Data Architecture, Engineering, and Operations in the CDN Industry: A Modern Approach with SQL, NoSQL, NewSQL, and Cloud-Native Platforms
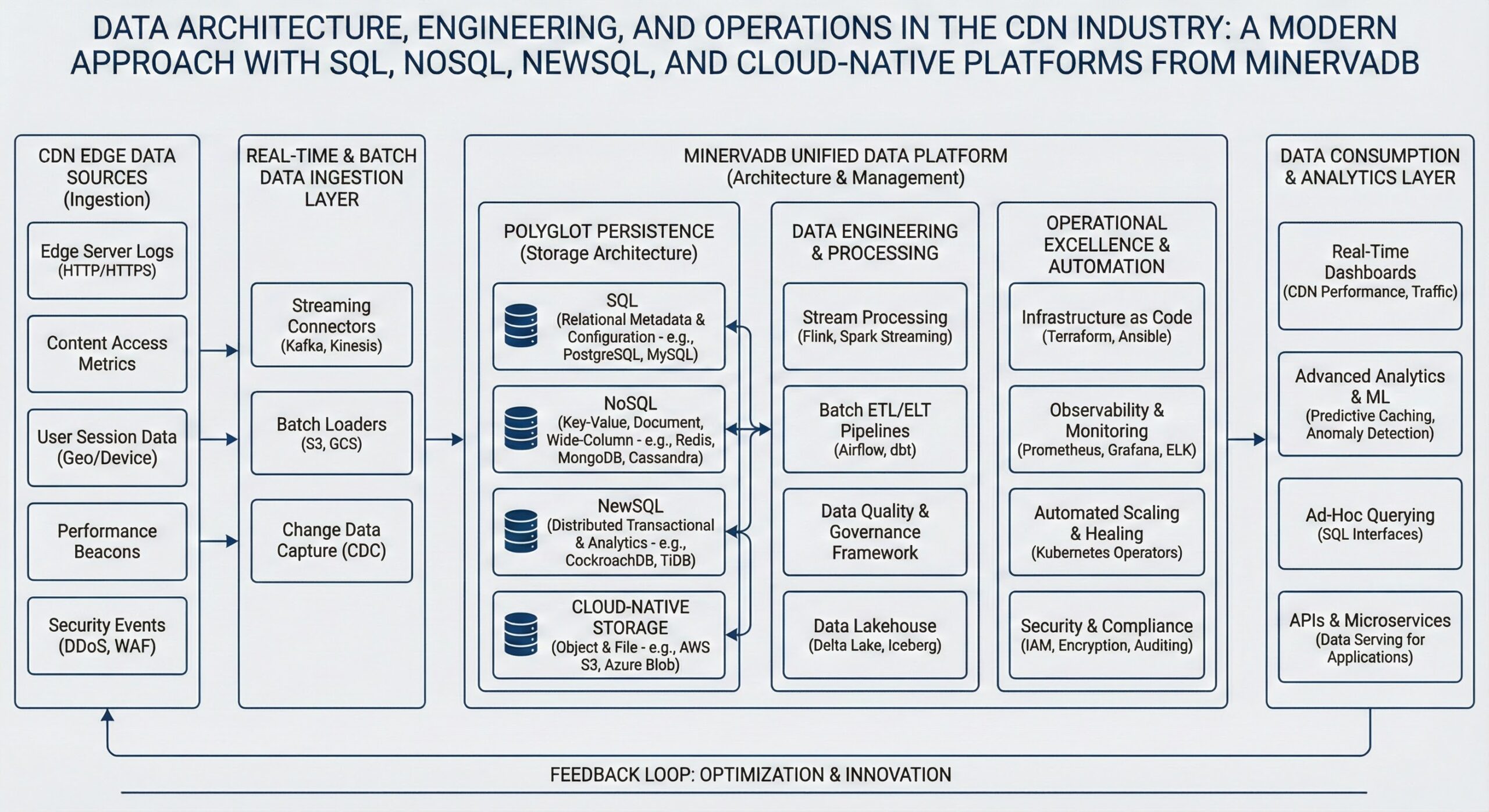
Data Architecture and Engineering for CDN: The Content Delivery Network (CDN) industry is at the heart of the digital experience, enabling fast, reliable, and secure delivery of web content across the globe. As user expectations rise and data volumes explode, CDNs must evolve beyond simple caching and content routing. Today’s CDNs generate petabytes of log data, real-time performance metrics, security events, and user behavior signals. Managing this data effectively requires a robust data architecture, sophisticated engineering practices, and resilient operations. This article explores how modern data platforms—Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse Analytics, and Databricks Lakehouse—are transforming data architecture, engineering, and operations for CDNs, enabling advanced analytics and AI-driven decision-making.
