Understanding and Mitigating Tombstone Storms in Apache Cassandra
Apache Cassandra is a highly scalable, distributed NoSQL database designed for high availability and performance across commodity hardware. However, one of the most insidious performance issues that can plague Cassandra clusters is the “tombstone storm”—a condition where excessive tombstones (markers for deleted data) lead to severe read amplification, unstable latencies, and even query failures.
This article explores the root causes of tombstone storms, their operational impact, and the coordinated strategies required to prevent and resolve them, focusing on the interplay between TTLs, gc_grace_seconds, compaction strategies, and data access patterns.
What Are Tombstones in Cassandra?
When data is deleted in Cassandra—either via an explicit DELETE statement or because it has expired due to a Time-To-Live (TTL) setting—the system does not immediately remove the data from disk. Instead, it writes a special marker called a tombstone.
Tombstones serve a critical role in Cassandra’s distributed architecture: they ensure that deleted data does not reappear due to eventual consistency, particularly during node repairs or when handling stale replicas. As per the Apache Cassandra documentation, “When a delete request is received by Cassandra it does not actually remove the data from the underlying store. Instead it writes a special piece of data known as a tombstone” [^1].
Tombstones remain active until two conditions are met:
- All replicas have received the tombstone.
- A time window defined by gc_grace_seconds has passed, after which tombstones can be permanently removed during compaction.
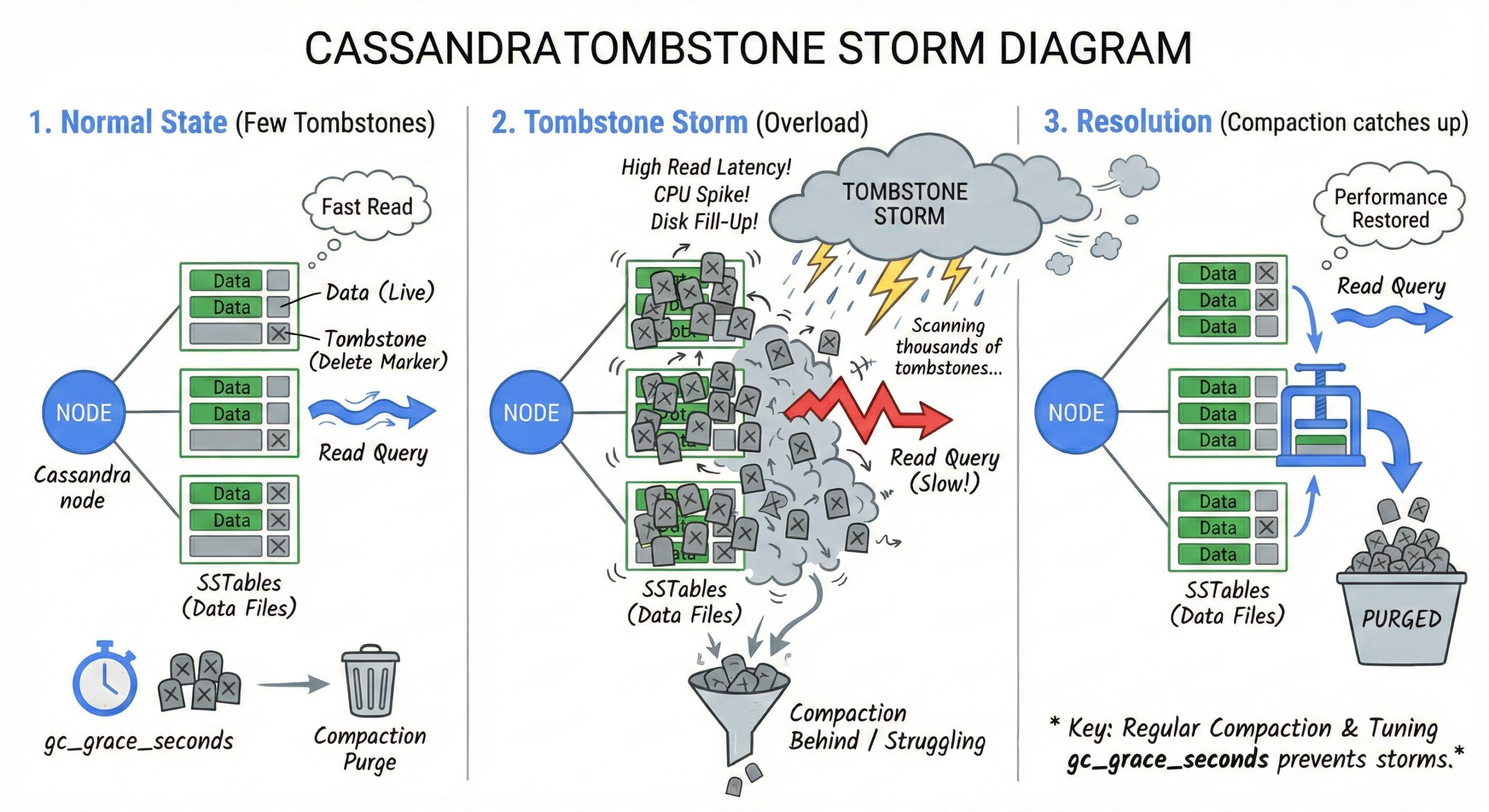
What Triggers a Tombstone Storm?
