MongoDB Sharding: A Comprehensive Guide to Horizontal Database Scaling
Introduction to Database Sharding
Modern applications face unprecedented challenges when dealing with massive datasets and high-throughput operations. As data volumes grow exponentially, traditional single-server database architectures quickly reach their limits. MongoDB sharding emerges as a powerful solution for distributing data across multiple machines, enabling applications to scale horizontally and handle enterprise-level workloads efficiently.
Sharding represents a fundamental shift from vertical scaling (adding more power to existing servers) to horizontal scaling (distributing load across multiple servers). This approach not only addresses storage limitations but also provides enhanced performance, availability, and cost-effectiveness for large-scale database deployments.
Understanding Vertical vs. Horizontal Scaling
Vertical Scaling Limitations
Vertical scaling involves enhancing a single server’s capacity through:
- Upgrading CPU processing power
- Increasing RAM capacity
- Expanding storage space
However, this approach faces several constraints:
- Hardware limitations: Physical limits on available technology
- Cost escalation: Exponentially increasing costs for high-end hardware
- Single point of failure: Entire system depends on one machine
- Cloud provider restrictions: Hard ceilings on available configurations
Horizontal Scaling Advantages
Horizontal scaling distributes system load across multiple servers, offering:
- Unlimited scalability: Add servers as needed
- Cost efficiency: Use commodity hardware instead of expensive high-end machines
- Fault tolerance: System continues operating even if individual servers fail
- Load distribution: Each server handles a subset of the total workload
MongoDB’s sharding implementation provides robust horizontal scaling capabilities while maintaining data consistency and query performance.
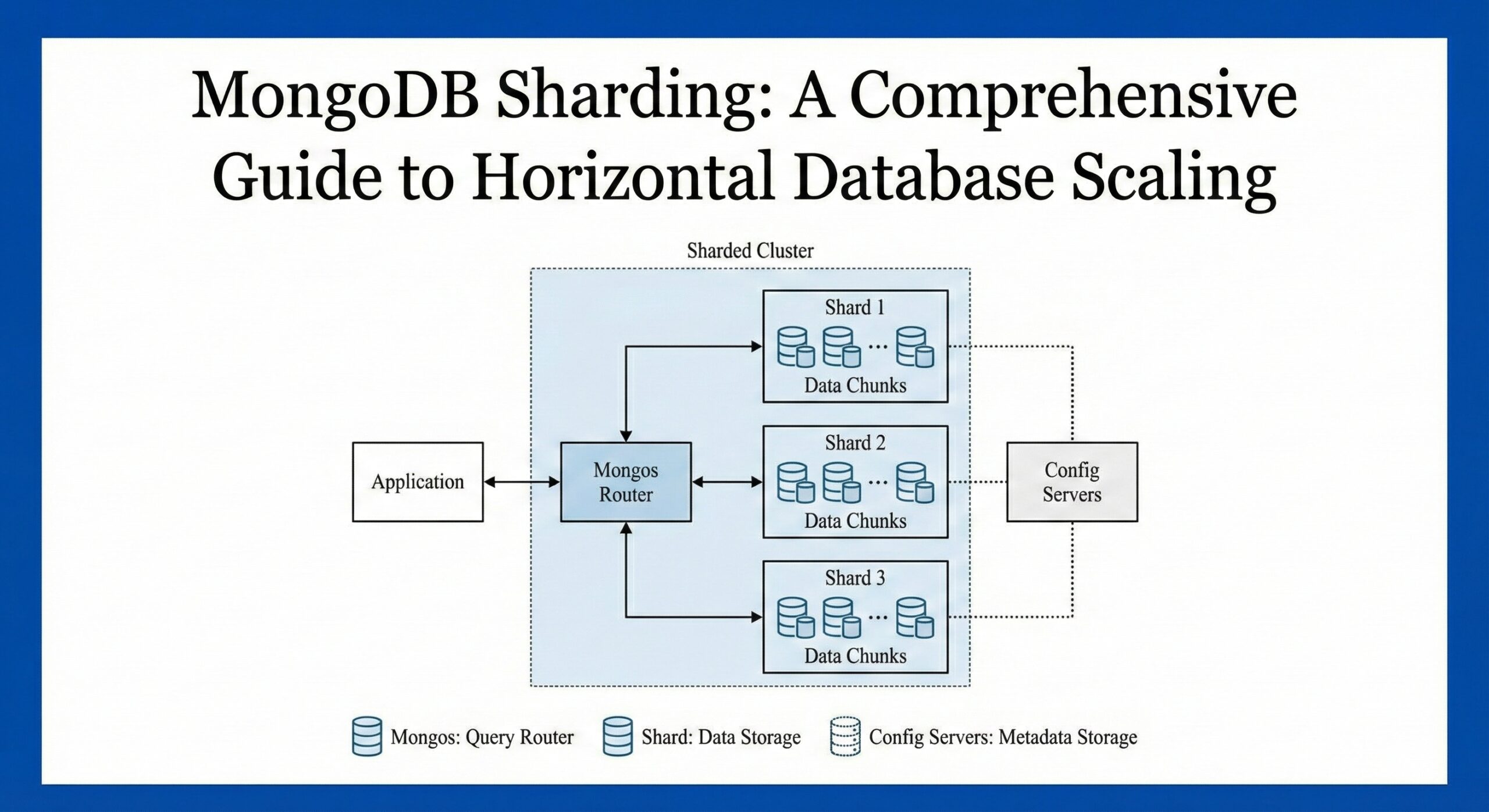
Core Components of MongoDB Sharded Clusters
A MongoDB sharded cluster consists of three essential components working together to provide seamless data distribution and query routing.