The Evolving Data Landscape in CDNs
Content Delivery Networks operate at massive scale, serving billions of requests per second across distributed edge nodes. Each request generates metadata: geolocation, device type, response time, cache hit/miss status, content type, and more. This data is critical for:
- Optimizing content delivery paths
- Detecting and mitigating DDoS attacks
- Improving cache efficiency
- Personalizing content delivery
- Forecasting traffic patterns
Traditionally, CDNs relied on monolithic databases and batch-processing systems. However, the shift toward real-time analytics, AI/ML integration, and hybrid cloud deployments demands a more flexible and scalable approach. This has led to the adoption of modern data architectures that combine SQL, NoSQL, NewSQL, and cloud-native data platforms.
Data Architecture for CDNs: Principles and Components
A modern data architecture for CDNs must support high ingestion rates, low-latency querying, and seamless integration across on-premises and cloud environments. It typically follows a layered approach:
1. Data Ingestion Layer
CDNs require high-throughput data ingestion to capture logs, metrics, and events from edge servers. Technologies like Apache Kafka, Amazon Kinesis, and Google Cloud Pub/Sub are commonly used to stream data in real time. These systems ensure durability, scalability, and fault tolerance.
2. Storage Layer
The storage layer must accommodate diverse data types:
- Structured data (e.g., user sessions, billing records) stored in SQL databases
- Semi-structured data (e.g., JSON logs, clickstreams) stored in data lakes or NoSQL databases
- Unstructured data (e.g., video content, images) stored in object storage
Cloud-native platforms like Snowflake and Databricks Lakehouse abstract storage complexity, allowing CDNs to focus on analytics rather than infrastructure management.
3. Processing Layer
This layer handles both batch and stream processing. Batch jobs process historical data for reporting and model training, while stream processing engines like Apache Flink or Spark Streaming enable real-time analytics. NewSQL databases such as Google Spanner offer strong consistency with horizontal scalability, ideal for transactional workloads in hybrid environments.
4. Analytics and AI Layer
The final layer enables business intelligence, machine learning, and AI applications. Cloud data warehouses and lakehouse platforms integrate seamlessly with BI tools and ML frameworks, allowing CDNs to derive actionable insights from their data.
Data Engineering Practices in CDN Environments
Data engineering in CDNs involves designing, building, and maintaining the pipelines that move data from edge nodes to analytical systems. Key practices include:
Schema Design and Data Modeling
Given the variety of data sources, CDNs often adopt flexible schema designs. For structured data, star or snowflake schemas are used in data warehouses to optimize query performance. For semi-structured data, schema-on-read approaches allow late binding of structure during analysis.
ETL and ELT Pipelines
CDNs leverage both ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) patterns. Traditional ETL is used for data cleansing and transformation before loading into data marts. ELT, enabled by cloud data warehouses with built-in compute, allows raw data to be loaded first and transformed in-database using SQL or Python.
Data Quality and Governance
Ensuring data accuracy, completeness, and consistency is critical. CDNs implement data validation rules, anomaly detection, and lineage tracking. Tools like Great Expectations and dbt (data build tool) help automate data quality checks and documentation.
Real-Time Data Processing
With the rise of live video streaming and interactive content, CDNs need real-time analytics. Stream processing frameworks process incoming data to detect anomalies, trigger alerts, or update dashboards instantly. For example, sudden spikes in error rates can indicate network issues or cyberattacks.
Data Operations: Monitoring, Scalability, and Security
Data operations ensure that data systems are reliable, performant, and secure. In CDNs, this includes:
Performance Monitoring
CDNs monitor query latency, throughput, and resource utilization across their data platforms. Automated alerting systems notify engineers of performance degradation or capacity bottlenecks.
Scalability and Elasticity
Cloud-native platforms offer auto-scaling capabilities, allowing CDNs to handle traffic surges without manual intervention. For instance, during major events like sports broadcasts or product launches, data ingestion and processing needs can increase dramatically.
Security and Compliance
CDNs handle sensitive user data and must comply with regulations like GDPR and CCPA. Data encryption (at rest and in transit), role-based access control (RBAC), and audit logging are standard practices. Secure data sharing features in platforms like Snowflake enable collaboration without compromising privacy.
