Here's the short version: most PostgreSQL teams approach postgresql cutover runbook by tweaking one knob and hoping. What follows is the longer, more useful version, drawn from production PostgreSQL deployments with banks, fintechs, and SaaS platforms running PostgreSQL at scale.
Quick answer
Postgresql cutover runbook in PostgreSQL is a measurement problem first and a tuning problem second. Pull a 30-minute baseline from pg_stat_statements and pg_wait_sampling, locate the responsible subsystem, change one variable at a time, and verify against the baseline before you ship the next tweak. The diagnostic queries are below.
What is postgresql cutover runbook?
Postgresql cutover runbook describes how PostgreSQL handles Postgresql cutover runbook across the layers where things actually break. It is fundamentally about database migration and Oracle to PostgreSQL, with zero-downtime migration setting the upper bound on what's possible. This matters because most production PostgreSQL incidents trace back to one of these three.
On the inside, postgresql cutover runbook involves a small set of PostgreSQL subsystems: the buffer manager, the write-ahead log, the planner and statistics collector, autovacuum, and the replication and HA layers. This guide walks through each in the order you should investigate them when a real production problem hits, with the SQL we actually run during schema conversion engagements.
Why postgresql cutover runbook matters in production
Why does postgresql cutover runbook matter? Because the cost of getting it wrong shows up on three timelines at once: an immediate p99 spike, a quarterly cost overrun, and an annual SLA miss. Teams that handle this well treat it as a continuous practice, not a one-time fix.
In production PostgreSQL deployments, the scenarios where postgresql cutover runbook bites are surprisingly consistent. A sudden traffic shape change. A seemingly innocuous schema change that triggers replanning. A storage tier change on the cloud provider's side that nobody told the database team about. The diagnostics in this guide work for all three.
A useful mental model: every PostgreSQL change has a cost, a blast radius, and a reversibility. The cheapest, smallest, most reversible change that actually moves your metric is almost always the right first step. It may not be the change you eventually want in steady state, but it buys you the time and confidence to make the bigger one safely.
How postgresql cutover runbook works in PostgreSQL
PostgreSQL behavior around postgresql cutover runbook is governed by five subsystems. Each can quietly affect throughput in ways that aren't visible from query logs alone.
- Buffer manager. The shared_buffers pool decides what stays hot in PostgreSQL memory versus the OS page cache.
- Write-ahead log. Every change is written to WAL before it touches the heap. Replication, PITR, and crash recovery all depend on it.
- Planner and statistics. The cost-based optimizer interacts with statistics gathered by ANALYZE to choose query plans.
- Autovacuum. Background workers reclaim dead tuples produced by MVCC. Mistuned autovacuum is the single most common cause of AWS DMS regressions.
- Process model. PostgreSQL forks a backend per connection. work_mem is allocated per-backend, which is exactly the surprise that takes down clusters during connection storms.
Knowing which layer your symptom belongs to determines the fix. A p99 spike caused by checkpoint I/O is configuration. A regression caused by stale planner statistics is operational. A correlation between table growth and write latency is almost always autovacuum starvation. The diagnostic queries below help you place the symptom on this map before you change anything.
How to diagnose postgresql cutover runbook issues
Start with measurement. The temptation is to jump straight to ALTER SYSTEM and start turning knobs, but every senior PostgreSQL DBA learns the same lesson the hard way: the first change you make is almost always the wrong one if you haven't measured first.
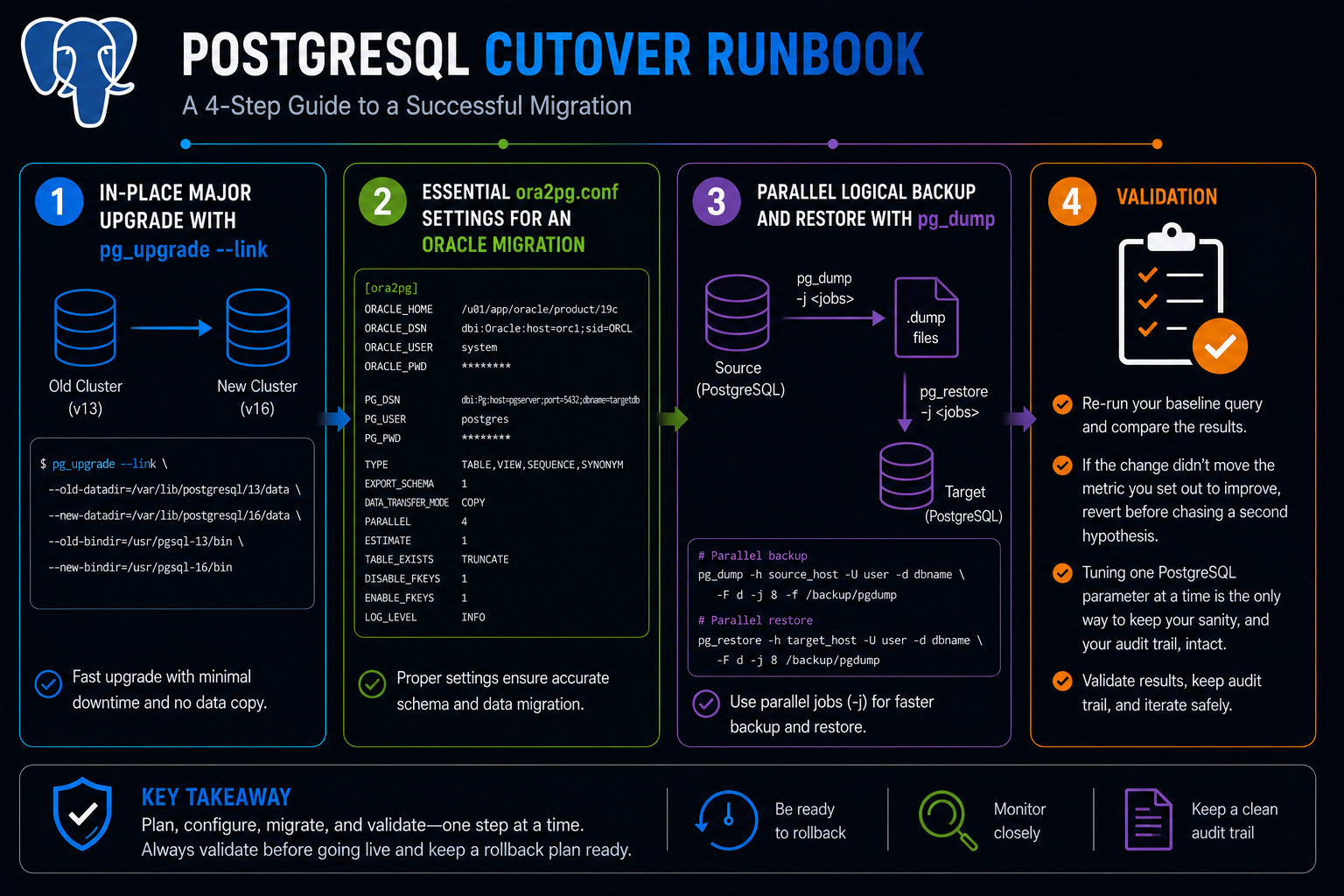
Step 1. In-place major upgrade with pg_upgrade --link.
pg_upgrade \ --old-bindir=/usr/pgsql-15/bin \ --new-bindir=/usr/pgsql-17/bin \ --old-datadir=/var/lib/pgsql/15/data \ --new-datadir=/var/lib/pgsql/17/data \ --link --jobs 8./analyze_new_cluster.sh
Read the output with two questions in mind. Does the shape match what you expected? And what's the worst-case row? The shape tells you whether your mental model of the cluster matches reality. The worst-case row tells you where the next surprise will come from in your ora2pg conversion workflow.
How to fix postgresql cutover runbook step by step
A real fix is more than the SQL statement. It's the change, the rollout, and the proof. The structure below separates them deliberately so you don't accidentally collapse them into a single Slack message that loses the rollback path.
On managed PostgreSQL services like AWS RDS, Aurora, Cloud SQL, and Azure Flexible Server, schema changes still happen via plain SQL. Configuration changes happen through parameter group rebuilds. Some parameters take effect immediately, others require a reboot. Verify with SELECT name, context FROM pg_settings WHERE name = '<param>'; before scheduling the change window.
Step 2. Essential ora2pg.conf settings for an Oracle migration.
ORACLE_DSN dbi:Oracle:host=oracle.local;sid=PRD;port=1521 ORACLE_USER system ORACLE_PWD <Vault> SCHEMA APP TYPE TABLE,COPY,INDEXES,VIEW,GRANT,SEQUENCE,FUNCTION,PROCEDURE,PACKAGE,TRIGGER DATA_LIMIT 10000 PARALLEL_TABLES 8 FILE_PER_INDEX 1 USE_TABLESPACE 0 PG_VERSION 17
Step 3. Parallel logical backup and restore with pg_dump.
pg_dump -h primary -U postgres -d appdb \ -j 8 -Fd -f /backup/appdb_dir pg_restore -h target -U postgres -d appdb_new -j 8 /backup/appdb_dir
Step 4. Validation. Re-run your baseline query and compare the results. If the change didn't move the metric you set out to improve, revert before chasing a second hypothesis. Tuning one PostgreSQL parameter at a time is the only way to keep your sanity, and your audit trail, intact.
