Custom PostgreSQL Engineering Services: Advanced Performance and Scalability Solutions by MinervaDB
Enterprise-Grade PostgreSQL Infrastructure Engineering
MinervaDB delivers specialized custom PostgreSQL engineering services designed to address the most demanding performance and scalability challenges in enterprise database environments. Our engineering approach combines deep PostgreSQL internals expertise with systematic reliability engineering methodologies to build robust, high-performance database infrastructures that scale seamlessly with business growth.
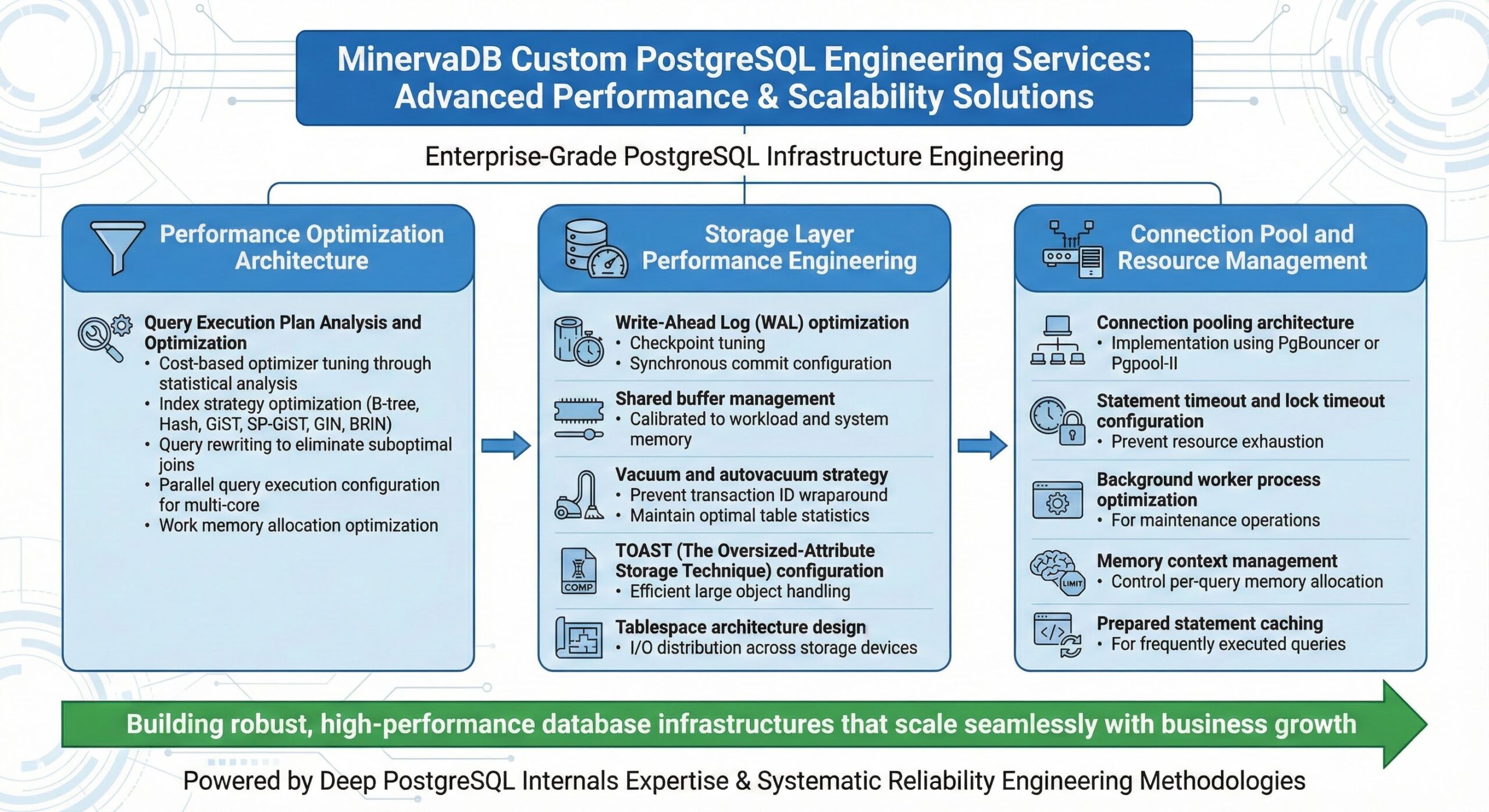
Performance Optimization Architecture
Query Execution Plan Analysis and Optimization
Our performance engineering methodology begins with comprehensive execution plan analysis to understand data access patterns and identify optimization opportunities. We employ advanced techniques including:
- Cost-based optimizer tuning through statistical analysis refinement
- Index strategy optimization utilizing B-tree, Hash, GiST, SP-GiST, GIN, and BRIN index types
- Query rewriting to eliminate suboptimal join operations and reduce computational complexity
- Parallel query execution configuration for multi-core processor utilization
- Work memory allocation optimization to minimize disk-based sorting and hashing operations
Storage Layer Performance Engineering
The storage subsystem represents a critical performance bottleneck in database operations. Our engineering services implement:
- Write-Ahead Log (WAL) optimization through checkpoint tuning and synchronous commit configuration
- Shared buffer management calibrated to workload characteristics and available system memory
- Vacuum and autovacuum strategy development to prevent transaction ID wraparound and maintain optimal table statistics
- TOAST (The Oversized-Attribute Storage Technique) configuration for efficient large object handling
- Tablespace architecture design for I/O distribution across storage devices
Connection Pool and Resource Management
Efficient resource utilization requires sophisticated connection management:
- Connection pooling architecture implementation using PgBouncer or Pgpool-II
- Statement timeout and lock timeout configuration to prevent resource exhaustion
- Background worker process optimization for maintenance operations
- Memory context management to control per-query memory allocation
- Prepared statement caching for frequently executed queries
Scalability Engineering Framework
Vertical Scaling Optimization
Maximizing single-node performance through:
- CPU affinity configuration for PostgreSQL processes
- NUMA (Non-Uniform Memory Access) awareness in memory allocation strategies
- Huge pages implementation to reduce TLB (Translation Lookaside Buffer) misses
- Kernel parameter tuning including shared memory segments and semaphore arrays
- Storage subsystem optimization with appropriate RAID configurations and filesystem selection
Horizontal Scaling Architecture
Building distributed PostgreSQL infrastructures for massive scale:
- Logical replication topology design for read scalability and geographic distribution
- Streaming replication configuration with synchronous and asynchronous modes
- Sharding strategy development using declarative partitioning or application-level distribution
- Foreign Data Wrapper (FDW) implementation for federated query processing
- Connection routing logic for intelligent read/write workload distribution
High Availability and Failover Engineering
Ensuring continuous database availability through:
- Patroni-based cluster management with automatic failover capabilities
- Replication slot management to prevent WAL segment removal during replica lag
- Cascading replication topologies for multi-tier availability architectures
- Point-in-Time Recovery (PITR) infrastructure with continuous WAL archiving
- Backup and recovery automation using pg_basebackup and WAL-E/WAL-G
Custom PostgreSQL Development Services
Extension Development and Integration
Extending PostgreSQL capabilities through:
- Custom procedural language development for specialized business logic execution
- Native extension programming in C for performance-critical operations
- Foreign Data Wrapper creation for heterogeneous data source integration
- Custom aggregate function development for domain-specific analytical operations