Shards: Data Storage Units
Each shard contains a subset of the total dataset and must be deployed as a replica set for high availability. Key characteristics include:
- Data isolation: Each shard stores distinct portions of the collection
- Replica set requirement: Ensures data redundancy and fault tolerance
- Independent operation: Shards can process queries independently
- Scalable storage: Additional shards increase total cluster capacity
Mongos Query Routers
The mongos process acts as an intelligent query router, providing:
- Client interface: Applications connect to mongos, not individual shards
- Query distribution: Routes queries to appropriate shards based on shard keys
- Result aggregation: Combines results from multiple shards
- Load balancing: Distributes client connections across available resources
Config Servers: Metadata Management
Config servers store critical cluster metadata and must be deployed as a replica set (CSRS):
- Cluster configuration: Maintains shard topology information
- Chunk metadata: Tracks data distribution across shards
- Balancer coordination: Supports automatic data redistribution
- High availability: Replica set deployment ensures metadata resilience
Shard Keys: The Foundation of Data Distribution
The shard key represents the most critical decision in sharding implementation, directly impacting performance, scalability, and query efficiency.
Shard Key Selection Principles
Effective shard keys should exhibit:
- High cardinality: Many distinct values for even distribution
- Query alignment: Frequently used in application queries
- Non-monotonic values: Avoid hotspots from sequential inserts
- Immutable nature: Values shouldn’t change frequently
Shard Key Flexibility
MongoDB provides several options for shard key management:
- Resharding: Change collection shard keys (MongoDB 5.0+)
- Shard key refinement: Add suffix fields to existing keys
- Value updates: Modify document shard key values (except _id field)
- Missing field handling: Treats missing shard key fields as null values
Index Requirements
Sharding requires proper indexing:
- Populated collections: Must have index starting with shard key
- Empty collections: MongoDB creates supporting index automatically
- Compound keys: Index must include shard key prefix
- Performance impact: Index choice affects query routing efficiency
Data Partitioning and Chunk Management
MongoDB implements sophisticated data partitioning through its chunk-based architecture.
Chunk-Based Distribution
Data partitioning occurs through chunks with specific characteristics:
- Range definition: Each chunk has inclusive lower and exclusive upper bounds
- Shard key basis: Chunk ranges based on shard key values
- Automatic management: System handles chunk creation and maintenance
- Migration support: Chunks move between shards for load balancing
Balancer Operations
The background balancer ensures optimal data distribution:
- Automatic migration: Moves chunks between shards as needed
- Load monitoring: Tracks shard utilization and data distribution
- Minimal disruption: Migrations occur without service interruption
- Configurable behavior: Administrators can control balancer operations
Sharding Strategies: Hashed vs. Ranged
MongoDB supports two primary sharding strategies, each optimized for different use cases and data patterns.
Hashed Sharding
Hashed sharding computes hash values of shard key fields for distribution:
Advantages:
- Even distribution: Hash function ensures uniform data spread
- Monotonic key handling: Prevents hotspots from sequential values
- Automatic computation: MongoDB handles hash calculations transparently
- Predictable performance: Consistent distribution patterns
Limitations:
- Range query inefficiency: Queries spanning ranges require broadcast operations
- Reduced targeting: Less efficient for range-based queries
- Hash overhead: Additional computation for key processing
Ranged Sharding
Ranged sharding distributes data based on actual shard key values:
Advantages:
- Query efficiency: Range queries can target specific shards
- Natural ordering: Maintains logical data relationships
- Targeted operations: Efficient routing for range-based queries
- Intuitive distribution: Data organization follows business logic
Considerations:
- Hotspot risk: Poor key selection can create uneven distribution
- Monotonic challenges: Sequential keys may overload single shards
- Careful planning: Requires thorough shard key analysis
Zone Sharding for Data Locality
Zones provide advanced control over data placement, particularly valuable for geographically distributed deployments.
Zone Configuration
Zone implementation involves:
- Shard key ranges: Define data ranges for each zone
- Shard association: Assign shards to specific zones
- Migration control: Balancer respects zone boundaries
- Multi-zone support: Shards can belong to multiple zones
Use Cases for Zones
Common zone applications include:
- Geographic distribution: Keep data close to users
- Compliance requirements: Maintain data sovereignty
- Hardware optimization: Match workloads to appropriate hardware
- Cost management: Use different storage tiers based on data importance
Zone Planning Considerations
Effective zone implementation requires:
- Shard key compatibility: Zone ranges must use shard key fields
- Compound key support: Ranges must include shard key prefix
- Future flexibility: Consider potential zone modifications
- Pre-sharding setup: Configure zones before sharding for optimal performance
Query Routing and Performance Optimization
Understanding query routing patterns is crucial for optimal sharded cluster performance.
Targeted Operations
Queries including shard keys enable efficient routing:
- Single shard targeting: Queries route to specific shards
- Reduced network overhead: Minimal cross-shard communication
- Improved performance: Faster query execution
- Resource efficiency: Lower CPU and memory usage
Broadcast Operations
Queries without shard keys require cluster-wide operations:
- All-shard querying: mongos queries every shard
- Scatter-gather pattern: Results collected from all shards
- Performance impact: Longer execution times
- Resource intensive: Higher network and processing overhead
Query Optimization Strategies
Optimize sharded cluster queries through:
- Shard key inclusion: Design queries to include shard key fields
- Index optimization: Create appropriate indexes on each shard
- Query pattern analysis: Monitor and optimize common query patterns
- Application design: Structure applications for efficient data access
Advanced Features and Integrations
MongoDB sharding integrates seamlessly with advanced database features, providing enterprise-grade functionality.
Change Streams Support
Change streams work effectively in sharded environments:
- Real-time monitoring: Track data changes across all shards
- Application integration: Subscribe to collection-level changes
- Simplified implementation: No need for complex oplog tailing
- Scalable notifications: Handle high-volume change events
Distributed Transactions
Multi-document transactions span sharded clusters:
- ACID compliance: Maintain transaction guarantees across shards
- Cross-shard operations: Transactions can modify multiple shards
- Consistency models: Support various read concern levels
- Performance considerations: Understand transaction overhead
Aggregation Pipeline Optimization
Sharded clusters optimize aggregation operations:
- Pipeline distribution: Stages execute on appropriate shards
- Result merging: Efficient combination of shard results
- Performance tuning: Optimize pipelines for sharded environments
- Resource utilization: Balance processing across cluster nodes
Operational Considerations and Best Practices
Successful sharded cluster deployment requires careful planning and ongoing management.
Infrastructure Requirements
Sharded clusters demand robust infrastructure:
- Network reliability: High-bandwidth, low-latency connections
- Hardware planning: Appropriate sizing for shards and config servers
- Monitoring systems: Comprehensive cluster health monitoring
- Backup strategies: Coordinated backup across all components
Security Considerations
Implement comprehensive security measures:
- Authentication: Secure access to all cluster components
- Authorization: Role-based access control across shards
- Network security: Encrypted communication between components
- Audit logging: Track access and modifications
Maintenance and Monitoring
Ongoing cluster management includes:
- Performance monitoring: Track query patterns and resource usage
- Capacity planning: Anticipate growth and scaling needs
- Balancer management: Monitor and tune data distribution
- Version upgrades: Coordinate updates across cluster components
Conclusion
MongoDB sharding provides a robust foundation for scaling modern applications beyond single-server limitations. By distributing data across multiple machines, organizations can achieve virtually unlimited scalability while maintaining high performance and availability.
Success with sharded clusters requires careful planning, particularly in shard key selection and cluster architecture design. The choice between hashed and ranged sharding strategies should align with application query patterns and data characteristics. Advanced features like zones, change streams, and distributed transactions extend sharding capabilities for complex enterprise requirements.
As data volumes continue growing, MongoDB sharding remains an essential technology for organizations requiring scalable, high-performance database solutions. Proper implementation and management of sharded clusters enable applications to handle massive datasets and high-throughput operations while maintaining the flexibility to adapt to changing business requirements.
Further Reading:
- Mastering PostgreSQL Replication: A Complete Guide for Database Professionals
- Comprehensive Guide to MySQL to Amazon Redshift Data Replication Using Tungsten Replicator
- Mastering PostgreSQL Log Management: A Comprehensive Guide
- Useful CQLSH Commands for Everyday Use
- Transparent Data Encryption (TDE): The Ultimate Guide
- MongoDB Sharding
- MongoDB Consulting
- MongoDB Support


