Mastering Google Cloud Dataflow and Apache Airflow Integration: A Comprehensive Guide for Data Engineers
Integrating Google Cloud Dataflow with Apache Airflow presents unique challenges that can overwhelm newcomers to data pipeline orchestration. While both tools are powerful individually, combining them effectively requires understanding specific technical hurdles and their solutions. This guide explores the most common integration challenges and provides practical solutions to help data engineers build robust, scalable data pipelines.
Understanding the Integration Landscape
Google Cloud Dataflow serves as a fully managed service for stream and batch data processing, while Apache Airflow excels at workflow orchestration and scheduling. When integrated properly, these tools create a powerful ecosystem for managing complex data pipelines. However, the integration process involves several technical considerations that beginners often struggle with.
Challenge 1: Parameter Management Between Systems
The Problem
One of the most frequent issues involves passing parameters from Airflow to Dataflow operators. When using BeamRunPythonPipelineOperator, the dataflow_config parameter may not properly resolve Jinja template variables, leading to literal template strings being passed instead of actual values.
The Solution
# Step 1: Use a Python operator to resolve parameters
def resolve_dataflow_config(**context):
config_value = context['dag_run'].conf.get('dataflow_config')
Variable.set('resolved_dataflow_config', config_value)
return config_value
resolve_config_task = PythonOperator(
task_id='resolve_config',
python_callable=resolve_dataflow_config,
dag=dag
)
# Step 2: Retrieve resolved value in BeamRunPythonPipelineOperator
dataflow_task = BeamRunPythonPipelineOperator(
task_id='dataflow_job',
dataflow_config=Variable.get('resolved_dataflow_config'),
dag=dag
)
Security Note: Avoid storing sensitive information in Airflow variables as they’re accessible to all users with appropriate permissions.
Challenge 2: Handling Custom Parameters in Apache Beam
The Problem
While standard pipeline options work seamlessly, custom parameters required within Beam code need special handling for proper parsing and utilization.
The Solution
import argparse
import json
# Set up argument parser
parser = argparse.ArgumentParser()
known_args, pipeline_args = parser.parse_known_args()
# Add standard pipeline arguments
parser.add_argument("--runner", help="Pipeline runner")
parser.add_argument("--project", help="GCP project ID")
parser.add_argument("--region", help="Execution region")
parser.add_argument("--num_workers", type=int, help="Worker count")
# Add custom parameters
parser.add_argument("--source_config", help="Source configuration")
parser.add_argument("--batch_config", help="Batch processing config")
# Parse arguments
args = parser.parse_args()
# Handle dictionary objects
if args.source_config:
source_config = json.loads(args.source_config.replace("'", '"'))
if args.batch_config:
batch_config = json.loads(args.batch_config.replace("'", '"'))
Challenge 3: Dependency Management Strategy
The Problem
Managing Python dependencies in Dataflow requires careful consideration of file placement and configuration within the Airflow environment.
The Solution
import os
from airflow import configuration
# Place setup.py in Airflow's dags folder
LOCAL_SETUP_FILE = os.path.join(
configuration.get('core', 'dags_folder'),
'setup.py'
)
# Configure the operator with setup file
dataflow_task = BeamRunPythonPipelineOperator(
py_file=main_pipeline_file,
runner=BeamRunnerType.DataflowRunner,
task_id='dataflow_execution',
dag=dag,
default_pipeline_options={
"num_workers": "2",
"max_num_workers": "10",
"setup_file": LOCAL_SETUP_FILE
}
)
Setup.py Configuration
import setuptools
REQUIRED_PACKAGES = [
'apache-beam[gcp]==2.40.0',
'google-cloud-storage==2.5.0',
'google-cloud-bigquery==3.3.0'
]
setuptools.setup(
name='dataflow-dependencies',
version='1.0.0',
description='Dataflow pipeline dependencies',
install_requires=REQUIRED_PACKAGES,
packages=setuptools.find_packages()
)
Challenge 4: Integrating Additional GCP Services
The Problem
Utilizing other Google Cloud services like BigQuery, Cloud Storage, or Firestore within Dataflow pipelines requires explicit dependency management and proper import handling.
