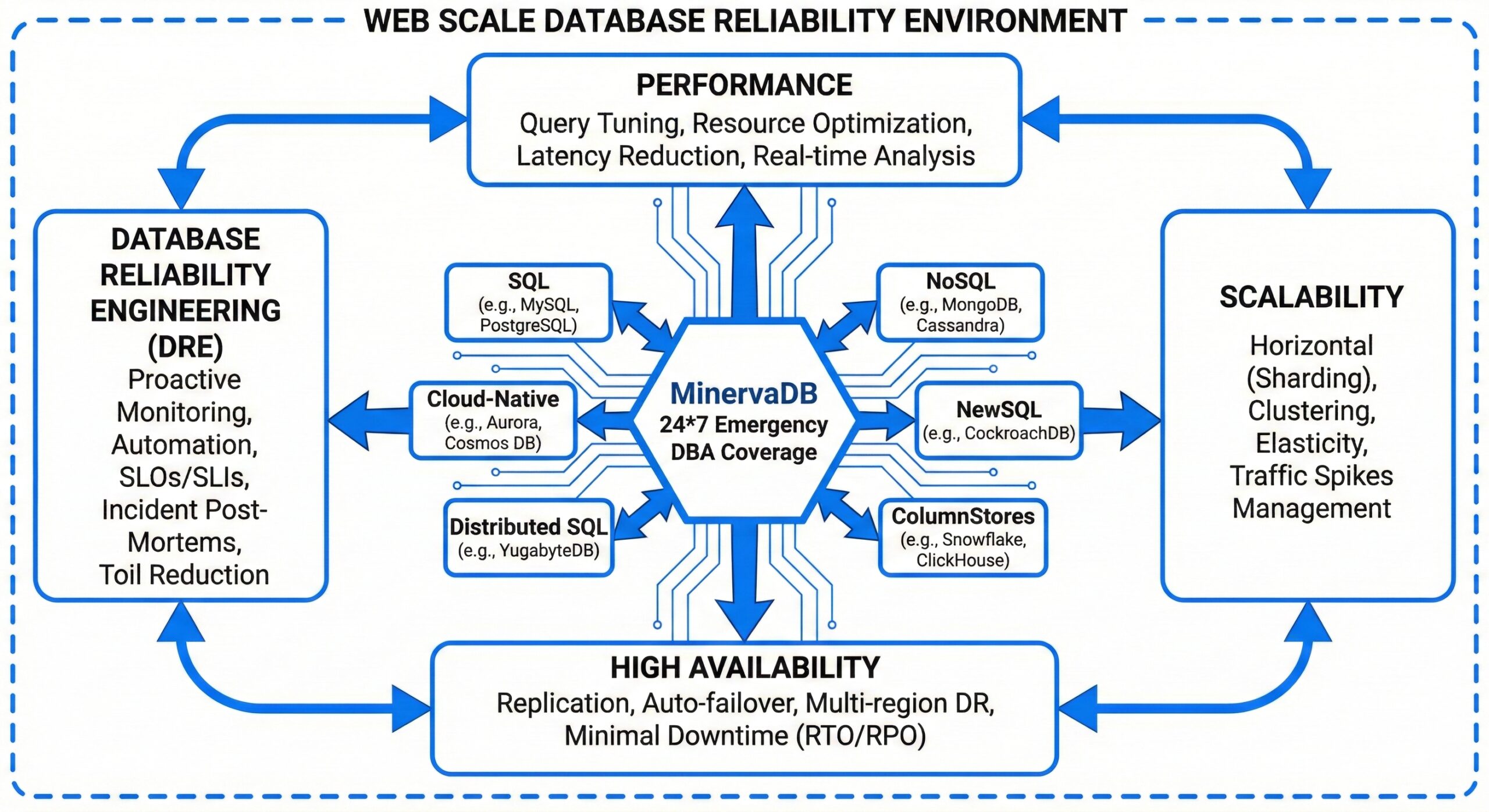
24*7 Emergency DBA Coverage from MinervaDB – SQL, NoSQL, NewSQL, ColumnStores, Distributed SQL & Cloud-Native Database Reliability at Web Scale addressing Performance, Scalability, High Availability, and Database Reliability Engineering
In today’s hyper-connected digital landscape, database downtime is not just an inconvenience—it’s a business-critical emergency. For enterprises operating at web scale, the reliability, performance, and availability of databases directly impact revenue, customer trust, and operational continuity. Whether you’re running mission-critical transactional systems, real-time analytics platforms, or globally distributed applications, any disruption in database services can cascade into significant financial and reputational damage.
This is where MinervaDB’s 24/7 Emergency DBA Coverage becomes an indispensable asset. Designed for organizations leveraging diverse database technologies—including SQL, NoSQL, NewSQL, ColumnStores, Distributed SQL, and Cloud-Native databases—our comprehensive support model ensures maximum uptime, rapid incident resolution, and proactive reliability engineering.
The Evolving Database Landscape at Web Scale
Modern applications are no longer built on monolithic architectures with a single relational database. Instead, they rely on a polyglot persistence model, integrating multiple database types tailored to specific workloads:
- SQL Databases: Traditional relational systems like PostgreSQL, MySQL, and SQL Server remain foundational for ACID-compliant transactions and structured data management.
- NoSQL Databases: Systems like MongoDB, Cassandra, and Redis offer flexible schemas, horizontal scalability, and high performance for unstructured or semi-structured data.
- NewSQL Databases: Emerging platforms such as Google Spanner, CockroachDB, and YugabyteDB combine the scalability of NoSQL with the consistency guarantees of traditional SQL.
- ColumnStores: Analytical databases like Amazon Redshift, Snowflake, and ClickHouse optimize query performance for large-scale data warehousing and business intelligence.
- Distributed SQL: Architectures that distribute data across nodes while maintaining SQL interfaces and strong consistency, ideal for global applications.
- Cloud-Native Databases: Purpose-built for cloud environments, these databases (e.g., Aurora, Firestore, Cosmos DB) offer elasticity, managed operations, and seamless integration with DevOps pipelines.
Each of these systems presents unique operational challenges, especially when deployed at scale. A one-size-fits-all approach to database administration fails to address the nuanced requirements of each technology.
Why 24/7 Emergency DBA Coverage Matters
Downtime costs enterprises an average of $5,600 per minute, according to industry studies . For e-commerce platforms, SaaS providers, financial institutions, and healthcare systems, even a few minutes of database unavailability can result in:
- Lost transactions and revenue
- Degraded user experience and customer churn
- Violation of SLAs and contractual penalties
- Regulatory non-compliance (e.g., GDPR, HIPAA)
- Damage to brand reputation
Traditional DBA teams often operate within standard business hours, leaving systems vulnerable during nights, weekends, and holidays. Reactive break-fix models delay response times, prolong outages, and increase mean time to recovery (MTTR).
MinervaDB’s 24/7 Emergency DBA Coverage eliminates this gap by providing continuous monitoring, instant alerting, and immediate expert intervention—anytime, anywhere. Our global team of certified database engineers specializes in multi-vendor, multi-platform environments, ensuring rapid diagnosis and resolution of critical incidents.
Core Pillars of MinervaDB’s Emergency DBA Service
1. Performance Optimization Under Pressure
Database performance degradation often precedes full outages. Slow queries, lock contention, memory leaks, and inefficient indexing can silently erode application responsiveness.
Our emergency DBAs employ advanced diagnostic tools and deep expertise to:
- Identify and kill long-running or blocking queries
- Optimize execution plans in real time
- Adjust configuration parameters (e.g., buffer pool size, query cache)
- Implement hot fixes for performance bottlenecks
For example, in a recent incident involving a PostgreSQL-based analytics platform, our team detected a missing index on a partitioned table causing full scans. Within 15 minutes, we created the necessary partial index and reduced query latency from 45 seconds to under 200 milliseconds.
We also support query tuning for complex NoSQL workloads. In MongoDB environments, we analyze slow query logs, optimize aggregation pipelines, and recommend shard key strategies to prevent hotspots.
2. Scalability Assurance During Traffic Spikes
Web-scale applications experience unpredictable traffic patterns—flash sales, viral content, or seasonal peaks can overwhelm database resources.
MinervaDB’s emergency coverage includes immediate scalability interventions:
- Vertical Scaling: Rapid provisioning of additional CPU, RAM, or I/O capacity
- Horizontal Scaling: Adding read replicas, sharding data, or rebalancing clusters
- Auto-Scaling Configuration: Tuning cloud-native auto-scaling policies to respond faster to load changes
In a case involving a retail client using Amazon Aurora, a sudden surge in traffic during Black Friday caused connection pool exhaustion. Our on-call DBA resized the instance class and adjusted the max_connections parameter within minutes, restoring service before any customer impact was reported.
For distributed SQL databases like CockroachDB, we assist with zone configuration, leaseholder balancing, and range replication tuning to maintain performance across regions.
3. High Availability and Disaster Recovery
High availability (HA) is not just about redundancy—it’s about automated failover, data consistency, and minimal RPO/RTO.
Our emergency DBAs are trained to handle HA failures across all major platforms:
- Failover Activation: Triggering manual or automated failover when primary nodes fail
- Replication Lag Resolution: Diagnosing and resolving replication delays in master-slave or multi-master setups
- Quorum Restoration: Re-establishing cluster consensus in distributed systems (e.g., etcd, ZooKeeper)
- Backup Validation and Recovery: Restoring from backups when corruption occurs
When a financial services client experienced a network partition in their Cassandra cluster, our team executed a controlled repair process, rebuilt hinted handoffs, and validated data consistency across all nodes—ensuring no transaction loss.
We also conduct regular DR drills and maintain runbooks for common failure scenarios, enabling faster response during actual emergencies.
4. Database Reliability Engineering (DRE)
Beyond reactive support, MinervaDB embraces Database Reliability Engineering—a proactive discipline combining SRE principles with deep database expertise.
Key DRE practices include:
- Incident Post-Mortems: Conducting blameless root cause analysis after every major incident
- SLO/SLI Definition: Establishing measurable reliability targets for databases
- Chaos Engineering: Intentionally injecting failures to test resilience
- Automation of Remediation: Creating scripts and playbooks for common issues
By treating databases as production-critical services, we shift from a reactive “break-fix” model to a proactive “prevent-fail” mindset.
Technology-Specific Emergency Support
SQL Databases
For traditional RDBMS platforms, our emergency coverage includes:
- Deadlock resolution and transaction log management
- Index rebuilds and statistics updates
- Storage space emergency expansion
- Point-in-time recovery (PITR) from WAL logs
We support Oracle, SQL Server, PostgreSQL, MySQL, and MariaDB with version-specific expertise.
NoSQL Databases
NoSQL systems introduce different failure modes:
- MongoDB: Replica set election issues, oplog overflow, memory fragmentation
- Cassandra: Hinted handoff backlog, compaction storms, tombstone overload
- Redis: Memory exhaustion, persistence failures, cluster node failures
Our DBAs use native tools like mongostat, nodetool, and redis-cli to diagnose and resolve issues in real time.
NewSQL & Distributed SQL
These systems blend complexity from both relational and distributed systems:
- Google Spanner: Lock contention in interleaved tables, leader lease issues
- CockroachDB: Range unavailability, leaseholder imbalance, clock skew
- YugabyteDB: Transaction conflicts, tablet server failures
We provide immediate access to engineers who understand consensus algorithms (Raft, Paxos), distributed transactions, and quorum-based availability.
ColumnStore Databases
Analytical workloads demand specialized support:
- Snowflake: Warehouse auto-suspend/resume issues, credit exhaustion
- Redshift: Vacuum and analyze bottlenecks, sort key inefficiencies
- ClickHouse: Merge tree corruption, ZooKeeper dependency failures
Our team optimizes query execution, manages storage tiers, and ensures data freshness during emergency scenarios.
Cloud-Native Databases
Managed services reduce operational overhead but don’t eliminate risks:
- Amazon Aurora: Failover delays, replication lag, parameter group misconfigurations
- Azure SQL Database: DTU/vCore limits, geo-replication breaks
- Google Cloud SQL: Backup failures, SSL certificate expiration
We work closely with cloud provider APIs and support channels to escalate and resolve issues beyond customer control.
