Unlocking AI Potential: A Complete Guide to Vector Databases Capabilities in PostgreSQL
The landscape of database management is rapidly evolving as artificial intelligence applications become integral to modern business operations. Traditional relational databases, while excellent for structured data, face challenges when handling the complex vector data that powers AI and machine learning systems. This comprehensive guide explores how PostgreSQL can be enhanced to meet these emerging requirements through specialized vector extensions.
Understanding Vector Data in Modern Database Systems
Vector data represents information as numerical arrays that capture semantic relationships and patterns within multi-dimensional space. Unlike traditional database entries that store discrete values, vectors encode meaning through their position and distance from other vectors in high-dimensional space.
This approach enables databases to understand conceptual similarities rather than just exact matches. For instance, when searching for “automobile,” a vector-enabled system can identify related concepts like “car,” “vehicle,” or “transportation” based on their mathematical proximity in vector space.
The Evolution of PostgreSQL for AI Applications
PostgreSQL has established itself as a robust, enterprise-grade database solution trusted by organizations worldwide. However, the growing demand for AI-powered applications has revealed the need for native vector processing capabilities within traditional database systems.
Key Advantages of Vector-Enhanced PostgreSQL:
- Unified data architecture combining relational and vector data
- Reduced system complexity by eliminating multiple database dependencies
- Leveraged existing expertise in PostgreSQL administration
- Cost-effective scaling using familiar infrastructure
- Enterprise-grade security and reliability features
Core Concepts of Vector Similarity Operations
Vector similarity search forms the foundation of numerous AI applications that users interact with daily. These operations enable systems to identify relationships and patterns that would be impossible to detect through traditional query methods.
Common Vector Applications Include:
- Personalized recommendation systems for e-commerce and content platforms
- Intelligent search functionality that understands user intent
- Content classification and automated tagging systems
- Fraud detection through pattern recognition
- Natural language understanding for chatbots and virtual assistants
The mathematical principles underlying vector operations allow systems to quantify similarity between different pieces of content, enabling sophisticated matching algorithms that improve user experiences across various applications.
Technical Architecture of Vector Database Extensions
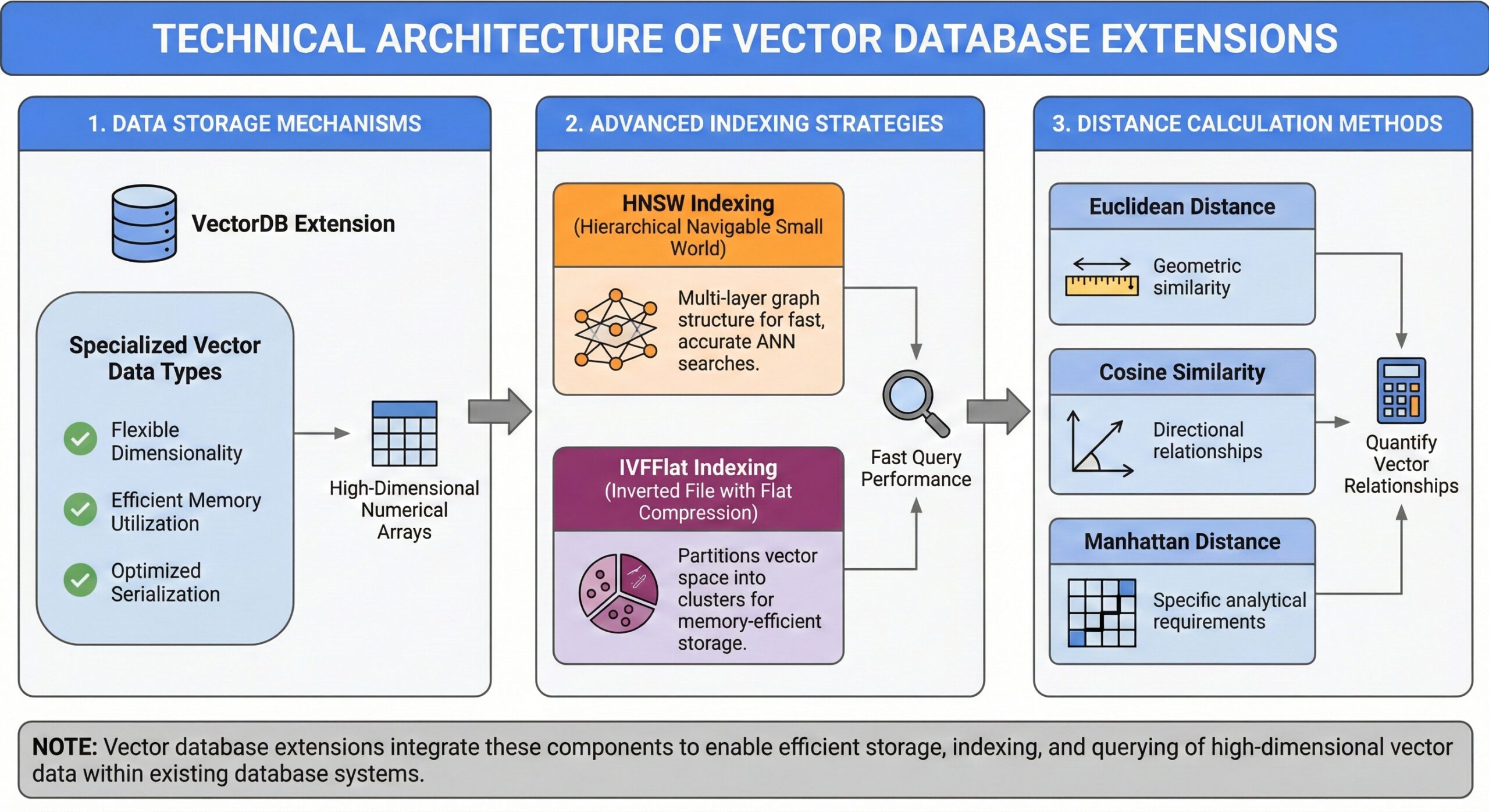
Data Storage Mechanisms
Vector database extensions introduce specialized data types designed to efficiently store high-dimensional numerical arrays. These data types are optimized for the specific requirements of vector operations, including:
- Flexible dimensionality to accommodate various embedding models
- Efficient memory utilization for large-scale datasets
- Optimized serialization for fast read and write operations
Advanced Indexing Strategies
Specialized indexing algorithms are crucial for maintaining query performance as vector datasets grow. Two primary approaches dominate the field:
Hierarchical Navigable Small World (HNSW) Indexing