The Solution
Dependency Declaration
# In setup.py
REQUIRED_PACKAGES = [
'apache-beam[gcp]==2.40.0',
'google-cloud-bigquery==3.3.0',
'google-cloud-storage==2.5.0',
'google-cloud-firestore==2.7.0',
'google-cloud-logging==3.2.0'
]
Proper Import Strategy
# Incorrect: Global imports
# from google.cloud import bigquery # Don't do this
# Correct: Import within DoFn
class ProcessDataFn(beam.DoFn):
def process(self, element):
# Import within the function
from google.cloud import bigquery
from google.cloud import storage
client = bigquery.Client()
# Process data using GCP services
yield processed_element
Critical Note: Import statements must be placed within DoFn functions, not at the global level, since dependencies are installed on worker nodes, not the master node.
Challenge 5: Managing Custom Code Dependencies
The Problem
Incorporating shared or common code modules into Dataflow pipelines requires strategic placement and configuration to ensure proper loading.
The Solution
Directory Structure
airflow_dags/
├── setup.py
├── shared/
│ ├── __init__.py
│ ├── utils.py
│ └── transformations.py
└── pipelines/
└── main_pipeline.py
Setup Configuration
# In setup.py
import setuptools
setuptools.setup(
name='shared-modules',
version='0.1.0',
description='Shared pipeline modules',
install_requires=REQUIRED_PACKAGES,
packages=setuptools.find_packages(),
package_data={
'shared': ['*.py'],
}
)
Usage in Pipeline
class CustomTransformFn(beam.DoFn):
def process(self, element):
# Import shared modules within DoFn
from shared import utils
from shared.transformations import custom_transform
result = custom_transform(element)
yield result
Best Practices for Successful Integration
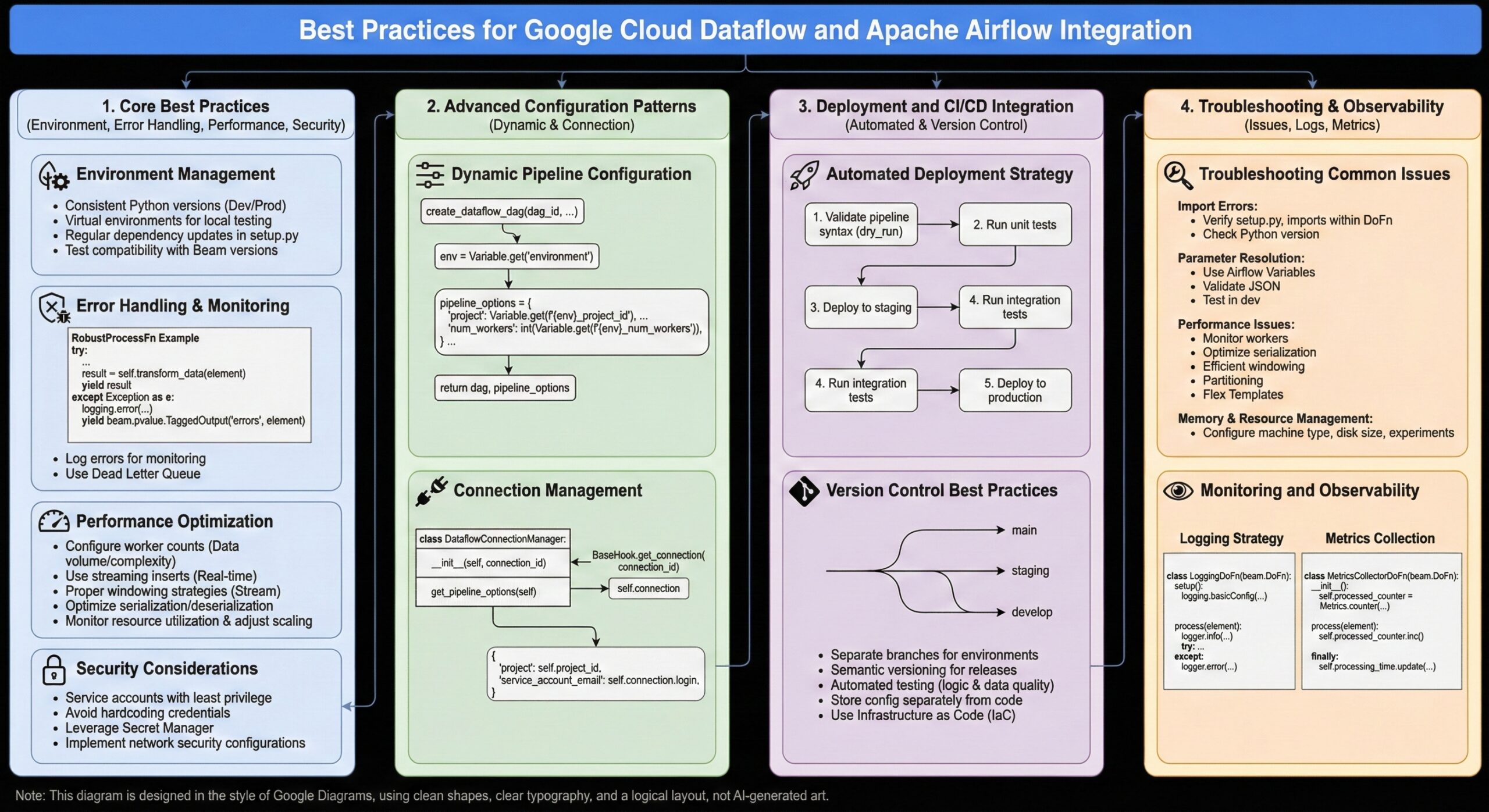
1. Environment Management
- Maintain consistent Python versions across development and production environments
- Use virtual environments for local development and testing
- Regularly update dependency versions in setup.py
- Test pipeline compatibility with different Apache Beam versions
2. Error Handling and Monitoring
class RobustProcessFn(beam.DoFn):
def process(self, element):
try:
# Processing logic
result = self.transform_data(element)
yield result
except Exception as e:
# Log errors for monitoring
import logging
logging.error(f"Processing failed for element: {element}, Error: {str(e)}")
# Optionally yield to dead letter queue
yield beam.pvalue.TaggedOutput('errors', element)
def transform_data(self, element):
# Your transformation logic here
return processed_element
3. Performance Optimization
- Configure appropriate worker counts based on data volume and processing complexity
- Use streaming inserts for real-time processing requirements
- Implement proper windowing strategies for stream processing
- Optimize data serialization and deserialization processes
- Monitor resource utilization and adjust scaling parameters accordingly
4. Security Considerations
- Use service accounts with minimal required permissions following the principle of least privilege
- Avoid hardcoding credentials in pipeline code
- Leverage Google Cloud Secret Manager for sensitive data management
