning (MLflow), and governance (Unity Catalog) in a single, scalable environment. For VPs of Sales and Trade Marketing, this means access to actionable, localized insights that drive both top-line growth and operational efficiency.
The retailers who succeed in the next decade will be those who treat data not as a byproduct of transactions, but as a strategic asset. With Databricks, global FMCG companies can turn vast amounts of POS, space, and demographic data into intelligent, adaptive assortment strategies that resonate with local consumers and deliver measurable business outcomes.
The future of retail is not just personalized—it’s predictive, automated, and continuously optimized. And it starts with dynamic assortment planning on the Databricks Lakehouse Platform.
Further Reading
From XL to XS: A Practical Guide to Rightsizing Snowflake
Leveraging Snowflake Optima for Intelligent Workload Optimization
Deep Dive into RocksDB’s LSM-Tree Architecture
Design Scalable Soft Deletes and Audit Logs for MongoDB