- Background worker implementation for asynchronous task processing
Database Schema Engineering
Optimizing data models for performance and scalability:
- Normalization and denormalization strategies balanced for query performance
- Partitioning scheme design using range, list, and hash partitioning methods
- Constraint optimization to leverage PostgreSQL’s constraint exclusion
- Data type selection considering storage efficiency and computational overhead
- Inheritance hierarchy design for polymorphic data modeling
Performance Monitoring and Observability
Instrumentation and Metrics Collection
Implementing comprehensive monitoring infrastructure:
- pg_stat_statements analysis for query performance profiling
- System catalog interrogation for object-level statistics
- Operating system metrics correlation with database performance indicators
- Custom metric collection using PostgreSQL’s statistics collector framework
- Wait event analysis to identify resource contention patterns
Proactive Performance Management
Establishing continuous optimization processes:
- Automated performance regression detection through baseline comparison
- Query plan stability monitoring to identify optimizer behavior changes
- Index usage analysis to eliminate redundant or unused indexes
- Table bloat measurement and remediation scheduling
- Lock contention identification and resolution strategies
Database Reliability Engineering (DRE)
Capacity Planning and Forecasting
Data-driven infrastructure scaling decisions:
- Workload characterization through transaction rate and query pattern analysis
- Resource utilization trending for proactive capacity expansion
- Growth modeling based on historical data accumulation rates
- Performance envelope definition establishing acceptable latency thresholds
- Scalability testing under synthetic load conditions
Disaster Recovery Architecture
Building resilient database infrastructures:
- Recovery Time Objective (RTO) optimization through hot standby configuration
- Recovery Point Objective (RPO) minimization via synchronous replication
- Geographic redundancy with multi-region deployment strategies
- Backup validation automation ensuring recoverability of archived data
- Failover procedure documentation and regular disaster recovery testing
Security and Compliance Engineering
Access Control and Authentication
Implementing defense-in-depth security:
- Role-Based Access Control (RBAC) design with principle of least privilege
- Row-Level Security (RLS) policies for multi-tenant data isolation
- SSL/TLS encryption configuration for data in transit protection
- Authentication method selection including SCRAM-SHA-256 and certificate-based authentication
- Audit logging configuration using pgAudit extension for compliance requirements
Data Protection Strategies
Safeguarding sensitive information:
- Transparent Data Encryption (TDE) implementation at filesystem or storage level
- Column-level encryption for sensitive data fields
- Data masking techniques for non-production environments
- Secure backup encryption using GPG or native backup tool encryption
- Key management infrastructure integration for cryptographic operations
Continuous Optimization and Support
MinervaDB’s custom PostgreSQL engineering services provide ongoing optimization through 24/7 consultative support, ensuring database infrastructures maintain peak performance as workloads evolve. Our engineering team continuously monitors PostgreSQL community developments, incorporating latest performance enhancements and security patches while maintaining stability in production environments.
Our methodology emphasizes proactive performance management rather than reactive troubleshooting, utilizing automated monitoring, alerting, and remediation workflows to prevent performance degradation before it impacts application responsiveness. This approach minimizes downtime and ensures consistent query latency even under variable workload conditions.
Core Technical Competencies: MinervaDB’s PostgreSQL Engineering Expertise
Deep PostgreSQL Internals Mastery
MinervaDB’s technical foundation rests on comprehensive understanding of PostgreSQL core architecture at the lowest levels. This expertise encompasses:
Query Processing and Optimization Engine
- Cost-based optimizer internals including statistics collection mechanisms, selectivity estimation algorithms, and join order determination
- Execution plan generation with detailed knowledge of scan methods (Sequential, Index, Bitmap, TID), join algorithms (Nested Loop, Hash Join, Merge Join), and aggregation strategies
- Parallel query execution framework understanding worker process coordination, shared memory communication, and parallel-safe function identification
- Query rewrite rule system expertise in view materialization, subquery flattening, and predicate pushdown optimization
Storage Layer Architecture
- MVCC (Multi-Version Concurrency Control) implementation including transaction snapshot management, tuple visibility determination, and version chain traversal
- Write-Ahead Logging (WAL) subsystem with deep knowledge of record formats, checkpoint mechanics, and crash recovery protocols
- Buffer management algorithms including clock sweep replacement policy, dirty page tracking, and background writer coordination
- TOAST mechanism internals understanding compression algorithms, out-of-line storage strategies, and detoasting optimization
Memory Management Systems
- Memory context hierarchy with expertise in allocation strategies, context lifecycle management, and memory leak prevention
- Shared memory architecture including buffer pools, lock tables, and inter-process communication structures
- Work memory allocation for sort operations, hash tables, and bitmap index scans
- Maintenance work memory optimization for vacuum, index creation, and foreign key validation operations
Advanced Performance Engineering Capabilities
Systematic Performance Analysis Methodology
- Execution plan interpretation identifying cost estimation errors, cardinality mismatches, and suboptimal access paths
- Wait event analysis using pg_stat_activity and system-level tracing to diagnose resource contention
- Lock hierarchy understanding including table-level, row-level, advisory, and predicate locks with deadlock resolution strategies
- I/O pattern analysis correlating database operations with storage subsystem behavior through iostat, blktrace, and filesystem metrics
Index Strategy Expertise
- B-tree index optimization including fill factor tuning, index bloat management, and partial index design
- Specialized index types with practical application knowledge of GiST for geometric data, GIN for full-text search and JSONB, SP-GiST for non-balanced structures, and BRIN for large sequential datasets
- Index-only scan enablement through VACUUM visibility map maintenance and covering index design
- Expression and functional indexes for computed column optimization and case-insensitive searches
Vacuum and Maintenance Operations
- Autovacuum tuning with precise configuration of cost-based delay mechanisms, worker allocation, and threshold calculations
- Transaction ID wraparound prevention through aggressive vacuum scheduling and freeze age monitoring
- Table and index bloat remediation using pg_repack, VACUUM FULL, and CLUSTER operations with minimal downtime strategies
- Statistics collection optimization balancing accuracy with analysis overhead through targeted column statistics and extended statistics objects
Scalability Architecture Design
Replication Technology Mastery
- Streaming replication internals including WAL sender/receiver processes, replication slots, and feedback mechanisms
- Logical replication architecture with publication/subscription model understanding, conflict resolution strategies, and selective table replication
- Synchronous replication modes implementing quorum-based commits and understanding performance implications
- Cascading replication topologies for multi-tier architectures reducing primary server load
Partitioning and Sharding Strategies
- Declarative partitioning implementation using range, list, and hash methods with partition pruning optimization
- Constraint exclusion techniques for legacy partitioning schemes and query optimization
- Partition-wise join and aggregation enabling parallel processing across partition boundaries
- Application-level sharding with consistent hashing algorithms, shard key selection, and cross-shard query coordination
Connection Management Architecture
- PgBouncer configuration including transaction pooling, session pooling, and statement pooling modes with connection lifecycle management
- Pgpool-II implementation for load balancing, connection pooling, and query routing with health check mechanisms
