
Full-Stack Database Infrastructure Engineering: Complete Analytics and Operations Management Solutions
Expert Database Consulting Services for Modern Enterprise Infrastructure
Our services include MinervaDB Consultative Support to help businesses maximize their database potential.
MinervaDB Inc. delivers comprehensive full-stack database infrastructure engineeringsolutions, specializing in performance optimization, scalability architecture, and enterprise-grade operations management across diverse database ecosystems. Our consultative approach ensures optimal database performance, reliability, and security for mission-critical applications.
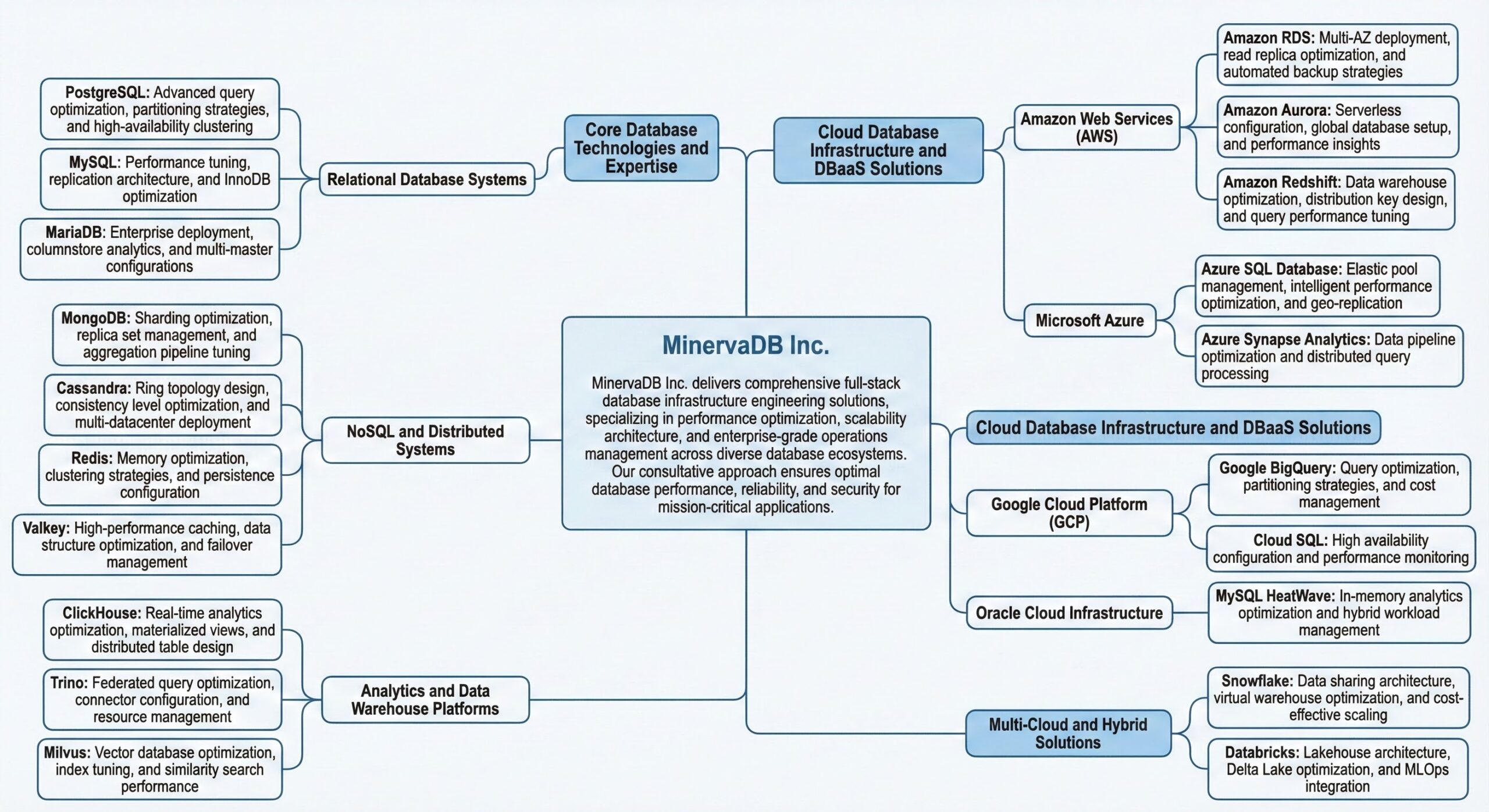
Core Database Technologies and Expertise
Relational Database Systems
- PostgreSQL: Advanced query optimization, partitioning strategies, and high-availability clustering
- MySQL: Performance tuning, replication architecture, and InnoDB optimization
- MariaDB: Enterprise deployment, columnstore analytics, and multi-master configurations
NoSQL and Distributed Systems
- MongoDB: Sharding optimization, replica set management, and aggregation pipeline tuning
- Cassandra: Ring topology design, consistency level optimization, and multi-datacenter deployment
- Redis: Memory optimization, clustering strategies, and persistence configuration
- Valkey: High-performance caching, data structure optimization, and failover management
Analytics and Data Warehouse Platforms
- ClickHouse: Real-time analytics optimization, materialized views, and distributed table design
- Trino: Federated query optimization, connector configuration, and resource management
- Milvus: Vector database optimization, index tuning, and similarity search performance
Cloud Database Infrastructure and DBaaS Solutions
Amazon Web Services (AWS)
- Amazon RDS: Multi-AZ deployment, read replica optimization, and automated backup strategies
- Amazon Aurora: Serverless configuration, global database setup, and performance insights
- Amazon Redshift: Data warehouse optimization, distribution key design, and query performance tuning
Microsoft Azure
- Azure SQL Database: Elastic pool management, intelligent performance optimization, and geo-replication
- Azure Synapse Analytics: Data pipeline optimization and distributed query processing
Google Cloud Platform (GCP)
- Google BigQuery: Query optimization, partitioning strategies, and cost management
- Cloud SQL: High availability configuration and performance monitoring
Oracle Cloud Infrastructure
- MySQL HeatWave: In-memory analytics optimization and hybrid workload management
Multi-Cloud and Hybrid Solutions
- Snowflake: Data sharing architecture, virtual warehouse optimization, and cost-effective scaling
- Databricks: Lakehouse architecture, Delta Lake optimization, and MLOps integration

☛ Technology focus – Vendor neutral and independent
| Category | Technology | Enterprise Ready | 24/7 Support |
|---|---|---|---|
| SQL Databases | PostgreSQL | ✓ | ✓ |
| MySQL | ✓ | ✓ | |
| MariaDB | ✓ | ✓ | |
| SQL Server | ✓ | ✓ | |
| SAP HANA | ✓ | ✓ | |
| NoSQL Document | MongoDB | ✓ | ✓ |
| CouchDB | ✓ | ✓ | |
| NoSQL Key-Value | Redis | ✓ | ✓ |
| Valkey | ✓ | ✓ | |
| NoSQL Wide-Column | Cassandra | ✓ | ✓ |
| HBase | ✓ | ✓ | |
| NoSQL Graph | Neo4j | ✓ | ✓ |
| Analytics | ClickHouse | ✓ | ✓ |
| Trino | ✓ | ✓ | |
| Vertica | ✓ | ✓ | |
| GreenPlum | ✓ | ✓ | |
| NewSQL | CockroachDB | ✓ | ✓ |
| TiDB | ✓ | ✓ | |
| Vector Databases | Milvus | ✓ | ✓ |
| Pinecone | ✓ | ✓ | |
| Cloud Platforms | AWS RDS | ✓ | ✓ |
| Azure SQL | ✓ | ✓ | |
| Google Cloud SQL | ✓ | ✓ | |
| Google AlloyDB | ✓ | ✓ | |
| Amazon Aurora | ✓ | ✓ | |
| Snowflake | ✓ | ✓ | |
| Databricks | ✓ | ✓ | |
| BigQuery | ✓ | ✓ | |
| Redshift | ✓ | ✓ | |
| MySQL HeatWave | ✓ | ✓ |
Performance Engineering and Optimization
Query Performance Optimization
-- Example: PostgreSQL query optimization with proper indexing CREATE INDEX CONCURRENTLY idx_orders_customer_date ON orders (customer_id, order_date) WHERE status = 'active'; -- Partition pruning optimization SELECT * FROM sales_data WHERE sale_date >= '2024-01-01' AND region = 'north_america';
Database Tuning Strategies
- Memory Management: Buffer pool optimization, cache hit ratio improvement
- Storage Optimization: I/O pattern analysis, SSD configuration, and data compression
- Connection Pooling: PgBouncer, ProxySQL, and connection lifecycle management
- Query Plan Analysis: Execution plan optimization and statistics maintenance
Scalability Architecture and Design
Horizontal Scaling Solutions
- Read Replica Management: Load balancing, lag monitoring, and failover automation
- Sharding Strategies: Consistent hashing, range-based partitioning, and cross-shard queries
- Microservices Database Patterns: Database per service, event sourcing, and CQRS implementation
Vertical Scaling Optimization
- Resource Allocation: CPU, memory, and storage capacity planning
- Auto-scaling Configuration: Dynamic resource adjustment based on workload patterns
- Performance Monitoring: Real-time metrics collection and alerting systems
High Availability and Disaster Recovery
Clustering and Replication
# Example: PostgreSQL streaming replication configuration # postgresql.conf wal_level = replica max_wal_senders = 3 wal_keep_segments = 64 archive_mode = on archive_command = 'cp %p /archive/%f' # recovery.conf (standby) standby_mode = 'on' primary_conninfo = 'host=primary port=5432 user=replicator' trigger_file = '/tmp/postgresql.trigger'
Backup and Recovery Strategies
- Point-in-Time Recovery (PITR): Continuous archiving and transaction log management
- Cross-Region Backup: Geo-distributed backup storage and recovery testing
- Automated Failover: Health monitoring, automatic promotion, and service continuity
Data Reliability Engineering
Data Integrity and Consistency
- ACID Compliance: Transaction isolation levels and consistency guarantees
- Data Validation: Constraint enforcement, referential integrity, and data quality checks
- Corruption Detection: Checksum validation, consistency verification, and repair procedures
Monitoring and Observability
# Example: Database health monitoring with custom metrics
import psycopg2
import time
from prometheus_client import Gauge, start_http_server
# Define metrics
db_connections = Gauge('postgresql_connections_total', 'Total database connections')
query_duration = Gauge('postgresql_query_duration_seconds', 'Query execution time')
def monitor_database():
conn = psycopg2.connect(database="production", user="monitor")
cursor = conn.cursor()
# Monitor active connections
cursor.execute("SELECT count(*) FROM pg_stat_activity;")
db_connections.set(cursor.fetchone()[0])
# Monitor slow queries
cursor.execute("""
SELECT avg(total_time)
FROM pg_stat_statements
WHERE calls > 100;
""")
avg_time = cursor.fetchone()[0]
if avg_time:
query_duration.set(avg_time / 1000) # Convert to seconds
Data Security and Compliance
Encryption and Access Control
- Encryption at Rest: Transparent Data Encryption (TDE), file-level encryption
- Encryption in Transit: SSL/TLS configuration, certificate management
- Role-Based Access Control (RBAC): Granular permissions, principle of least privilege
- Database Auditing: Activity logging, compliance reporting, and forensic analysis
Compliance Framework Support
- GDPR: Data anonymization, right to erasure, and consent management
- HIPAA: PHI protection, audit trails, and access controls
- SOX: Financial data integrity, change management, and audit requirements
