Composite indexes in PostgreSQL
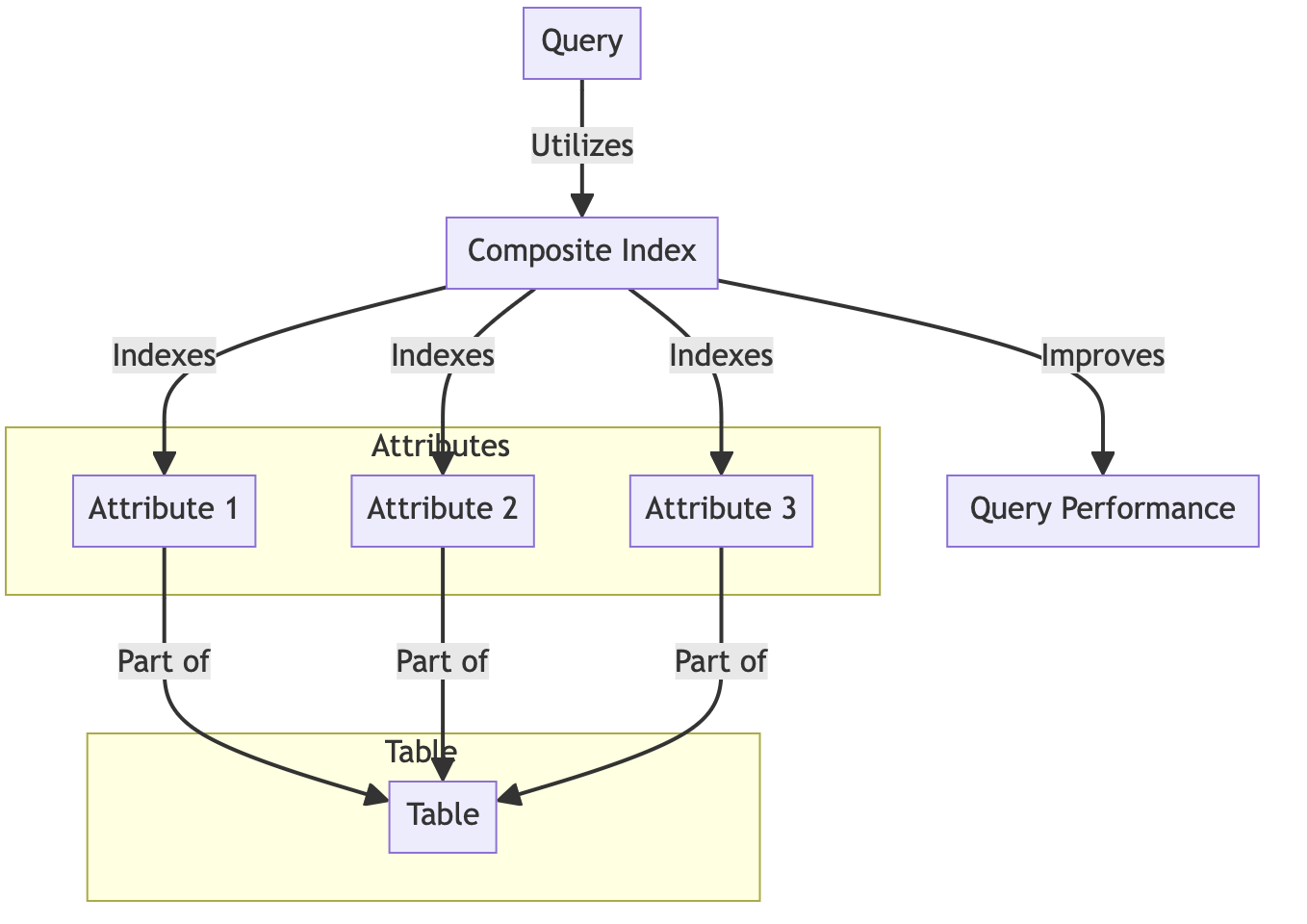
Composite indexes in PostgreSQL are a powerful tool designed to optimize database performance. They are a type of database index that encompasses more than one column of a table, making them specifically beneficial for complex queries involving multiple columns.
The functionality of composite indexes stems from creating a unique data structure that stores specified column values and row pointers. This structure allows PostgreSQL to avoid scanning the entire table by directly referencing the index for faster query execution. Consequently, this setup significantly improves query performance by enabling quicker retrieval of matching rows without unnecessary scans. By leveraging composite indexes, PostgreSQL efficiently optimizes data retrieval, reducing response time for complex queries.
However, using composite indexes comes with important considerations, primarily the overhead they add due to additional disk space consumption. This occurs because each row in the table generates an entry in the index, consuming extra storage. Furthermore, composite indexes can slow down insert and update operations since the index must be updated whenever a row changes. If a table has many indexes or includes several columns, these operations may experience significant delays, negatively impacting overall performance.
Therefore, understanding composite indexes and their impact on database operations is crucial for efficient database management and query performance.