A tombstone storm occurs when a read query encounters a large number of tombstones (typically exceeding the default threshold of 100,000), causing the coordinator node to fail the query with an error such as TombstoneOverwhelmingException.
Common causes include:
- High-frequency deletes or TTL expirations: Applications that frequently delete or expire data (e.g., time-series data, session stores) generate massive numbers of tombstones.
- Wide rows or partition overuse: A single partition containing thousands of rows, all marked for deletion, results in tombstone accumulation within the same partition.
- Inadequate compaction strategy: If compaction does not run frequently or efficiently, tombstones linger and accumulate.
- Short gc_grace_seconds without proper repair cycles: If gc_grace_seconds is too short and repairs are delayed, nodes may miss tombstone propagation, risking data resurrection.
As noted in a troubleshooting guide, “Developers using Apache Cassandra sometimes encounter issues where read latencies spike unexpectedly, writes fail due to tombstone accumulation” [^2]. These issues often stem from schema and operational misconfigurations.
The Impact: Read Amplification and Unstable Latencies
Tombstone storms directly impact read performance:
- Read amplification: During a read, Cassandra must scan multiple SSTables and reconcile versions of data. Tombstones increase the amount of data scanned, even if no live data is returned.
- Unstable latencies: As the number of tombstones grows, read latencies become unpredictable and can spike dramatically.
- Coordinator overload: The coordinator node must process all tombstones across replicas, consuming CPU and memory, potentially leading to timeouts or failures.
One guide notes that “tombstone accumulation” leads to “slow read queries, increased memory pressure, and potential node failures” [^5]. In extreme cases, nodes may become unresponsive or fail under the load.
Fixing Tombstone Storms: A Coordinated Approach
Resolving tombstone storms is not a matter of adjusting a single parameter. It requires a holistic strategy involving configuration, schema design, and operational practices.
1. Tune gc_grace_seconds Appropriately
The gc_grace_seconds parameter defines how long tombstones are retained before being eligible for removal during compaction. It should be long enough to allow for repairs in case of node outages.
- Default: 86400 seconds (1 day).
- Best Practice: Set this based on your repair schedule. For example, if repairs run weekly, gc_grace_seconds should be at least 7 days.
- Caution: Reducing gc_grace_seconds too aggressively risks data resurrection if repairs are delayed [^6].
2. Optimize Compaction Strategy
Compaction is the process that merges SSTables and removes tombstones. The choice of compaction strategy directly affects tombstone cleanup:
- Size-Tiered Compaction (STCS): Good for write-heavy workloads but can delay tombstone removal in large SSTables.
- Leveled Compaction (LCS): Better for read-heavy workloads with frequent deletes, as it promotes faster tombstone removal.
- Time-Window Compaction (TWCS): Ideal for time-series data with TTLs, as it groups data by time windows and efficiently purges expired data.
Using TWCS can significantly reduce tombstone accumulation in TTL-driven use cases.
3. Align TTL with Data Access Patterns
- Avoid short TTLs on high-write tables unless absolutely necessary.
- Consider data retention policies and whether soft deletes (e.g., status flags) could replace hard deletes.
- For time-series data, partition by time windows (e.g., daily) so that entire partitions can be dropped instead of individually deleting rows.
4. Monitor and Prevent Excessive Tombstones
Use tools like nodetool tombstonestats and sstablemetadata to monitor tombstone counts. Set up alerts for:
- Tombstones per read exceeding thresholds.
- SSTables with high tombstone density.
Regularly run nodetool repair to ensure tombstones are propagated across replicas, especially if gc_grace_seconds is non-zero.
5. Schema Design Best Practices
- Avoid collections (lists, sets, maps) if they are frequently updated, as each update can generate hidden tombstones [^4].
- Prefer denormalization and wide rows only when necessary; consider using clustering keys to manage data lifecycle.
- Use counter columns or lightweight transactions judiciously, as they can also generate tombstone-like metadata.
Conclusion
Tombstone storms are a critical performance anti-pattern in Apache Cassandra, arising from the intersection of heavy deletes, TTL usage, and misaligned operational settings. They manifest as read amplification, latency spikes, and query failures—symptoms that degrade user experience and system stability.
The solution lies in a coordinated approach:
- Set gc_grace_seconds in line with repair schedules.
- Choose a compaction strategy that supports your workload (e.g., TWCS for time-series).
- Design schemas to minimize tombstone generation.
- Monitor tombstone accumulation proactively.
By aligning TTLs, gc_grace_seconds, compaction, and access patterns, teams can prevent tombstone storms and maintain predictable, high-performance Cassandra clusters at scale [^3].
References:
[^1]: Compaction | Apache Cassandra Documentation
[^2]: Fixing Read Latency Spikes, Tombstone Accumulation, and Node …
[^3]: Troubleshooting Cassandra: Fixing Tombstone Accumulation, Read Latency …
[^4]: Cassandra Collections: Hidden Tombstones | Instaclustr
[^5]: Troubleshooting Cassandra Read Performance: Resolving Tombstone …
[^6]: Tombstones | Apache Cassandra Documentation
[^7]: Managing Tombstones in Apache Cassandra
[^8]: Troubleshooting Read Inconsistencies and Tombstone Overload in Cassandra