- PCI DSS: Payment data security, tokenization, and secure storage
Analytics and Business Intelligence Integration
Real-Time Analytics Architecture
- Stream Processing: Apache Kafka integration, real-time data pipelines
- OLAP Optimization: Cube design, aggregation strategies, and query acceleration
- Data Warehouse Design: Star schema, snowflake schema, and dimensional modeling
Machine Learning and AI Integration
- Feature Store Management: Data versioning, feature engineering pipelines
- Model Serving Infrastructure: Real-time inference, batch prediction systems
- Vector Database Optimization: Embedding storage, similarity search, and indexing strategies
Operations Management and DevOps
Infrastructure as Code (IaC)
# Example: Terraform configuration for RDS deployment
resource "aws_db_instance" "production" {
identifier = "production-postgresql"
engine = "postgres"
engine_version = "15.4"
instance_class = "db.r6g.xlarge"
allocated_storage = 1000
max_allocated_storage = 5000
storage_type = "gp3"
storage_encrypted = true
db_name = "production"
username = "admin"
password = var.db_password
vpc_security_group_ids = [aws_security_group.database.id]
db_subnet_group_name = aws_db_subnet_group.main.name
backup_retention_period = 30
backup_window = "03:00-04:00"
maintenance_window = "sun:04:00-sun:05:00"
performance_insights_enabled = true
monitoring_interval = 60
tags = {
Environment = "production"
Service = "database"
}
}
Automation and Orchestration
- Database Provisioning: Automated deployment, configuration management
- Schema Migration: Version control, rollback strategies, and zero-downtime deployments
- Capacity Planning: Predictive scaling, resource optimization, and cost management
Why Choose MinervaDB Inc. for Database Infrastructure Engineering
Proven Expertise
- 15+ Years of database engineering experience across diverse industries
- Certified Professionals in major cloud platforms and database technologies
- Enterprise-Grade Solutions for Fortune 500 companies and high-growth startups
Comprehensive Service Portfolio
- 24/7 Database Support: Proactive monitoring, incident response, and performance optimization
- Migration Services: Zero-downtime database migrations and platform modernization
- Training and Knowledge Transfer: Team upskilling and best practices implementation
Technology-Agnostic Approach
- Multi-Database Expertise: Optimal technology selection based on specific requirements
- Cloud-Native Solutions: Kubernetes orchestration, containerized deployments
- Hybrid Architecture: On-premises, cloud, and multi-cloud database strategies
Get Started with Professional Database Infrastructure Engineering
Transform your database infrastructure with MinervaDB Inc.’s expert consulting services. Our team delivers scalable, secure, and high-performance database solutions tailored to your specific business requirements.
Contact our database infrastructure specialists today to discuss your performance optimization, scalability challenges, and operational excellence goals. Let us help you build a robust, future-ready database infrastructure that drives business success.
MinervaDB Inc. – Your trusted partner for enterprise database infrastructure engineering, analytics optimization, and operations management across all major database platforms and cloud environments.

Further Reading
- Unlocking the Power of Compound Wildcard Indexes in MongoDB 7.0
- Future-Proof Your Databases: The Strategic Guide to Proactive Database Optimization
- MinervaDB Full-Stack Engineering Operations and Support for NoSQL
- MinervaDB Inc. PostgreSQL Consulting Services: Enterprise Database Excellence
- MySQL 5.7 Virtual Columns
- Building Real-Time Analytics with ChistaDATA