- Implement proper network security configurations for data access
Advanced Configuration Patterns
Dynamic Pipeline Configuration
def create_dataflow_dag(dag_id, schedule_interval, default_args):
dag = DAG(
dag_id=dag_id,
default_args=default_args,
schedule_interval=schedule_interval,
catchup=False
)
# Dynamic configuration based on environment
env = Variable.get('environment', default_var='dev')
pipeline_options = {
'project': Variable.get(f'{env}_project_id'),
'region': Variable.get(f'{env}_region'),
'temp_location': Variable.get(f'{env}_temp_bucket'),
'staging_location': Variable.get(f'{env}_staging_bucket'),
'num_workers': int(Variable.get(f'{env}_num_workers', default_var='2')),
'max_num_workers': int(Variable.get(f'{env}_max_workers', default_var='10'))
}
return dag, pipeline_options
Connection Management
class DataflowConnectionManager:
def __init__(self, connection_id):
self.connection = BaseHook.get_connection(connection_id)
self.project_id = self.connection.extra_dejson.get('project_id')
self.key_path = self.connection.extra_dejson.get('key_path')
def get_pipeline_options(self):
return {
'project': self.project_id,
'runner': 'DataflowRunner',
'service_account_email': self.connection.login,
'use_public_ips': False
}
Deployment and CI/CD Integration
Automated Deployment Strategy
# CI/CD pipeline configuration
def validate_and_deploy_pipeline():
# Step 1: Validate pipeline syntax
validate_beam_pipeline()
# Step 2: Run unit tests
run_pipeline_tests()
# Step 3: Deploy to staging environment
deploy_to_staging()
# Step 4: Run integration tests
run_integration_tests()
# Step 5: Deploy to production
deploy_to_production()
def validate_beam_pipeline():
"""Validate Apache Beam pipeline syntax and dependencies"""
import subprocess
result = subprocess.run(['python', '-m', 'apache_beam.runners.direct.direct_runner',
'--dry_run', 'pipeline.py'], capture_output=True)
if result.returncode != 0:
raise ValueError(f"Pipeline validation failed: {result.stderr}")
Version Control Best Practices
- Maintain separate branches for development, staging, and production environments
- Use semantic versioning for pipeline releases
- Implement automated testing for pipeline logic and data quality
- Store configuration files separately from code repositories
- Use infrastructure as code for environment provisioning
Troubleshooting Common Issues
Import Errors
- Verify all dependencies are listed in setup.py with correct versions
- Ensure imports are within DoFn functions rather than at module level
- Check Python version compatibility across all environments
- Validate that custom modules are properly packaged and accessible
Parameter Resolution Problems
- Use Airflow’s Variable system for complex parameter passing
- Validate JSON formatting for dictionary parameters
- Test parameter resolution in development environment before production deployment
- Implement parameter validation functions to catch issues early
Performance Issues
- Monitor worker utilization and adjust scaling parameters based on actual usage
- Optimize data serialization and deserialization processes