Modern Data Platforms in the CDN Industry
The following platforms have become central to data architecture and engineering in CDNs, each offering unique strengths:
Snowflake: Independent Cloud Data Warehouse
Snowflake provides an independent cloud data warehouse with strong multi-cloud support and high scalability. Its architecture separates compute and storage, enabling independent scaling and cost optimization. CDNs use Snowflake for enterprise data consolidation, secure data sharing, and hybrid cloud deployments.
Key benefits for CDNs include:
- Multi-cloud flexibility: Operate across AWS, Azure, and GCP without vendor lock-in
- Secure data sharing: Share anonymized performance data with partners or customers
- Zero-copy cloning: Rapidly create test environments for analytics development
Snowflake integrates with data lakes and supports semi-structured data (e.g., JSON, Avro), making it ideal for processing CDN logs and metrics.
Google BigQuery: Serverless Analytics with AI Integration
Google BigQuery offers a serverless architecture with deep integration into the Google Cloud Platform (GCP) and advanced AI/ML capabilities. It enables real-time analytics on streaming data, log analysis, and AI-powered insights.
CDNs leverage BigQuery for:
- Real-time analytics: Analyze streaming logs to detect cache inefficiencies or security threats
- Machine learning: Use BigQuery ML to build models directly in SQL for traffic forecasting or anomaly detection
- Geospatial analysis: Leverage built-in geospatial functions to optimize content routing based on user location
BigQuery’s federated query capability allows CDNs to query data in Google Cloud Storage without loading it, reducing latency and cost.
Amazon Redshift: AWS-Native Data Warehousing
Amazon Redshift offers tight integration with the AWS ecosystem, cost-effective pricing models, and broad tool compatibility. It supports large-scale ETL pipelines, operational reporting, and data lake integration.
CDNs using AWS infrastructure benefit from:
- Seamless integration: Native connectivity with Amazon S3, Kinesis, and Lambda
- Redshift Spectrum: Query exabytes of data in S3 without loading it into Redshift
- Concurrency scaling: Automatically scale query capacity during peak loads
Redshift’s machine learning integration allows CDNs to deploy predictive models for capacity planning and failure prediction.
Azure Synapse Analytics: Unified Analytics for Hybrid Environments
Azure Synapse Analytics is a unified analytics service combining data integration, enterprise data warehousing, and big data analytics. It supports the modernization of SQL Server estates, Power BI integration, and hybrid cloud analytics.
For CDNs with existing Microsoft investments, Synapse offers:
- Unified experience: Single workspace for SQL, Spark, and data integration
- Power BI integration: Direct connectivity for real-time dashboards
- Hybrid analytics: Run queries across on-premises and cloud data sources
Synapse Pipelines enable CDNs to orchestrate complex data workflows, from ingestion to reporting.
Databricks Lakehouse: Combining Data Lakes and Warehouses
Databricks Lakehouse combines the flexibility of data lakes with the performance and governance of data warehouses. It supports advanced analytics, machine learning workflows, and real-time data processing.
CDNs use Databricks for:
- Unified data platform: Store raw and processed data in a single environment
- Delta Lake: Ensure data reliability with ACID transactions and schema enforcement
- MLflow integration: Manage the machine learning lifecycle from experimentation to deployment
Databricks’ collaborative notebooks enable data engineers, scientists, and analysts to work together on CDN optimization projects.
Comparative Overview of Key Platforms
The following table summarizes the core capabilities and use cases of the major data platforms in the CDN context:
| Platform | Key Features | Primary Use Cases in CDNs |
|---|---|---|
| Snowflake | Independent cloud data warehouse, multi-cloud support, high scalability | Enterprise data consolidation, secure data sharing, hybrid cloud deployments |
| Google BigQuery | Serverless architecture, deep GCP integration, AI/ML capabilities | Real-time analytics on streaming data, log analysis, AI-powered insights |
| Amazon Redshift | Tight AWS integration, cost-effective pricing, broad tool compatibility | Large-scale ETL pipelines, operational reporting, data lake integration |
| Azure Synapse Analytics | Unified analytics, data integration, enterprise data warehousing | Modernization of SQL Server estates, Power BI integration, hybrid cloud analytics |
| Databricks Lakehouse | Data lake flexibility with warehouse performance and governance | Advanced analytics, machine learning workflows, real-time data processing |
Each platform excels in different scenarios, and many CDNs adopt a multi-platform strategy based on workload requirements and cloud preferences.