Production guardrails and monitoring
Guardrails are how a fix becomes durable. Without them, PostgreSQL changes drift over time as configurations diverge across environments and someone reverts a setting during a hurried incident response.
- Add a Datadog or Prometheus alert on the metric you just improved at a threshold 20 percent above your new baseline.
- Capture an EXPLAIN (ANALYZE, BUFFERS) for any regressed query into your runbook so the on-call engineer has the next-step diagnostic ready.
- Document the rollback path: the exact SQL or ALTER SYSTEM sequence to restore the prior state if the change misbehaves.
- Set a calendar reminder to re-validate after the next major PostgreSQL version upgrade. Planner behaviors and default GUC values do change.
- Record the pg_stat_statements query ID and a representative plan in your team wiki so you can compare against future regressions in data migration.
- Schedule a follow-up review 30 days after the change to confirm the improvement persisted under realistic production traffic.
Common mistakes and anti-patterns
If you only read one section of this post, make it this one. These are the missteps we watch teams repeat across hundreds of PostgreSQL engagements. Avoid them and you've already done better than half the industry.
- Tuning postgresql cutover runbook by copy-pasting from a 2014 blog post without re-validating against PostgreSQL 14, 15, 16, or 17 behavior.
- Changing more than one PostgreSQL parameter at a time without measurement.
- Forgetting to ANALYZE after a large data load, then wondering why the planner picked a sequential scan over your shiny new index.
- Trusting an unverified backup or untested failover for upgrade path.
- Treating autovacuum as something to disable rather than something to tune.
- Allowing developers to write production queries with no EXPLAIN review.
PostgreSQL on AWS, Aurora, GCP, Azure
Managed PostgreSQL changes the operational surface area, not the underlying engine. Schema changes still happen via plain SQL. Configuration changes happen through parameter groups. The biggest exception is Aurora, where decoupled storage means a few of the standard tuning rules need to be reframed.
Specifics worth memorizing. AWS RDS PostgreSQL on gp3 storage gives you provisioned IOPS, but the maximum is per-volume, not per-instance. That fact surprises customers scaling vCPU and expecting linear I/O. Google AlloyDB's columnar engine is opt-in per table; turning it on is a one-line SQL call, but the analytical workload eligibility rules aren't always obvious until you read the EXPLAIN plan. Azure Database for PostgreSQL Flexible Server exposes a broader set of extensions than RDS or Aurora, including pg_partman, pgvector, TimescaleDB, and Citus on the Citus-flavored variant.
When this approach is the wrong starting point
This technique assumes a roughly normal OLTP PostgreSQL workload with healthy autovacuum. It's the wrong starting point if your workload is dominated by long analytical queries against a Citus or TimescaleDB hypertable, if you run on Aurora's storage-decoupled architecture (where buffer-pool semantics differ), or if the symptom is actually a network or kernel-level issue masquerading as a PostgreSQL problem.
Another pattern we see often. A retail bank thought their MongoDB-to-PostgreSQL migration would slow them down. We mapped 80 percent of their collections into JSONB with GIN indexes, ported the rest to relational, and the new PostgreSQL deployment served queries four times faster with 70 percent less storage.
Frequently asked questions
How long does an Oracle to PostgreSQL migration take?
Schema and code conversion typically take 4 to 12 weeks for a mid-size enterprise schema. Application testing and cutover planning often take longer than the database work itself. End-to-end migrations of a year or more are not unusual.
Should Production teams use pg_upgrade or logical replication for major version upgrades?
pg_upgrade --link is right for short-window upgrades, with minutes of downtime. Logical replication enables true zero-downtime upgrades on critical workloads, at the cost of more orchestration and verification effort.
Is ora2pg good enough for stored procedure conversion?
ora2pg generates a strong first draft for tables, indexes, views, and most PL/SQL. Complex procedural code, packages with state, and Oracle-specific features still require manual review by an experienced PostgreSQL engineer.
What is the biggest mistake in a database migration project?
Skipping data validation. A migration that runs flawlessly but ships row-level differences is worse than one that fails noisily. Always verify with row counts, checksums, and sample diffs before cutting over.
How do I cut over to PostgreSQL with zero downtime?
Stand up logical replication from source to PostgreSQL, run dual writes for verification, switch reads first, then writes, and keep the source available as a rollback target for at least one business day after cutover.
Where should I start if I’m new to cutover runbook for zero-downtime PostgreSQL migration?
Read this guide end to end, then run the diagnostic SQL queries against a non-production PostgreSQL database to build intuition. Most engineers we coach are productive within a day. Bookmark this page, then move on to the cluster posts linked below for deeper dives.
Further Reading
Data validation post-migration to PostgreSQL
Best Practices for Efficient Large-Scale PostgreSQL Database Migrations