- Implement efficient windowing strategies for streaming data
- Use appropriate data partitioning strategies for large datasets
- Consider using Dataflow Flex Templates for better resource management
Memory and Resource Management
# Configure memory-efficient processing
pipeline_options = {
'worker_machine_type': 'n1-standard-4',
'disk_size_gb': 100,
'use_public_ips': False,
'worker_disk_type': 'pd-ssd',
'experiments': ['use_runner_v2']
}
Monitoring and Observability
Logging Strategy
import logging
from apache_beam.options.pipeline_options import SetupOptions
class LoggingDoFn(beam.DoFn):
def setup(self):
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
def process(self, element):
self.logger.info(f"Processing element: {element}")
try:
result = self.transform_element(element)
self.logger.info(f"Successfully processed: {result}")
yield result
except Exception as e:
self.logger.error(f"Error processing {element}: {str(e)}")
raise
Metrics Collection
from apache_beam.metrics import Metrics
class MetricsCollectorDoFn(beam.DoFn):
def __init__(self):
self.processed_counter = Metrics.counter('pipeline', 'processed_records')
self.error_counter = Metrics.counter('pipeline', 'error_records')
self.processing_time = Metrics.distribution('pipeline', 'processing_time_ms')
def process(self, element):
start_time = time.time()
try:
result = self.process_element(element)
self.processed_counter.inc()
yield result
except Exception as e:
self.error_counter.inc()
raise
finally:
processing_time_ms = (time.time() - start_time) * 1000
self.processing_time.update(processing_time_ms)
Conclusion
Successfully integrating Google Cloud Dataflow with Apache Airflow requires understanding the nuances of parameter passing, dependency management, and proper code organization. By addressing these core challenges systematically, data engineers can build robust, scalable data pipelines that leverage the strengths of both platforms.
The key to success lies in proper planning, following best practices for dependency management, and maintaining clean separation between orchestration logic and data processing code. With these foundations in place, teams can confidently deploy production-ready data pipelines that scale with their organization’s needs.
Remember that integration challenges often stem from the distributed nature of cloud computing and the need for proper dependency isolation. By following the solutions outlined in this guide, implementing comprehensive monitoring and error handling, and maintaining good development practices, you’ll be well-equipped to overcome common hurdles and build efficient data processing workflows that meet enterprise requirements.
Further Reading:
- Mastering PostgreSQL Replication: A Complete Guide for Database Professionals
- Comprehensive Guide to MySQL to Amazon Redshift Data Replication Using Tungsten Replicator
- Useful CQLSH Commands for Everyday Use
- Transparent Data Encryption (TDE): The Ultimate Guide
- Troubleshooting Fragmented MongoDB Platforms: Expert Guide by MinervaDB Inc.
- Google Dataflow Operators