Implementation and Use Cases of Composite Indexes in PostgreSQL
Implementing a composite index in PostgreSQL requires specifying the columns to be indexed during the CREATE INDEX operation. The syntax is straightforward: CREATE INDEX index_name ON table_name (column1, column2, …), where you list the columns in the desired order. The order of the columns is crucial, as it directly affects the index’s efficiency, especially for queries that don’t use all the indexed columns. Consequently, choosing the right column order ensures optimal performance for the most common query patterns in your database.
Composite indexes are ideal for queries that frequently involve multiple columns in the WHERE clause, significantly improving query execution speed. For instance, in an employee table with ‘last_name’ and ‘first_name’ columns, a composite index optimizes searches involving both fields together. Similarly, composite indexes enhance performance for JOIN operations that utilize multiple columns, providing faster data retrieval. However, they are most effective when the indexed columns exhibit high cardinality, as this ensures better efficiency and faster data retrieval in queries.
Practice dataset
Let’s consider a practice dataset employees with columns employee_id, first_name, last_name, email, and department.
Here’s the SQL command to create a composite index on first_name and last_name:
CREATE INDEX idx_employee_names ON employees (first_name, last_name);
Now, when you run a query that involves both first_name and last_name in the WHERE clause, PostgreSQL can use this composite index to speed up the search.
For example:
SELECT * FROM employees WHERE first_name = 'John' AND last_name = 'Doe';
Similarly, if you often run queries that join employees with another table departments based on department and employee_id, you might consider a composite index on these columns:
CREATE INDEX idx_employee_dept ON employees (department, employee_id);
This composite index could speed up a JOIN operation like this:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
JOIN departments d ON e.department = d.department_id AND e.employee_id = d.manager_id;
Maximizing Composite Index Effectiveness: Best Practices for Query Optimization and Performance Testing
Remember, composite indexes are powerful tools, but their effectiveness depends on careful consideration of your query patterns and data characteristics. To use them effectively, it’s essential to analyze how your queries interact with the indexed columns and adjust accordingly. Always test different index configurations to identify the optimal solution for your specific use case and ensure maximum performance. Consequently, performing regular tests can help refine index strategies, leading to better query execution and system efficiency.
- Selecting the wrong columns:
Composite indexes are created on multiple columns to optimize queries that frequently use these columns together in the WHERE clause. However, if you select columns that are rarely used together in queries, the composite index will not enhance performance. Instead, it may negatively impact performance by introducing additional overhead during data insertion and updates. Therefore, it’s essential to carefully choose columns for composite indexes to ensure they align with common query patterns and improve overall efficiency. - Incorrect column order:
The sequence of columns in a composite index plays a crucial role in determining its overall efficiency and effectiveness. PostgreSQL can utilize a composite index only when the query conditions involve the first column or the first and second columns, and so on. However, if your queries commonly use only the second or third column independently, PostgreSQL cannot leverage the index effectively, resulting in inefficient query execution. Consequently, maintaining the correct order of columns in a composite index is essential for optimizing query performance and resource usage. - Over-indexing:
While indexes are designed to speed up read operations, they introduce overhead that can slow down write operations. Each data insertion or update requires an update to the index, which can significantly impact performance. If a table is over-indexed, with too many indexes or indexes containing many columns, write operations may experience noticeable slowdowns. Therefore, it’s crucial to balance the number of indexes to avoid negatively affecting the performance of write-heavy workloads. - Ignoring cardinality:
The effectiveness of composite indexes depends heavily on the cardinality of the indexed columns, which refers to unique values. High-cardinality columns are ideal for creating efficient indexes that significantly improve query performance and retrieval speed. However, if the indexed columns have low cardinality, the index may not provide substantial benefits, potentially leading to wasted resources. As a result, it’s important to assess column cardinality before deciding to implement composite indexes for optimal performance. - Neglecting to maintain indexes:
Over time, as data is inserted, updated, and deleted, indexes may become fragmented, resulting in a loss of efficiency. Regular maintenance tasks, such as rebuilding or reindexing, are essential to maintain index performance and prevent query degradation. By performing routine index optimization, you ensure that queries continue to run efficiently, supporting overall database performance. Consequently, neglecting index maintenance can lead to significant slowdowns and resource waste, undermining system responsiveness.
Conclusion:
In conclusion, composite indexes in PostgreSQL provide substantial benefits by optimizing performance, particularly for complex queries with multiple columns. They create a unique data structure that allows PostgreSQL to bypass full table scans, ensuring faster row retrieval. However, selecting the right columns for indexing, maintaining the correct order, and considering column cardinality are essential for maximizing efficiency. Neglecting index maintenance or over-indexing can lead to slower operations, ultimately degrading overall system performance and reducing query speed.
For more in-depth insights and best practices, refer to expert PostgreSQL blogs on minervadb.com. These blogs provide a wealth of knowledge on not only composite indexes but also a wide variety of other PostgreSQL topics. Whether you’re a novice or a seasoned database administrator, these resources can help you leverage the full potential of PostgreSQL in your database operations.