This approach creates a multi-layer graph structure that enables efficient approximate nearest neighbor searches. HNSW indexes excel in scenarios requiring fast query responses with high accuracy.
Inverted File with Flat Compression (IVFFlat) Indexing
This method partitions the vector space into clusters, allowing for memory-efficient storage and retrieval. IVFFlat indexes are particularly effective for large datasets where memory constraints are a primary concern.
Distance Calculation Methods
Vector similarity relies on mathematical distance functions that quantify relationships between vectors:
- Euclidean distance for geometric similarity
- Cosine similarity for directional relationships
- Manhattan distance for specific analytical requirements
Implementation Workflow for Vector-Enabled Databases
Phase 1: Data Preparation and Schema Design
The implementation process begins with careful schema planning that accommodates both traditional relational data and vector representations. This involves:
- Identifying data sources that will generate vector embeddings
- Designing table structures that efficiently store vectors alongside metadata
- Planning for scalability as data volumes increase over time
Phase 2: Embedding Generation Pipeline
Machine learning models transform raw data into numerical vector representations through a process called embedding generation. This critical step involves:
- Selecting appropriate embedding models based on data type and use case
- Establishing consistent preprocessing procedures for data normalisation
- Implementing batch processing systems for efficient embedding generation
Phase 3: Vector Storage and Optimisation
Once embeddings are generated, they must be stored and indexed efficiently within the database system. Key considerations include:
- Choosing optimal vector dimensions balancing accuracy and performance
- Implementing appropriate indexing strategies based on query patterns
- Configuring memory allocation for optimal system performance
Phase 4: Query Implementation and Tuning
The final phase involves developing efficient query patterns that leverage vector similarity operations:
- Designing similarity thresholds that balance precision and recall
- Optimizing query performance through proper index utilization
- Implementing result ranking algorithms for improved user experience
Performance Optimization Strategies
Hardware Considerations
Vector operations are computationally intensive and benefit significantly from proper hardware configuration:
- Sufficient RAM allocation for in-memory index operations
- Fast storage systems to minimize I/O bottlenecks
- Multi-core processors for parallel vector calculations
Query Optimization Techniques
Efficient query design is crucial for maintaining system responsiveness:
- Limiting result sets to reasonable sizes
- Using appropriate similarity thresholds to filter irrelevant results
- Implementing query caching for frequently accessed patterns
Index Maintenance Strategies
Regular index maintenance ensures continued optimal performance:
- Monitoring index fragmentation and rebuilding when necessary
- Adjusting index parameters based on changing data patterns
- Implementing automated maintenance procedures for large-scale deployments
Real-World Application Scenarios
E-commerce Recommendation Systems
Product recommendation engines leverage vector similarity to suggest relevant items based on user behavior and product characteristics. This application demonstrates how vector databases can drive revenue growth through improved customer engagement.
Content Management and Search
Intelligent content discovery systems use vector embeddings to understand document semantics, enabling users to find relevant information even when using different terminology than what appears in the source material.
Fraud Detection and Security
Pattern recognition systems analyze transaction vectors to identify suspicious activities that might indicate fraudulent behavior, providing enhanced security for financial institutions and e-commerce platforms.
Scalability and Enterprise Considerations
Data Volume Management
Large-scale vector deployments require careful planning for data growth:
- Partitioning strategies for distributing vector data across multiple nodes
- Archival procedures for managing historical vector data
- Backup and recovery plans specific to vector data requirements
Integration with Existing Systems
Seamless integration with current infrastructure is essential for successful adoption:
- API compatibility with existing applications
- Data migration strategies for transitioning from legacy systems
- Staff training programs for database administrators and developers
Monitoring and Observability
Comprehensive monitoring ensures system health and performance:
- Query performance metrics for identifying optimization opportunities
- Resource utilization tracking for capacity planning
- Error monitoring for proactive issue resolution
Future Trends and Developments
Emerging Technologies
Continuous innovation in vector database technology promises exciting developments:
- Improved indexing algorithms for better performance and accuracy
- Enhanced compression techniques for reduced storage requirements
- Advanced query optimization methods for complex similarity operations
Industry Adoption Patterns
Growing market demand for AI-powered applications drives increased adoption of vector database technologies across various industries, from healthcare and finance to entertainment and manufacturing.
Best Practices for Implementation Success
Planning and Design
Thorough planning is essential for successful vector database implementation:
- Clear requirement definition for performance and functionality expectations
- Proof of concept development to validate technical approaches
- Stakeholder alignment on project goals and success metrics
Development and Testing
Rigorous testing procedures ensure system reliability:
- Performance benchmarking under realistic load conditions
- Accuracy validation of similarity search results
- Stress testing for system limits and failure scenarios
Deployment and Maintenance
Careful deployment planning minimizes risks and ensures smooth operations:
- Gradual rollout strategies for large-scale implementations
- Comprehensive documentation for operational procedures
- Regular performance reviews and optimization cycles
Conclusion: Transforming Database Capabilities for the AI Era
The integration of vector processing capabilities into traditional database systems represents a fundamental shift in how organizations approach data management. By combining the reliability and familiarity of established database technologies with the power of vector similarity operations, businesses can unlock new possibilities for AI-driven applications.
This transformation enables organizations to maintain unified data architectures while embracing cutting-edge AI technologies. The result is reduced complexity, improved efficiency, and enhanced capabilities that drive innovation across industries.
As artificial intelligence continues to evolve and mature, vector-enhanced databases will play an increasingly critical role in enabling organizations to harness the full potential of their data assets. The investment in these technologies today positions businesses for success in an AI-driven future, providing the foundation for intelligent applications that deliver exceptional user experiences and competitive advantages.
The journey toward AI-enabled database systems requires careful planning, technical expertise, and strategic vision. However, the rewards – in terms of enhanced capabilities, improved efficiency, and new business opportunities – make this transformation not just beneficial, but essential for organizations seeking to thrive in the digital age.
Further Reading
25 Advanced MySQL DBA Questions and Answers: Master Database Administration
Generating Numeric Sequences in MySQL: A Comprehensive Guide
Best Practices for Managing MongoDB Log Files and System Resources
An Overview of DDL Algorithms in MySQL 8: Enhancing Schema Changes