Use Cases: Applying Data Platforms in CDN Operations
1. Real-Time Log Analysis for Performance Optimization
CDNs generate terabytes of log data daily. Analyzing this data in real time helps identify slow response times, cache misses, and network bottlenecks. Using Google BigQuery or Databricks, CDNs can run continuous queries on streaming logs to generate performance dashboards and trigger automated optimizations.
For example, if a particular edge node shows high latency, the system can reroute traffic or pre-warm caches based on predictive models.
2. Anomaly Detection and Security Monitoring
CDNs are frequent targets of DDoS attacks and bot traffic. Machine learning models trained on historical traffic patterns can detect anomalies in real time. Amazon Redshift and Databricks support integration with ML frameworks like SageMaker and MLflow, enabling CDNs to deploy and monitor detection models at scale.
3. Predictive Analytics for Capacity Planning
Traffic patterns in CDNs are highly variable. Predictive analytics models forecast demand based on historical trends, seasonal events, and external factors (e.g., news cycles). Snowflake and Azure Synapse provide the computational power and SQL interfaces needed to build and run these models efficiently.
4. Personalized Content Delivery
By analyzing user behavior and device characteristics, CDNs can personalize content delivery—serving optimized versions of videos, images, or web pages. Databricks Lakehouse enables CDNs to build recommendation engines using collaborative filtering or deep learning techniques.
5. Secure Data Sharing with Partners
CDNs often share performance and security data with content providers or ISPs. Snowflake’s secure data sharing feature allows CDNs to provide read-only access to specific datasets without copying or exposing underlying infrastructure.
Integrating SQL, NoSQL, and NewSQL in CDN Architectures
While cloud data warehouses dominate analytics, CDNs also rely on specialized databases for specific workloads:
SQL Databases
Relational databases like PostgreSQL, MySQL, and SQL Server are used for transactional systems such as billing, user management, and configuration stores. Their ACID compliance ensures data integrity.
NoSQL Databases
NoSQL databases like MongoDB, Cassandra, and DynamoDB handle high-velocity, schema-less data. CDNs use them for:
- Storing session data
- Managing device profiles
- Caching metadata
Their horizontal scalability makes them ideal for distributed edge environments.
NewSQL Databases
NewSQL databases like Google Spanner and CockroachDB offer the scalability of NoSQL with the consistency of SQL. Spanner’s global consistency model is particularly valuable for CDNs with worldwide operations, ensuring that configuration changes propagate uniformly across regions.
Cloud-Native Data Platforms: The Future of CDN Analytics
Cloud-native platforms are redefining how CDNs manage data. Their key advantages include:
- Elastic scalability: Automatically adjust resources based on demand
- Managed services: Reduce operational overhead with fully managed infrastructure
- Built-in AI/ML: Accelerate innovation with integrated machine learning tools
- Cost efficiency: Pay-per-use pricing aligns costs with actual consumption
As CDNs continue to expand their services—offering edge computing, serverless functions, and AI inference at the edge—the role of cloud-native data platforms will only grow.
Challenges and Considerations
Despite the benefits, adopting modern data platforms presents challenges:
Data Integration Complexity
Integrating data from hundreds of edge nodes into centralized platforms requires robust ETL/ELT pipelines. CDNs must invest in data engineering talent and tools to ensure reliability.
Cost Management
Cloud data platforms can become expensive if not monitored closely. Query optimization, data lifecycle policies, and reserved capacity purchases help control costs.
Skill Gaps
The shift to cloud-native and AI-driven analytics requires new skills in data engineering, machine learning, and cloud architecture. CDNs must invest in training or hiring specialized personnel.
Vendor Lock-In
While platforms like Snowflake offer multi-cloud support, others are tightly coupled to specific cloud providers. CDNs should evaluate long-term strategic implications before committing to a single vendor.
Conclusion
The CDN industry is undergoing a data revolution. As content delivery becomes more intelligent and personalized, the ability to collect, process, and analyze vast amounts of data is a competitive advantage. Modern data platforms—Snowflake, Google BigQuery, Amazon Redshift, Azure Synapse Analytics, and Databricks Lakehouse—are empowering CDNs to build scalable, secure, and AI-driven data architectures.
By leveraging these technologies, CDNs can optimize performance, enhance security, and deliver superior user experiences. The integration of SQL, NoSQL, NewSQL, and cloud-native platforms enables a flexible and future-proof approach to data engineering and operations.
As the lines between networking, computing, and data analytics blur, CDNs that embrace a data-centric mindset will lead the next generation of digital content delivery. The future belongs to those who can turn data into insight, and insight into action—in real time, at a global scale.
Further Reading: