Full-Stack MariaDB Optimization by MinervaDB: Achieving Peak Performance, Scalability, and High Availability
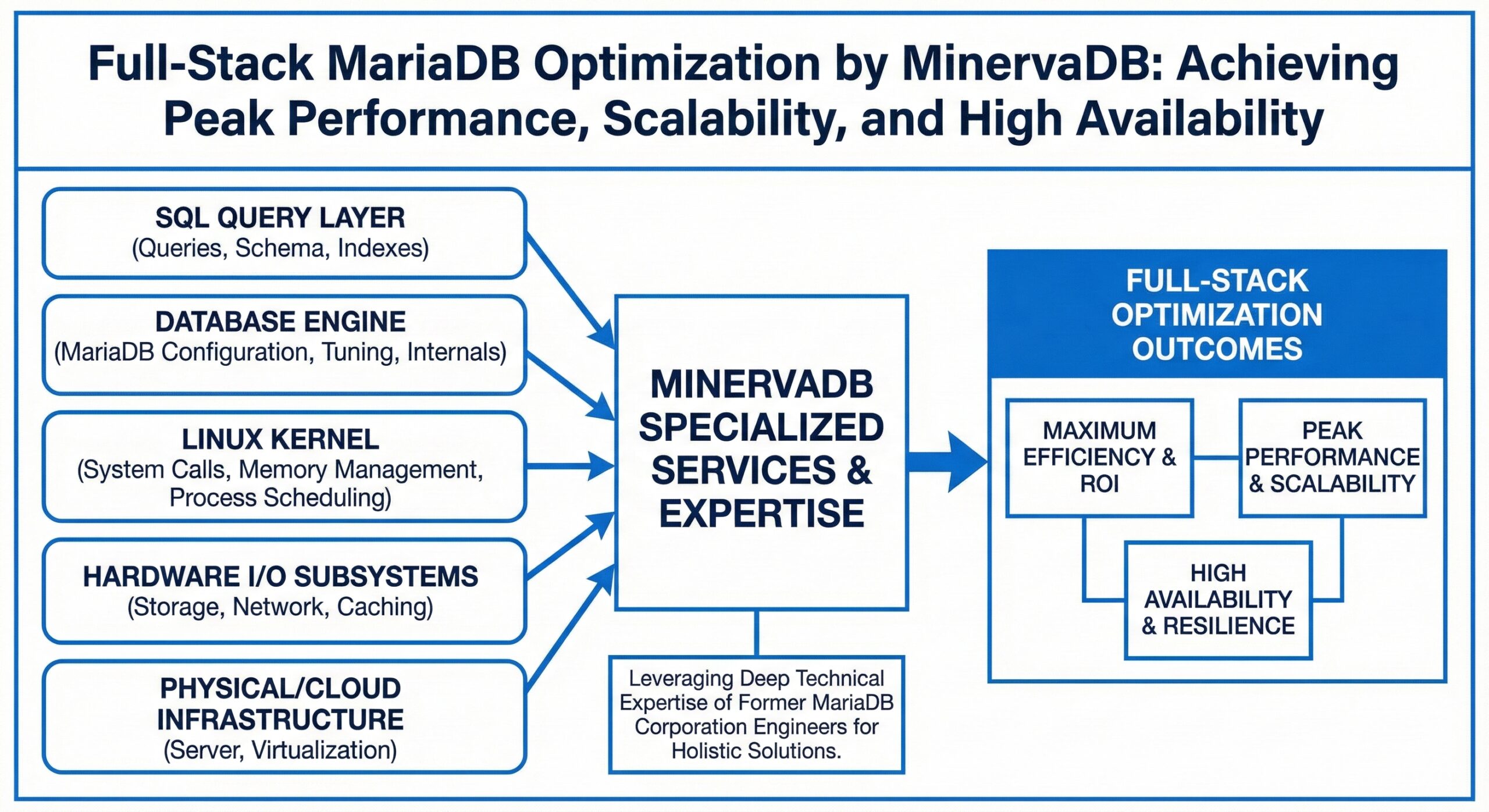
MinervaDB has established itself as a premier provider of specialized MariaDB optimization services, delivering holistic, full-stack solutions designed to meet the rigorous demands of modern enterprise database environments.
Distinguishing themselves from generalist support providers, MinervaDB leverages the deep technical expertise of former MariaDB Corporation engineers. This pedigree allows them to offer a level of insight that goes beyond surface-level configuration. Their “full-stack” philosophy implies that optimization is not limited to the database engine alone; rather, it encompasses the entire ecosystem—from the Linux kernel and hardware I/O subsystems up to the SQL query layer—enabling organizations to extract maximum efficiency from their infrastructure investments.
1. Performance Optimization: A Granular Approach
MinervaDB’s approach to performance engineering is methodical and data-driven. It moves beyond basic parameter changes to address the root causes of latency and throughput bottlenecks.
-
Advanced Configuration Tuning: Rather than relying on default settings, MinervaDB customizes the my.cnf configuration and OS kernel parameters (such as disk schedulers and memory swappiness) to align perfectly with the specific workload—whether it is write-heavy OLTP or read-heavy OLAP.
-
Query and Indexing Strategy: A core component of their service involves deep-dive query analysis. By identifying slow-running queries and analyzing execution plans, they implement adaptive indexing strategies that drastically reduce CPU and I/O overhead.
-
Wait-Event Analysis: By analyzing database patterns and system resources, they focus on “wait events”—identifying exactly where the database is spending time waiting for resources. This allows for targeted optimizations that significantly enhance speed and efficiency in high-demand environments.
Key Takeaway: Their methodology ensures that the database layer, the operating system, and the application logic function as a cohesive, high-performance unit.
2. MariaDB Optimization for Scalability Engineering: Built for Growth
2. Scalability Engineering: Built for Growth
As applications grow, the limitations of a single-node architecture become apparent. MinervaDB addresses this through sophisticated scalability engineering designed to handle massive concurrency without degradation.
-
Horizontal Scaling with Galera: MinervaDB specializes in implementing horizontal scaling solutions using MariaDB Galera Cluster. This synchronous multi-master cluster technology allows databases to distribute the transaction load across multiple nodes, increasing read/write throughput linearly.
-
Sharding and Capacity Planning: For hyperscale environments, they employ sharding strategies (partitioning data across different servers) and rigorous capacity planning. This proactive approach ensures that infrastructure design can accommodate future growth requirements, preventing performance cliffs before they occur.
-
Seamless Expansion: This architecture supports seamless growth for high-traffic, data-intensive applications, ensuring that as user bases expand, performance and reliability remain consistent.
3. High Availability (HA) Architecture: Ensuring Business Continuity
In an era where downtime translates directly to revenue loss, MinervaDB constructs architectures designed for “Five Nines” (99.999%) availability.
-
Resilient Clustering: They ensure continuous service delivery by deploying MariaDB Galera Cluster, which offers protection against node failures. If one node goes down, the cluster continues to operate without data loss.
-
Intelligent Routing with MaxScale: To manage traffic flow, MinervaDB utilizes MaxScale as an intelligent database proxy, load balancer, and router. MaxScale detects node health and automatically redirects traffic to healthy nodes, ensuring users never experience a service interruption.
-
Disaster Recovery Standards: Their 2025 best practices guide emphasizes comprehensive HA strategies that address modern infrastructure demands. This includes automatic failover mechanisms and split-brain prevention, ensuring databases remain accessible even during hardware failures, network partitions, or scheduled maintenance events.
Diagnosing the Slowdown: 5 Common Configuration Traps in MariaDB
Poorly configured MariaDB doesn’t just “run slow”; it can cause catastrophic cascading failures where hardware resources (CPU, Disk I/O, RAM) effectively attack each other.
Here is how specific misconfigurations create serious performance bottlenecks, categorized by the resource they exhaust.
1. The “Thundering Herd” (CPU & Connection Exhaustion)
The Bottleneck: By default, MariaDB uses a one-thread-per-connection model. If you have a sudden spike in traffic (e.g., 5000 concurrent users), the server attempts to spawn 5000 threads. The CPU then spends more time “context switching” (juggling these threads) than actually executing queries.
The Configuration Mistake:
-
Leaving thread_handling at default: This allows unlimited thread creation up to max_connections.
-
Misconfigured max_connections: Setting this too high (e.g., 10000) without a thread pool invites the OS to crash under the weight of thread management overhead.
The Fix: Enable the Thread Pool. Instead of 5000 threads for 5000 connections, the Thread Pool keeps a fixed number of active worker threads (usually equal to CPU cores) and queues the rest. This creates a smooth, predictable flow of execution.
2. The I/O “Checkpoint” Storm (Disk I/O Saturation)
The Bottleneck: InnoDB writes changes to a memory buffer (Log Buffer) and then flushes them to the Redo Log on disk. If the Redo Log is too small, it fills up instantly. MariaDB enters “furious flushing” mode, where it pauses all incoming write transactions to aggressively clear space in the log file. This causes the database to effectively freeze for seconds or minutes.
The Configuration Mistake:
-
Tiny innodb_log_file_size: Default values (often 48MB or 512MB) are frequently too small for write-heavy workloads.
-
Default innodb_io_capacity: If this is set low (e.g., 200) but you are using fast SSDs/NVMe, the database artificially throttles itself, refusing to use the disk’s full speed to clear backlogs.
The Fix: Increase innodb_log_file_size (e.g., to 2GB or 4GB) to give the database enough “runway” to write data smoothly without panic-flushing.
3. The RAM Trap (Memory Swapping)
The Bottleneck: The innodb_buffer_pool_size is the most critical setting. It caches data and indexes in RAM.
-
Scenario A (Too Small): If set to default (often 128MB), the database must read from the slow disk for almost every query. Latency skyrockets.
-
Scenario B (Too Big): If set to 90% or 100% of RAM, there is no room left for the OS or connection threads. The OS begins swapping database memory to disk. Swapping memory is 100,000x slower than RAM, causing the server to become unresponsive.
The Fix: Set innodb_buffer_pool_size to 70-80% of total available RAM on a dedicated database server, leaving enough breathing room for the OS.
4. The “Mutex” Gridlock (Query Cache Contention)
The Bottleneck: The Query Cache seems helpful: it stores the result of SELECT statements. However, to ensure data consistency, the Query Cache requires a “global lock” (mutex). On a multi-core server with high concurrency, threads fight over this single lock.
-
The Result: Adding more CPU cores actually makes performance worse because more threads are fighting for the same lock.
The Configuration Mistake:
-
Enabling Query Cache (query_cache_type = 1): In modern high-concurrency environments, this feature is often a liability.
The Fix: Disable it entirely (query_cache_type = 0 and query_cache_size = 0). Rely on the InnoDB Buffer Pool or external caches like Redis for speed.
5. Replication Lag (Data Inconsistency)
The Bottleneck: When a Primary node writes data, the Replica must follow. If the Replica is configured for “perfect safety” (sync_binlog=1, innodb_flush_log_at_trx_commit=1) but lacks the hardware IOPS to keep up, it falls behind.
-
The Consequence: Users reading from the Replica see stale data (e.g., a “User not found” error immediately after registration).
The Fix: On Replicas (where data loss during a crash might be recoverable by re-cloning from Master), you can relax durability settings:
-
Set innodb_flush_log_at_trx_commit = 2 (flushes to OS cache, not disk, every commit).
-
Set sync_binlog = 0 (let the OS handle binlog syncing).
Summary of Critical Adjustments
| Parameter | "Bad" Configuration | "Bottleneck" Consequence | Optimized Goal |
|---|---|---|---|
| innodb_buffer_pool_size | Default (128MB) or >90% RAM | Disk Thrashing or OS Swapping | 70-80% of RAM |
| innodb_log_file_size | Default (48MB) | Write Stalls (Checkpointing) | 1GB - 4GB |
| query_cache_type | ON (1) | CPU Lock Contention | OFF (0) |
| thread_handling | one-thread-per-connection | Context Switching Overload | pool-of-threads |
The MinervaDB Advantage: Engineering-First Optimization for Mission-Critical MariaDB
Engaging MinervaDB Inc. means moving beyond “standard support”—which often amounts to reactive troubleshooting—and adopting a proactive, engineering-first partnership.
While generalist DBAs can adjust basic parameters, MinervaDB leverages the expertise of former MariaDB Corporation engineers to optimize the entire technology stack. They don’t just treat symptoms; they re-architect the environment for speed, resilience, and growth.
Here is the strategic case for engaging MinervaDB for full-stack optimization:
1. Source-Code Level Expertise (The “Why,” Not Just the “How”)
Many consultancies rely on “best practices” checklists. MinervaDB engineers understand the internal C++ source code of MariaDB.
-
The Advantage: They know exactly how the optimizer makes decisions, how the thread pool manages context switching, and how InnoDB handles locking internally.
-
The Result: They can solve “impossible” performance mysteries that generic support teams cannot diagnose, such as deep mutex contention or specific edge-case bugs.
2. True “Full-Stack” Visibility
Performance is rarely just a database setting; it is a chain of dependencies. MinervaDB optimizes the vertical slice:
-
OS/Kernel Layer: Tuning disk schedulers, TCP stack, and memory management (NUMA, Swappiness) to prevent the OS from fighting the database.
-
Instance Layer: configuring my.cnf variables (Buffer Pools, Redo Logs) to match specific workload patterns (Write-Heavy vs. Read-Heavy).
-
Query/Schema Layer: Rewriting inefficient SQL and restructuring indexes to reduce CPU/IO overhead.
-
The Result: You stop buying expensive hardware to mask software inefficiencies.
3. Mastery of High-Availability & Clustering
Setting up MariaDB Galera Cluster is easy; keeping it stable under high load is difficult.
-
The Advantage: MinervaDB specializes in the complex interplay between Galera Cluster and MaxScale(proxy/router). They architect solutions that handle “split-brain” scenarios, prevent node eviction during traffic spikes, and ensure zero-downtime maintenance.
-
The Result: True “Five Nines” (99.999%) availability where failovers are automatic and invisible to the end-user.
4. Solving the “Thundering Herd” Problem
As detailed in previous discussions, high-concurrency environments often crash due to thread exhaustion.
-
The Advantage: MinervaDB focuses heavily on Scalability Engineering. They implement Thread Pool configurations and connection multiplexing that allow MariaDB to handle 10,000+ concurrent connections without the CPU thrashing that kills standard installations.
-
The Result: Your application survives “Black Friday” traffic spikes without crashing.
5. Vendor Independence & Cost Efficiency
MinervaDB focuses on performance throughput per dollar.
-
The Advantage: By optimizing the software efficiently, they often reduce the need for massive hardware upgrades or expensive enterprise licenses that you may not need.
-
The Result: Significant reduction in Total Cost of Ownership (TCO). You get more transactions per second (TPS) out of your existing infrastructure.
| Feature | Generic DBA Support | MinervaDB Full-Stack Engineering |
|---|---|---|
| Approach | Reactive (Fix it when it breaks) | Proactive (Architect it so it doesn't break) |
| Scope | Database Config (my.cnf) | OS Kernel + DB Config + SQL + Architecture |
| Scalability | "Add more RAM/CPU" | "Optimize Thread Pools & Query Execution" |
| Expertise | General Admin | Former MariaDB Source Code Engineers |
| Goal | Uptime | Peak Performance & Throughput |