- Connection state management understanding prepared statements, temporary tables, and session variables in pooled environments
- Connection limit optimization balancing max_connections with system resources and connection overhead
High Availability and Resilience Engineering
Cluster Management Expertise
- Patroni-based HA clusters with etcd/Consul/ZooKeeper integration for distributed consensus
- Automatic failover logic including leader election algorithms, split-brain prevention, and fencing mechanisms
- Replication lag monitoring with configurable thresholds and automatic promotion delay strategies
- Switchover orchestration for planned maintenance with zero-downtime procedures
Backup and Recovery Architecture
- Physical backup strategies using pg_basebackup with incremental backup capabilities and compression optimization
- Logical backup techniques with pg_dump parallelization and selective schema/table extraction
- Point-in-Time Recovery (PITR) implementation including WAL archiving, recovery target specification, and timeline management
- Continuous archiving systems using WAL-E, WAL-G, or pgBackRest with cloud storage integration
Disaster Recovery Planning
- Recovery Time Objective (RTO) optimization through hot standby configuration and automated failover
- Recovery Point Objective (RPO) minimization via synchronous replication and archive validation
- Geographic redundancy with multi-region deployment and network latency considerations
- Backup validation automation including restore testing and data integrity verification
Custom Development and Extension Engineering
PostgreSQL Extension Development
- C-language extension programming with PostgreSQL API knowledge including SPI (Server Programming Interface), memory contexts, and error handling
- Procedural language implementation creating custom PL handlers for domain-specific languages
- Foreign Data Wrapper (FDW) development implementing data source connectors with pushdown optimization
- Background worker processes for asynchronous task execution and custom maintenance operations
Advanced SQL and PL/pgSQL Programming
- Complex query optimization using CTEs, window functions, and lateral joins for analytical workloads
- Stored procedure development with exception handling, dynamic SQL, and cursor management
- Trigger implementation for data validation, audit logging, and derived data maintenance
- Custom aggregate and window functions for specialized analytical operations
Schema Design Optimization
- Normalization/denormalization trade-offs balancing data integrity with query performance
- Data type selection considering storage efficiency, index performance, and computational overhead
- Constraint design leveraging check constraints, exclusion constraints, and foreign keys for data integrity
- Inheritance and table partitioning for polymorphic data modeling and query optimization
Monitoring and Observability Infrastructure
Instrumentation Expertise
- pg_stat_statements analysis for query performance profiling and workload characterization
- System catalog interrogation extracting metadata from pg_stat_* views and information_schema
- Custom metrics collection using PostgreSQL statistics collector framework and extension development
- Operating system correlation linking database metrics with CPU, memory, disk, and network performance
Performance Baseline Management
- Automated regression detection comparing current performance against historical baselines
- Query plan stability monitoring identifying optimizer changes and statistics drift
- Capacity forecasting using time-series analysis and growth modeling
- Alerting threshold calibration reducing false positives while ensuring timely incident detection
Security and Compliance Implementation
Access Control Architecture
- Role-Based Access Control (RBAC) with hierarchical role inheritance and privilege management
- Row-Level Security (RLS) policies for multi-tenant data isolation and fine-grained access control
- Authentication mechanisms including SCRAM-SHA-256, LDAP integration, and certificate-based authentication
- SSL/TLS configuration for encrypted connections with certificate management
Data Protection Strategies
- Encryption at rest using filesystem-level encryption, storage-level encryption, or transparent data encryption
- Column-level encryption with pgcrypto extension for sensitive data fields
- Audit logging using pgAudit extension for compliance requirements and security monitoring
- Data masking techniques for non-production environments protecting sensitive information
Database Reliability Engineering (DRE) Methodology
Proactive Capacity Planning
- Workload characterization through transaction rate analysis, query pattern identification, and resource utilization trending
- Growth modeling based on historical data accumulation and business projections
- Performance envelope definition establishing acceptable latency thresholds and throughput requirements
- Scalability testing under synthetic load conditions using pgbench and custom workload generators
Continuous Optimization Framework
- Automated maintenance scheduling for vacuum, analyze, and reindex operations
- Index usage analysis identifying redundant, unused, or missing indexes
- Table bloat measurement with automated remediation workflows
- Configuration drift detection ensuring consistency across database clusters
Technical Leadership and Knowledge Transfer
PostgreSQL Community Engagement
- Core PostgreSQL knowledge staying current with latest releases, features, and performance improvements
- Patch evaluation and testing assessing security updates and bug fixes for production deployment
- Feature adoption strategy evaluating new capabilities for enterprise applicability
- Version upgrade planning with compatibility testing and migration path development
Consultative Technical Approach
- Architecture review methodology assessing existing implementations against best practices
- Performance audit procedures systematic evaluation of configuration, schema design, and query patterns
- Capacity planning workshops collaborative forecasting with stakeholder input
- Knowledge transfer programs documenting solutions and training internal teams
Synthesis of Technical Competencies
MinervaDB’s core technical skill derives from the integration of deep PostgreSQL internals knowledge with systematic engineering methodologies across all database infrastructure layers. This comprehensive expertise spans:
- Low-level understanding of PostgreSQL source code, memory management, and storage mechanisms
- Performance optimization through systematic analysis, measurement, and tuning
- Scalability architecture designing systems that grow horizontally and vertically
- Reliability engineering implementing high availability and disaster recovery
- Custom development extending PostgreSQL capabilities for specific requirements
- Security implementation protecting data through multiple defense layers
- Operational excellence maintaining systems through proactive monitoring and maintenance
This multidimensional technical foundation enables MinervaDB to deliver enterprise-grade PostgreSQL solutions that address complex performance and scalability challenges while maintaining reliability, security, and operational efficiency. The breadth and depth of expertise across query optimization, storage architecture, replication technologies, extension development, and reliability engineering demonstrates the comprehensive technical capability required for mission-critical database infrastructure.
Technology Focus
| Category | Technology | Enterprise Ready | 24/7 Support |
|---|---|---|---|
| SQL Databases | PostgreSQL | ✓ | ✓ |
| MySQL | ✓ | ✓ | |
| MariaDB | ✓ | ✓ | |
| SQL Server | ✓ | ✓ | |
| SAP HANA | ✓ | ✓ | |
| NoSQL Document | MongoDB | ✓ | ✓ |
| CouchDB | ✓ | ✓ | |
| NoSQL Key-Value | Redis | ✓ | ✓ |
| Valkey | ✓ | ✓ | |
| NoSQL Wide-Column | Cassandra | ✓ | ✓ |
| HBase | ✓ | ✓ | |
| NoSQL Graph | Neo4j | ✓ | ✓ |
| Analytics | ClickHouse | ✓ | ✓ |
| Trino | ✓ | ✓ | |
| Vertica | ✓ | ✓ | |
| GreenPlum | ✓ | ✓ | |
| NewSQL | CockroachDB | ✓ | ✓ |
| TiDB | ✓ | ✓ | |
| Vector Databases | Milvus | ✓ | ✓ |
| Pinecone | ✓ | ✓ | |
| Cloud Platforms | AWS RDS | ✓ | ✓ |
| Azure SQL | ✓ | ✓ | |
| Google Cloud SQL | ✓ | ✓ | |
| Google AlloyDB | ✓ | ✓ | |
| Amazon Aurora | ✓ | ✓ | |
| Snowflake | ✓ | ✓ | |
| Databricks | ✓ | ✓ | |
| BigQuery | ✓ | ✓ | |
| Redshift | ✓ | ✓ | |
| MySQL HeatWave | ✓ | ✓ |
Further Reading
- PostgreSQL Engineering with MinervaDB
- 24/7 PostgreSQL Remote DBA Services
- Data Strategy and Analytics
- Data Architecture and Engineering Services
- PostgreSQL Health Check