Patterns for High-Performance SQL on SAP HANA: Mastering Set-Based Design, SQLScript, and Table Functions
SAP HANA’s in-memory architecture revolutionizes database performance, but achieving optimal results requires understanding specific patterns and techniques. This comprehensive guide explores proven strategies for high-performance SQL on HANA, focusing on set-based design principles, avoiding row-by-row logic, and leveraging SQLScript and table functions effectively.
The SAP HANA Performance Guide for Developers provides an overview of key features and characteristics from a performance perspective, highlighting SAP HANA-specific optimization aspects that differentiate it from traditional relational databases.
Understanding SAP HANA’s Architecture for Performance
The Foundation: Column Store Optimization
SAP HANA’s default columnar storage provides superior aggregation and scan performance for analytical workloads while maintaining high throughput for transactional operations. The columnar storage is particularly beneficial for analytical (OLAP) workloads, offering sophisticated data compression capabilities that significantly reduce main memory footprint.
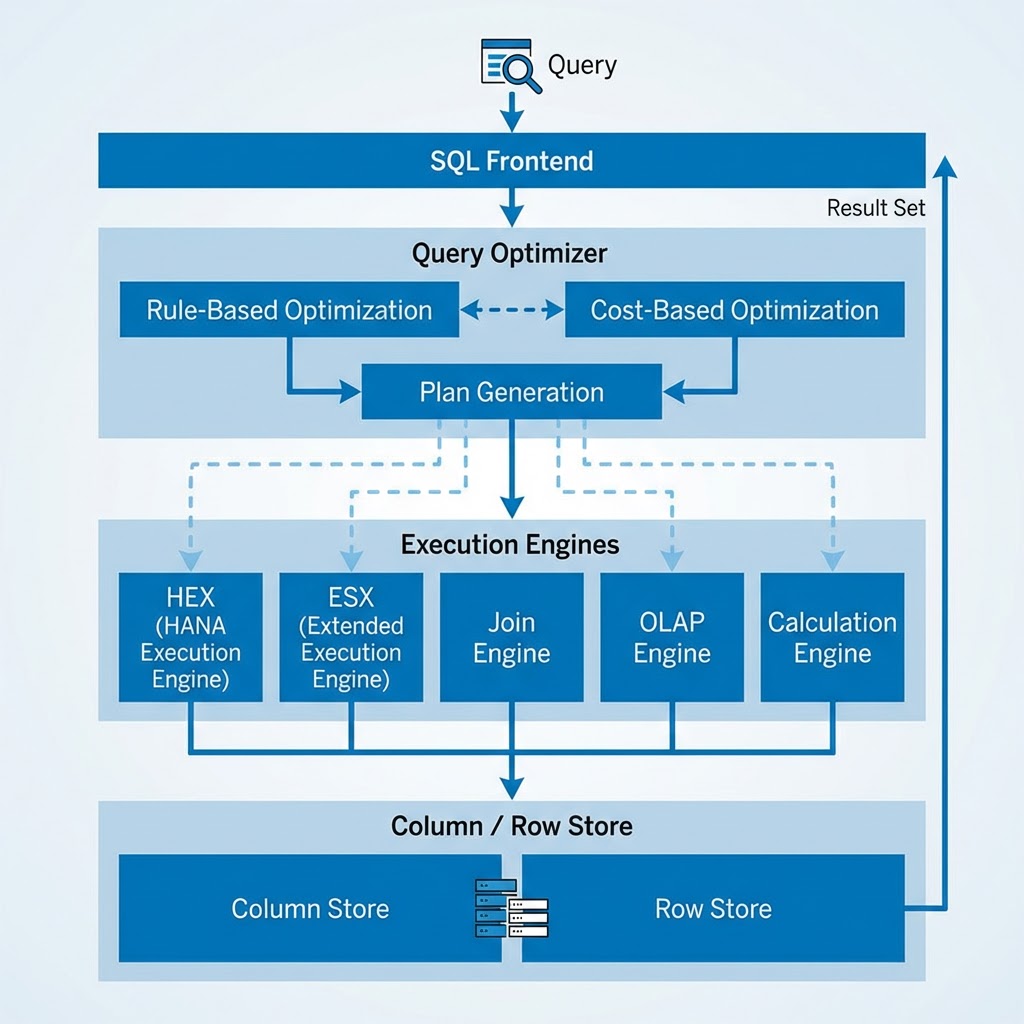
Query Processing Engines
SAP HANA utilizes multiple execution engines including the SAP HANA Extended SQL Executor (ESX), SAP HANA Execution Engine (HEX), join engine, OLAP engine, and calculation engine. The optimizer automatically routes queries to the most appropriate engine based on cost-based decisions.
Set-Based Design vs Row-by-Row Processing
The Performance Paradigm Shift
HANA databases can process set-based data faster than row-by-row operations. This fundamental principle should guide all SQL development on HANA platforms. The performance difference can be dramatic, with set-based operations often outperforming cursor-based approaches by orders of magnitude.
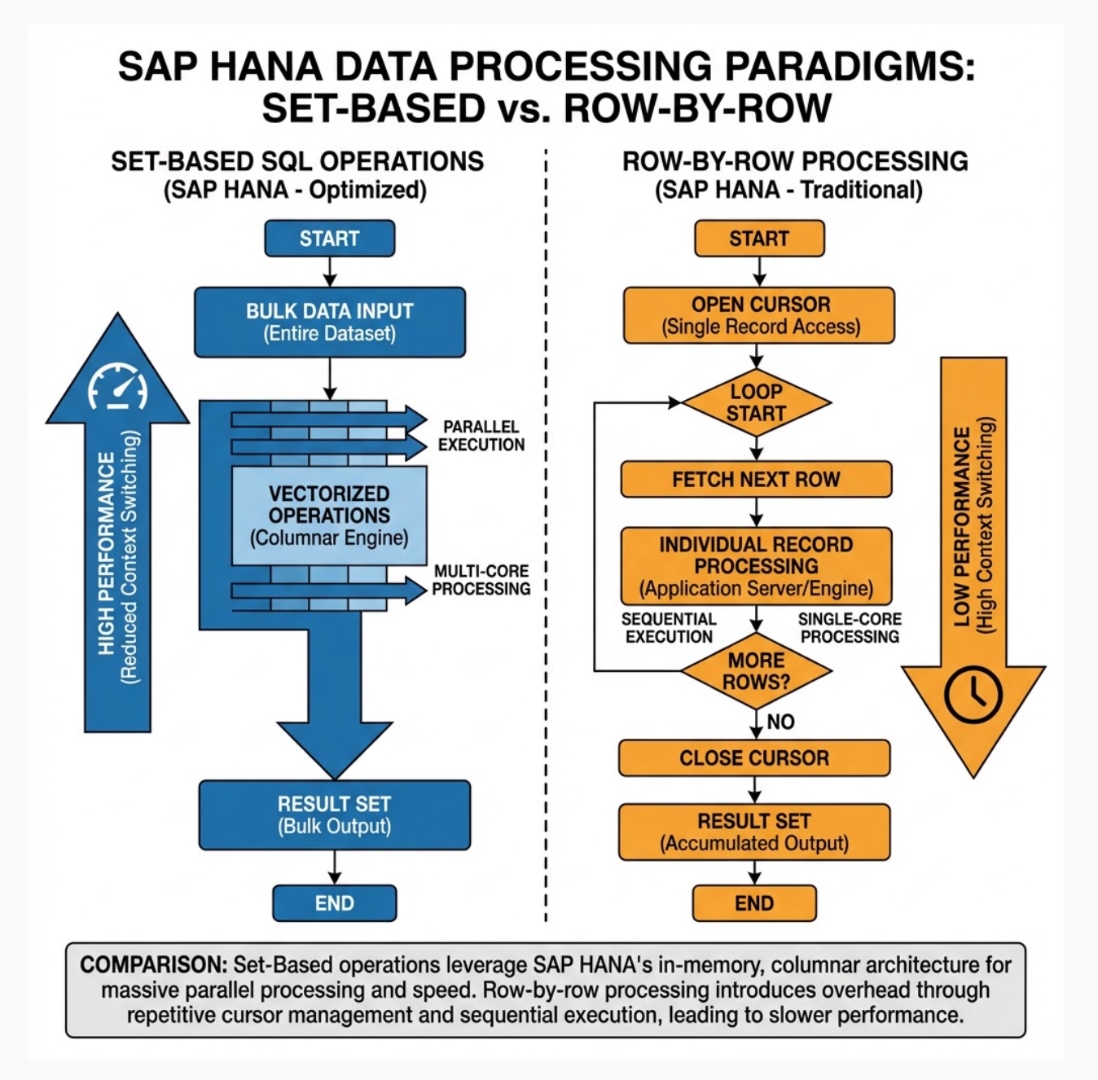
Why Set-Based Operations Excel
- Vectorized Processing: Set-based operations leverage HANA’s vectorized processing capabilities, allowing multiple values to be processed simultaneously using SIMD (Single Instruction, Multiple Data) instructions.
- Parallel Execution: The SAP HANA database scan operators use SIMD instructions during processing, enabling multiple-value comparisons simultaneously, depending on the number of bits required for representing an entry.
- Memory Efficiency: Set-based operations minimize data movement and intermediate result materialization, crucial for in-memory processing.
Avoiding Row-by-Row Anti-Patterns
- Cursor Elimination: There is almost always another way to rewrite cursors in a more efficient manner. Check whether cursors can be replaced with simple SELECT, UPDATE, or DELETE statements, or nested cursors with JOIN or subselect operations.
- Procedural Logic Transformation: Convert procedural loops into declarative SQL statements that can be optimized by HANA’s cost-based optimizer.
SQLScript: HANA’s Procedural Extension
SQLScript Fundamentals
SQLScript optimizations cover how dataflow exploits parallelism in the SAP HANA database. The language is designed to leverage HANA’s unique architecture while maintaining SQL compatibility.
Performance Optimization Patterns
- Dataflow Optimization: SQLScript procedures benefit from dataflow optimization, where the optimizer can parallelize operations across multiple execution threads.
- Statement Inlining: The use of inlining, parameterized queries, and SQL hints can help improve the performance of SQLScript procedures.
Best Practices for SQLScript Development
| Practice | Description | Performance Impact |
|---|---|---|
| Reduce Complexity | Simplify SQL statements to enable better optimization | High |
| Identify Common Sub-Expressions | Reuse calculated expressions to minimize redundant processing | Medium |
| Multi-Level Aggregation | Optimize aggregation hierarchies for better performance | High |
| Reduce Dependencies | Minimize inter-statement dependencies to enable parallelization | High |
| Avoid Dynamic SQL | Use static SQL whenever possible for better plan caching | Medium |
SQLScript Anti-Patterns to Avoid
SQLScript performance issues are often associated with anti-patterns that prevent optimal execution plans. Common anti-patterns include:
- Excessive use of cursors for row-by-row processing
- Dynamic SQL generation within loops
- Unnecessary intermediate table variables
- Inefficient exception handling patterns
Table Functions: The Performance Powerhouse
Understanding Table Functions
Table functions are used whenever graphical views are not sufficient, particularly for loops, executing custom functions, or complex queries. They provide superior performance compared to traditional calculation views for complex analytical scenarios.
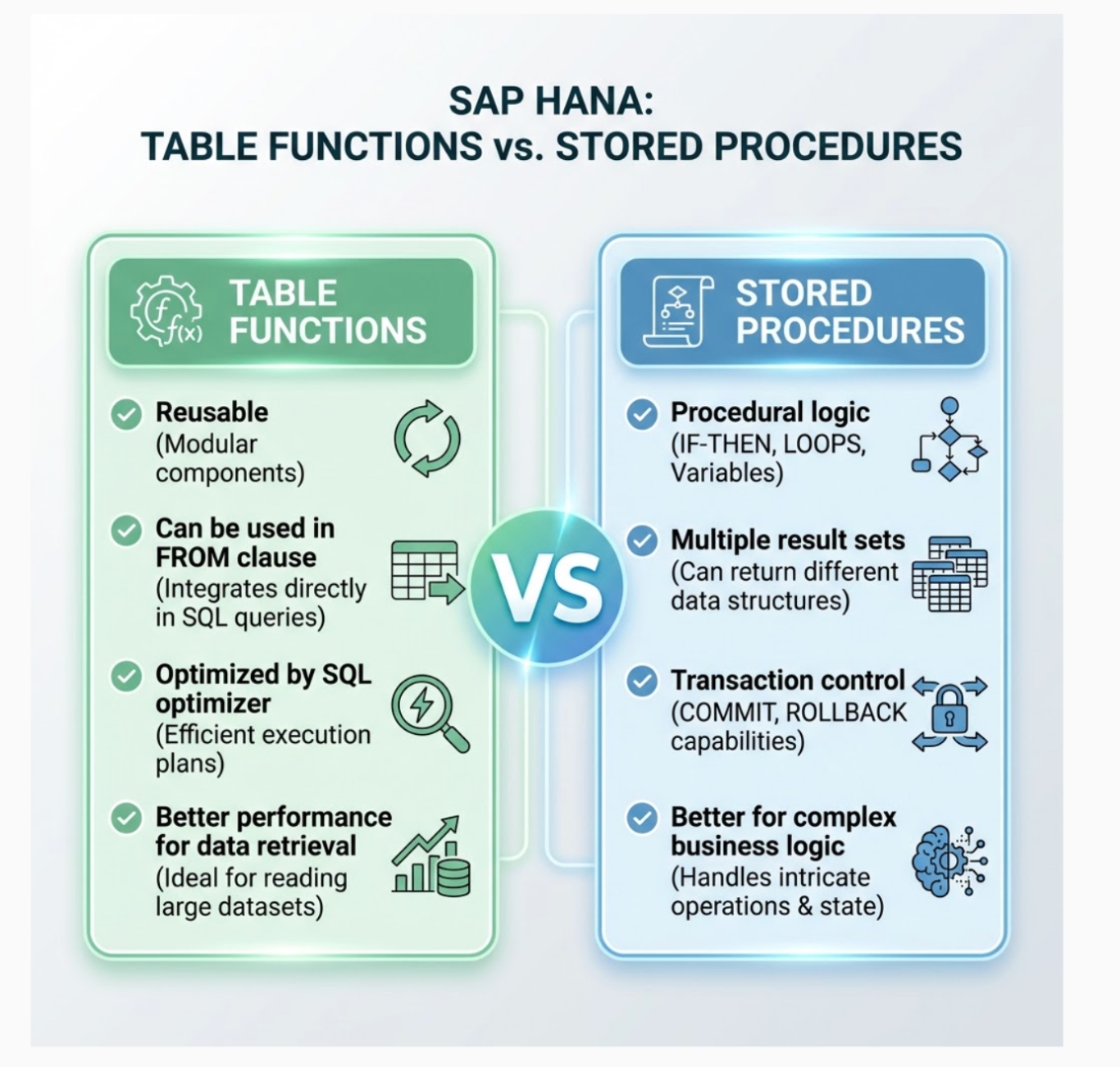
Advantages of Table Functions
- SQL Optimizer Integration: Table functions can be fully optimized by HANA’s SQL optimizer, unlike some calculation view patterns.
- Reusability: Functions can be used in FROM clauses, making them highly reusable across different queries.
- Parameter Optimization: HANA provides migration tools that enable automatic conversion of script-based calculation views into table functions.
Implementation Best Practices
- Efficient Parameter Handling: Design table functions with optimal parameter structures to minimize compilation overhead.
- Result Set Optimization: Structure return tables to align with expected query patterns and indexing strategies.
- Memory Management: Implement efficient memory usage patterns to prevent performance degradation with large result sets.
Performance Considerations
While table functions generally provide excellent performance, some scenarios may require careful tuning. Monitor execution plans and consider factors such as:
- Parameter selectivity
- Result set size
- Join complexity
- Aggregation requirements
Advanced Optimization Techniques
Column Store Specific Optimizations
- Dictionary Compression: The SAP HANA column store uses dictionary compression to reduce memory overhead when storing redundant data, making denormalization less costly than in row stores.
- Partition Pruning: Partitioning can dramatically improve processing times by ruling out irrelevant partitions during query execution, but only when query predicates match partitioning criteria.
- Index Strategy: Create as few indexes as possible, ensure indexes are as small as possible, and prefer single-column indexes in the column store due to their lower space overhead.
Query Optimization Strategies
- Cost-Based Optimization: The SAP HANA SQL optimizer uses both rule-based and cost-based optimization, with cost-based optimization involving size and cost estimation of each subtree to choose the least costly plan.
- Execution Engine Selection: The optimizer automatically selects between different execution engines (HEX, ESX, join engine, OLAP engine) based on query characteristics and estimated costs.
Performance Monitoring and Analysis
Essential Monitoring Tools
- SQL Plan Cache: The SAP HANA SQL process utilizes plan caching to minimize compilation time and improve overall query performance.
- Plan Visualizer: Visual analysis of execution plans helps identify performance bottlenecks and optimization opportunities.
- SQL Trace: Performance analysis tools help understand and optimize query performance, including runtime key performance indicators (KPIs).
Performance Metrics to Track
| Metric | Description | Optimization Target |
|---|---|---|
| Compilation Time | Time spent optimizing queries | Minimize through plan caching |
| Execution Time | Actual query runtime | Optimize through better algorithms |
| Memory Usage | Peak memory consumption | Reduce through efficient operations |
| CPU Utilization | Processor usage patterns | Balance through parallelization |
Real-World Implementation Examples
Example 1: Converting Cursor Logic to Set-Based Operations
Before (Row-by-Row):
-- Anti-pattern: Cursor-based processing DECLARE CURSOR c_orders FOR SELECT order_id, customer_id, order_amount FROM orders; FOR order_rec AS c_orders DO UPDATE customer_summary SET total_orders = total_orders + order_rec.order_amount WHERE customer_id = order_rec.customer_id; END FOR;
Example 2: Efficient Table Function Implementation
CREATE FUNCTION calculate_customer_metrics(
IN start_date DATE,
IN end_date DATE
) RETURNS TABLE (
customer_id BIGINT,
total_revenue DECIMAL(15,2),
order_count INTEGER,
avg_order_value DECIMAL(15,2)
) AS
BEGIN
RETURN SELECT
customer_id,
SUM(order_amount) as total_revenue,
COUNT(*) as order_count,
AVG(order_amount) as avg_order_value
FROM orders
WHERE order_date BETWEEN :start_date AND :end_date
GROUP BY customer_id;
END;
Performance Tuning Methodology
Systematic Approach to Optimization
- Baseline Measurement: Establish current performance metrics
- Bottleneck Identification: Use HANA monitoring tools to identify constraints
- Pattern Analysis: Review code for anti-patterns and optimization opportunities
- Incremental Optimization: Apply changes systematically and measure impact
- Validation: Ensure optimizations don’t compromise data integrity
Common Performance Bottlenecks
- Memory Pressure: Large intermediate results can cause memory pressure, particularly in complex joins or aggregations.
- Inefficient Joins: Cross-engine joins between row and column store tables cannot be handled with the same efficiency as homogeneous joins.
- Suboptimal Partitioning: Partitioning may increase memory consumption if partitioning criteria don’t align with query patterns.
Advanced SQLScript Patterns
Parallel Processing Techniques
SQLScript supports parallel operators including Map Merge and Map Reduce operators that can significantly improve performance for suitable workloads.
Map Merge Pattern:
-- Parallel processing with Map Merge DECLARE lt_results TABLE LIKE target_table; lt_results = MAP_MERGE(:source_table, process_partition(:source_table));
Dynamic SQL Optimization
When dynamic SQL is necessary, optimize by using input and output parameters effectively and minimizing the scope of dynamic elements.
Column Store Memory Management
Efficient Memory Usage
- Each column store table consists of delta and main table parts, with automatic delta merges improving query processing times and reducing memory consumption.
- Delta Merge Optimization: Monitor delta table sizes and trigger merges when beneficial for query performance.
- Compression Strategies: Leverage HANA’s multiple compression methods (run length encoding, sparse coding, default value) for optimal memory utilization.
- Future-Proofing Your HANA SQL
Staying Current with Engine Evolution
New query processing engines (ESX and HEX) are being phased in to offer better performance while maintaining functionality compatibility.
Monitoring and Adaptation
Regular performance reviews ensure that optimization strategies remain effective as:
- Data volumes grow
- Query patterns evolve
- HANA platform capabilities expand
- Business requirements change
Conclusion
Achieving high-performance SQL on SAP HANA requires a fundamental shift from traditional row-by-row processing to set-based thinking. By leveraging SQLScript’s dataflow optimization capabilities, implementing efficient table functions, and following column store best practices, organizations can unlock HANA’s full potential.
The key to success lies in understanding that SAP HANA’s in-memory architecture, combined with its sophisticated optimization engines, rewards developers who embrace set-based design patterns and avoid traditional procedural anti-patterns.
Success metrics should focus on:
- Minimizing compilation and execution times
- Optimizing memory usage patterns
- Leveraging parallel processing capabilities
- Maintaining code maintainability and scalability
By following these patterns and continuously monitoring performance, organizations can build robust, high-performance analytical solutions that scale with their business needs while maximizing their SAP HANA investment.
The journey to HANA performance excellence is iterative, requiring ongoing attention to emerging patterns, platform capabilities, and business requirements. However, the foundation of set-based design, efficient SQLScript usage, and strategic table function implementation provides a solid base for sustained high performance.
Further Reading