The MinervaDB Advantage
Global Expertise, Local Response
Our DBAs are certified across AWS, Google Cloud, Microsoft Azure, and on-premises environments. With team members distributed across time zones, we ensure local response times with global knowledge sharing.
Multi-Model Database Proficiency
Unlike single-vendor specialists, MinervaDB supports over 25 database technologies. This breadth allows us to manage hybrid and multi-cloud deployments seamlessly.
Proactive Monitoring & Alerting
We integrate with your existing monitoring stack (Prometheus, Datadog, New Relic, etc.) or deploy our own agents to detect anomalies before they become outages.
Custom alerting rules trigger immediate notifications to our on-call engineers, who triage and respond within SLA-defined windows (e.g., 15-minute response for P1 incidents).
Seamless Integration with DevOps
Our emergency DBAs collaborate with your development and operations teams through:
- API-driven incident reporting
- ChatOps integrations (Slack, Microsoft Teams)
- CI/CD pipeline hooks for database changes
- Infrastructure-as-Code (IaC) reviews for Terraform, Ansible, etc.
This ensures database operations are aligned with modern software delivery practices.
Real-World Emergency Scenarios
E-Commerce Platform Outage
During a major sales event, a client’s MySQL database hit 100% CPU due to a rogue reporting query. Our DBA identified the query, killed the session, and implemented a read replica for analytics—restoring checkout functionality in under 10 minutes.
Healthcare Application Data Corruption
A hospital’s PostgreSQL database suffered index corruption after an ungraceful shutdown. Using pg_dump and point-in-time recovery, we restored the database from WAL archives with zero data loss.
SaaS Application Scaling Failure
A startup’s MongoDB cluster failed to auto-scale during a user growth spike. Our team manually added shards, rebalanced data, and reconfigured auto-scaling policies to prevent recurrence.
Service Tiers and SLAs
MinervaDB offers tiered emergency DBA coverage to match business needs:
| Tier | Response Time | Availability | Included Services |
|---|---|---|---|
| Standard | < 60 minutes | Business Hours (8x5) | Monitoring, Break-Fix, Advisory |
| Premium | < 15 minutes | 24x7 | Full Emergency Coverage, DRE, DR Planning |
| Enterprise | < 5 minutes | 24x7 + On-Demand | Dedicated DBA, Proactive Optimization, Custom Runbooks |
All tiers include secure access via SSH, API, or bastion hosts, with strict adherence to SOC 2, ISO 27001, and GDPR compliance standards.
Building a Resilient Database Strategy
While emergency coverage is crucial, the ultimate goal is to minimize the need for it. MinervaDB helps clients build resilient database architectures through:
- Architecture Reviews: Assessing design for scalability and fault tolerance
- Capacity Planning: Forecasting growth and provisioning resources
- Patch Management: Scheduling updates with minimal downtime
- Backup Validation: Regularly testing restore procedures
- Chaos Testing: Simulating network partitions, node failures, and latency spikes
By combining proactive engineering with reactive emergency support, we create a comprehensive database reliability program.
Conclusion: Database Reliability as a Competitive Advantage
In the era of always-on digital services, database reliability is no longer just an IT concern—it’s a strategic differentiator. Organizations that invest in robust, scalable, and highly available data infrastructure gain significant advantages in customer satisfaction, operational efficiency, and market agility.
MinervaDB’s 24/7 Emergency DBA Coverage delivers peace of mind by ensuring that no matter when or where a database emergency occurs, expert help is always available. From traditional SQL systems to cutting-edge distributed databases, our multi-model expertise, proactive DRE practices, and rapid response capabilities make us the trusted partner for enterprises operating at web scale.
Don’t wait for the next outage to test your database resilience. Partner with MinervaDB today and transform your database operations from a potential liability into a foundation of reliability and performance.
Contact us to schedule a free database health assessment and discover how our 24/7 Emergency DBA Coverage can safeguard your mission-critical applications around the clock.
Further Reading
- Remote DBA Support
- Enterprise Database Systems Support
- Data Analytics and Engineering
- PostgreSQL Support
- PostgreSQL Consulting
- PostgreSQL Remote DBA
- MySQL DBA Support
- MariaDB DBA Support
- NoSQL Support